


















































































































































































































































































































































































visit
214 Stories To Learn About Computer Vision by@learn
239 reads
214 Stories To Learn About Computer Vision
by Learn RepoJanuary 28th, 2024
Too Long; Didn't Read
Learn everything you need to know about Computer Vision via these 214 free HackerNoon stories.People Mentioned
Let's learn about Computer Vision via these 214 free stories. They are ordered by most time reading created on HackerNoon. Visit the to find the most read stories about any technology.
Harnessing Artificial Intelligence to teach computers and systems how to obtain meaningful information from Images. We look at tricks of the trade, evolving techniques and so forth.1. The Problem(s) With Amazon GO
2. How to Make a Gaming Bot that Beats Human Using Python and OpenCV
Learn to create a Python bot that plays an online game and achieves the highest score in the leaderboard beating humans.
3. What is R-CNN? - Summarizing Regions with CNN Features
This R-CNN Summary breaks down the research into Object Detection and Image Segmentation done to develop Computer Vision and improve ML learning speeds.
4. 10 Biggest Image Datasets for Computer Vision
Data is very important in building computer vision models and these are the 10 Biggest Datasets for Computer Vision.
5. Top 20 Image Datasets for Machine Learning and Computer Vision
Computer vision enables computers to understand the content of images and videos. The goal in computer vision is to automate tasks that the human visual system can do.
6. Why Deep Learning is not Enough for Video Content Analysis
Deep Learning gets a ton of traction from technology enthusiasts. But can it match the effectiveness standards that the public hold it to?
7. 10 Must-Try Open Source Tools for Machine Learning
Machine learning is the future. But will machines ever extinct humans?
8. I Chose Emergency Healthcare After Losing My Friends in a Terrorist Attack: CEO Xena Vision
Next Generation Emergency Recognition Technology of Brave New World! There is nothing more precious than having a second chance to live!
9. How Do Deep Neural Networks Work?
Every day we are facing AI and neural network in some ways: from common phone use through face detection, speech or image recognition to more sophisticated — self-driving cars, gene-disease predictions, etc. We think it is time to finally sort out what AI consists of, what neural network is and how it works.
10. The Hunt for Data: Creating a Computer Vision Dataset for Road Safety
In this article, I would like to share my own experience of developing a smart camera for cyclists with an advanced computer vision algorithm
11. Enabling Business Operations With Computer Vision: Interview With Tanay Dixit, CPO of Wobot.ai
HackerNoon good company with Tanay Dixit, co-founder, and CPO of Wobot.ai.
12. Introduction to My Computer Vision Project: ArtLine
ArtLine is based on Deep-Learning algorithms that will take your image input and transform it into a line art. I started this project as fun project but was excited to see how it turned out. The results from this model are so good that it is almost equal to the line art by an artist.
13. Deep Learning, Protein Folding Algorithms, Computer Vision, Math, and AI Research #Noonies2021
Emil Bogomolov has been nominated as the Hackernoon Contributor of the Year - Computer Vision.
14. Stem Cells and Wafer Thin 3D Printing: How Cosmetic Dentistry Will Rid Itself of Invasive Procedure
Veneers have become one of the biggest crazes in cosmetic dentistry, with celebrity adopters inspiring many to take the procedure in the pursuit of the perfect smile.
15. Image Processing Algorithms: Adjusting Contrast And Image Brightness
Let's take a look at the common approaches for implementing image contrast adjustments. We'll go over histogram stretching and histogram equalization.
16. How to Get Better Datasets for Your Computer Vision Task
Here are some tips to improve your dataset collection
17. The Future of Image Recognition and Computer Vision
Fifty years ago, computers couldn't do much other than mathematical calculations - they just weren't powerful enough. Today, they can do just about anything. Even your mobile phone is powerful enough to process video in real-time to track objects. I'm talking about computer vision, and we've only begun to find applications for this technology.
18. How Two College Students Are Solving The Problem Of Food Waste
Paran Sonthalia, DeWaste CEO and a college student, shares his experience of what it's like working on a food waste solution in the middle of the pandemic.
19. What is Automated Number Plate Recognition (ANPR)?
In this guide, we'll go over everything you need to know about Automatic Number Plate Recognition (ANPR) solutions, such as how they work, how they're used etc
20. How to Implement Gaussian Blurs
A Gaussian blur is applied by convolving the image with a Gaussian function. We’ll take the Gaussian function and we’ll generate an n x m matrix.
21. Optical Character Recognition Technology for Business Owners
How to use Machine learning, Deep learning and Computer Vision for building Optical Character Recognition (OCR) solution for text recognition.
22. Data Set and Data Augmentation for Face Detection and Recognition
When it comes to building an Artificially Intelligent (AI) application, your approach must be data first, not application first.
23. Rare Datasets for Computer Vision Every Machine Learning Expert Must Work With
Have you ever being in a situation to guess another person’s age? Well May be YES!! How about playing games like finding things in minimum time? or about finding the written character where your doctor wrote in the prescription when you are sick?
24. Automotive Companies only Access 5% of their Vehicle Data
Only 5% of autonomous driving sensor data is used for product development today. Better data infrastructure holds the keys to progress.
25. Driving Impact in the U.S. Property Insurance Industry with Engineer Sathish Kumar
Automation hits the US property insurance industry. Inspecting a property will soon be done with nothing but a few photos.
26. How Computer Vision Turns Images Into Arrays
How Images are turned into arrays in Computer Vision
27. CLIP: An Innovative Aqueduct Between Computer Vision and NLP
A rudimentary article describing the concept behind the "CLIP" algorithm in deep learning, its approach, implementation, scope & limitations.
28. Kinetics Dataset - Training and Evaluating Models for Video Classification
A guide to using the open-source tool FiftyOne to download the Kinetics dataset and evaluate video understanding models
29. Small Object Detection in Computer Vision: The Patch-Based Approach
How to carry out small object detection with Computer Vision - An example of finding lost people in a forest.
30. The Shortcomings of Computer-controlled Robots
Computer-controlled robots are monotonous. They are mostly able to perform a sequence of processing operations that is fixed by the equipment configuration and
31. 70-Page Report on the COCO Dataset and Object Detection [Part 1]
Quickly find common resources and/or assets for a given dataset and a specific task, in this case dataset=COCO, task=object detection
32. The AI Monthly Top 3 Papers of October 2021
The 3 most interesting research papers of October 2021!
33. 10 Security Products to Protect Your Smart Home
In your smart home, you must have equipped lots of smart devices that streamline your life. At first glance, it seems attractive that your smart home provides tons of benefits. But, have you thought about its security? Without securing your smart home, it is not possible to attain its benefits for the long-term. Therefore, you need to invest in certain decent quality security products that can protect your smart home. They are capable to save your time and money. They only focus on providing exceptional security to your smart home. Let’s take a look at these useful security products:
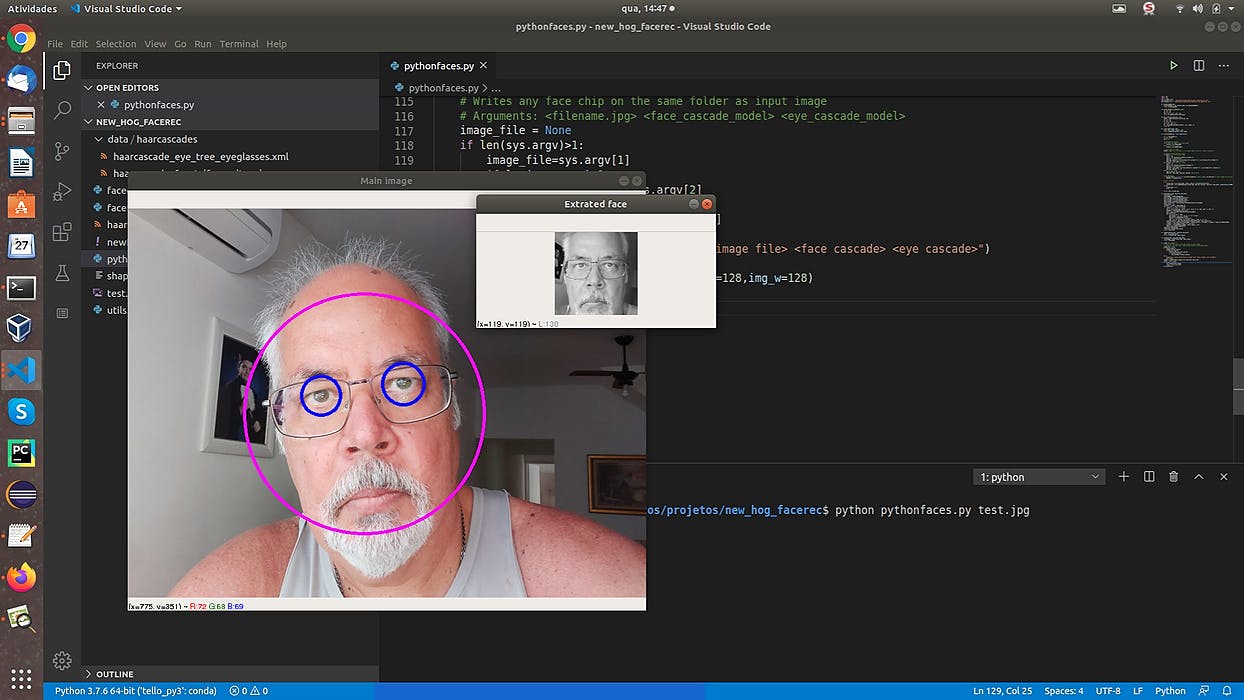
34. A Python Library for Face Detection and Extraction with OpenCV Using HOG/Neural Network
Many people, including me, use a combination of libraries to work on the images, such as: OpenCV itself, Dlib, Pillow etc. But this is a very confusing and problematic process. Dlib installation, for example, can be extremely complex and frustrating.
35. EagleEye Introduction: Outdoor Video Surveillance Analytics & Facial Recognition Software
I did lot of research as well developed this software system using various Machine learning methods. I have spent around one year on this project to implement this technology for a local state government. Unfortunately It didn't materialised. But I am interested in contributing to open source community. It can accurately identify, segment, recognise objects in video feeds (92 types of semantic attributes of a person in video feeds). The most interesting part is the accuracy of our facial recognition of wild shots from street cctv cameras.
36. On Food Waste and Relevance of Privacy: Noonies Nominee Paran Sonthalia
Noonies 2021 nominee, Paran Sonthalia, is still a Berkley student. But that didn't stop him on the mission of reducing food waste. Hear more from him here.
37. Things You Need to Know Before Installing a Facial Recognition System
With the help of a facial recognition system, federal agents could capture a person suspected of illegal activity.
38. 10 Best Image Classification Datasets for ML Projects
To help you build object recognition models, scene recognition models, and more, we’ve compiled a list of the best image classification datasets. These datasets vary in scope and magnitude and can suit a variety of use cases. Furthermore, the datasets have been divided into the following categories: medical imaging, agriculture & scene recognition, and others.
39. How to Turn Mockups Into Videos Instantly with This New AI Model
GEN-1 is able to take a video and apply a completely different style onto it, just like that…
40. How to Build Your Own Automated Self Checkout Service
Brick-n-mortar retailers, learn how to implement an AI-powered autonomous checkout from smart vending machines and kiosks to full store automation.
41. How Can Enterprises Utilize Edge Computer Vision?
Business applications of computer vision technology for Enterprises, retail analytics, edge computing, intrusion detection and monitoring
42. PixelLib: Image and Video Segmentation [Maybe just a Quick One]
PIxelLib: Image and video segmentation with just a few lines of code.
43. How to Use Model Playground for No-Code Model Building
We're launching Model Playground, a model-building product where you can train AI models without writing any code yourself. Still, with you in complete control.
44. Major Image Recognition And Annotation Trends
Image recognition and annotation technologies are evolving. New techniques that allow you to solve a wide variety of tasks quickly appear. We are happy to present five major trends in image recognition and annotation.
45. Computer Vision Is Solving Problems That Weren't Even On Our List
Replicating human interaction and behavior is what artificial intelligence has always been about. In recent times, the peak of technology has well and truly surpassed what was initially thought possible, with countless examples of the prolific nature of AI and other technologies solving problems around the world.
46. 5 Intriguing Applications of Computer Vision in Smart Cities
Computer vision will radically change smart technology. Here are five ways it's already impacting smart cities.
47. Machine Vision Technology in Production: Use Cases
We at TaQadam produce different computer vision technologies. In this blog we tell about using machine vision in production for some common use-cases.
48. Detecting Humans in Smart Homes with Computer Vision
Learn more about OpenCV, how you can use it to identify and track people in real-time, and what challenges you can meet.
49. How to Build an Image Search Engine to Find Similar Images
After reading this article, you will be able to create a search engine for similar images for your objective from scratch
50. What is Automatic Number Plate Recognition (ANPR) System
Computer vision is a multidisciplinary field of study that teaches computers to interpret images and videos just like humans. The most challenging area in computer vision is Object Detection which deals in recognizing multiple objects in an image or video and classifying them accordingly.
51. How Synthetic Data is Accelerating Computer Vision
In the spring of 1993, a Harvard statistics professor named Donald Rubin sat down to write a paper. Rubin’s paper would go on to change the way that artificial intelligence is researched and practiced, but its stated goal was more modest: analyze data from the 1990 U.S. census, while preserving the anonymity of its respondents.
52. 5 Benefits of Interactive Whiteboards in Business
Interactive whiteboards are the evolution of classroom whiteboards and non-electronic whiteboards in the workplace. Their existence is not always new, but recently the benefits of their meetings and presentations have become the forefront of modern business.
53. Develop XR with Oracle Ep 3: Computer Vision AI, ML, and the Metaverse
This is the third piece in a series on developing XR applications and experiences using Oracle and focuses on XR applications of computer vision AI and ML and i
54. How to Create Realistic Slow Motion Videos With AI
TimeLens can understand the movement of the particles in-between the frames of a video to reconstruct what really happened at a speed even our eyes cannot see.
55. Build a Custom-Trained Object Detection Model With 5 Lines of Code
These days, machine learning and computer vision are all the craze. We’ve all seen the news about self-driving cars and facial recognition and probably imagined how cool it’d be to build our own computer vision models. However, it’s not always easy to break into the field, especially without a strong math background. Libraries like PyTorch and TensorFlow can be tedious to learn if all you want to do is experiment with something small.
56. Harnessing Metaverse Technology to Build Your Brand Application
Let’s talk about what technologies are used in metaverse development and how businesses can create their own metaverse applications.
57. How You Can Make a Naruto Hand Signs Classifier using Deep Learning
Introduction: (How I got the idea and the process of how the dataset was developed)
58. ICCV 2019: Papers that indicate the future of computer vision (Satellites to 3D reconstruction)
If you couldn’t make it to ICCV 2019 due to visa issues, no worries. Below is a list of top papers everyone is talking about!
59. Yet Another Lightning Hydra Template for ML Experiments
Flexible and scalable template based on PyTorch Lightning and Hydra. Efficient workflow and reproducibility for rapid ML experiments.
60. How We Automate 80-100% of Media Workflows with Cognitive Computing
Here's how you can use cognitive computing to automate media & entertainment workflows and stramline video production.
61. An Intro to Edge Computer Vision: Technologies, Applications, Use Cases and Key Models
introduction to computer vision technologies, applications, use cases and key models.
62. How to Create Hidden Secret Messages in Images using Python
Today, we are gonna learn how to apply coding skills to cryptography, by performing image-based stenography which hiding involves secret messages in an image.
Stenography has been used for quite a while. Since World War II, it was heavily used for communication among allies so as to prevent the info being captured by enemies63. Image Annotation Types For Computer Vision And Its Use Cases
There are many types of image annotations for computer vision out there, and each one of these annotation techniques has different applications.
64. A beginner’s guide to Computer Vision in Retail
Anyone with a wet finger in the air will by now have heard of the “retail apocalypse” sweeping through the developed world’s malls. “People aren’t spending in stores anymore”, your quarter-informed uncle complains, before moaning that youths are too busy Instagramming their avocado brunches to burn crosses on people’s lawns. Indeed, the old retailing models aren’t working as well as they used to. The fact that they were terrible models to start with probably had something to do with it.
65. Optimize Model Training with a Data Streaming Client
Were you ever annoyed when you had to pull a massive dataset (versioned using DVC) before training your model?
66. Stable Diffusion, Unstable Me: Text-to-image Generation
Text to image generation is not a new idea. What if, you feed <your name> to a state-of-the-art image generation model?
67. 5 Companies Developing Computer Vision Technology in 2020
Computer vision technology is the poster child of artificial intelligence. It is the sector of the industry that gets the most media attention because of the tools and benefits the technology can provide. From autonomous vehicles and drones to cancer detection and augmented reality, technologies that once only existed in science fiction are now at our doorstep.
68. Multiclass Classification with Keras
In the article the author describes the common pipelane of multilass classification solution using keras
69. Image to Image Translation and Segmentation Tutorial
In this article and the following, we will take a close look at two computer vision subfields: Image Segmentation and Image Super-Resolution. Two very fascinating fields.
70. Thinking of Buying Stereo Cameras? Read This Product Comparison.
To pique your curiosity about robotics, we bring you the product review you were waiting for, a comparison between real sense cameras, one of the main hardware pieces used in all types of robots.
71. How Computer Vision is Taking Over Manufacturing and Retail
AI continues to take over almost every industry ripe with data. Computer vision expands AI’s capabilities, allowing machines to not only process data, but also gather information on their own, which unlocks completely new opportunities for businesses. According to research by ABI, total shipments of computer vision sensors and cameras will reach 16.9 million by 2025.
72. Hybrid AI for Personal Medicine
Neural networks gave us a powerful and cheap-to-use tool for solving problems of forecasting, computer vision, and text analysis. However, at the same time, they brought the problem of inaccuracy, which is presented as the “norm” and “black box” for deep networks, the derivation of which is difficult to understand and improve.
73. "You may also like..." How To Use Convolutional Neural Networks
How to use a Convolutional Neural Network to suggest visually similar products, just like Amazon or Netflix use to keep you coming back for more.
74. How Machine Generated Virtual Assistants can 10x Your Productivity in 2022
AI assistant technology is in many ways similar to a traditional chatbot but integrates next-generation machine learning, AR/VR and data science.
75. Introducing theHolopix50k Dataset for Image Super-Resolution
Depth estimation and stereo image super-resolution are well-known tasks in the field of computer vision. To help researchers get high-quality training data for these tasks, industry-leading lightfield hardware provider Leia Inc. used their social media app, Holopix™, to create Holopix50k, the world’s largest “in-the-wild” stereo image dataset.
76. The Machines Are Watching You: Top 10 Computer Vision Applications
Innovative Computer vision applications can be found in every industry these days. Here is the list of top 10 CV applications
77. Ten Trending Academic Papers on the Future of Computer Vision
If you couldn’t make it to CVPR 2019, no worries. Below is a list of top 10 papers everyone was talking about, covering DeepFakes, Facial Recognition, Reconstruction, & more.
78. How to Easily Deploy ML Models to Production
One of the known truths of the Machine Learning(ML) world is that it takes a lot longer to deploy ML models to production than to develop it.¹
79. On Investing In People Over Ideas or Apps with AI YouTuber Louis Bouchard
An interview with Louis, an AI YouTuber known as What’s AI, and a research scientist at designstripe.
80. Deploy Computer Vision Models with Triton Inference Server
There are a lot of Machine Learning courses, and we are pretty good at modeling and improving our accuracy or other metrics.
81. Robotic Vision: Connecting Asus Xtion Live Depth Camera to Raspberry Pi
An important part of the robot is its eyes and perception of the outside world. For this purpose, the Depth Camera is well suited.
82. Reviewing “OpenPose - Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields”
OpenPose is an open-source multi-person detection system supporting the body, hand, foot, and facial key points. The system uses a multi-stage CNN.
83. Deep Neural Networks Are Addressing Challenges in Computer Vision
Computer vision techniques are developed to enable computers to “see” and draw analysis from digital images or streaming videos.
84. Autonomous Driving Lidar Perception Stack with PCL: An Algorithmic Implementation
C++ pipeline for LiDAR-based autonomous driving.
85. How IBM's Stance on Face Recognition Will Affect the AI Industry
In a letter to congress sent on June 8th, IBM’s CEO Arvind Krishna made a bold statement regarding the company’s policy toward facial recognition. “IBM no longer offers general purpose IBM facial recognition or analysis software,” says Krishna.
86. 3 Common Types of 3D Sensors: Stereo, Structured Light, and ToF
Over the past decade, 3D sensors have emerged to become one of the most versatile and ubiquitous types of sensor used in robotics.
87. Using Sparse R-CNN As A Detection Model
Today, we are going to discuss a method proposed by researchers from four institutions one of which is ByteDance AI Lab (known for their TikTok App).
88. Top 3 Advantages of Video Annotation
The 3 Major Advantages of Annotating Video with the Innotescus Video Annotation Canvas.
89. Even Disney is Investing in AI: A Look at Face Re-Aging for Visual Effects
Whether it be for fun in a Snapchat filter, for a movie, or even to remove a few riddles, we all have a utility in mind for being able to change our age in a picture.
90. Facial Recognition Comparison with Java and C ++ using HOG
HOG - Histogram of Oriented Gradients (histogram of oriented gradients) is an image descriptor format, capable of summarizing the main characteristics of an image, such as faces for example, allowing comparison with similar images.
91. How to Add Training Data to Build a More Generic ML Model
You can easily make changes to your dataset using DVC to handle data versioning. This will let you extend your models to handle more generic data.
92. How to Classify Animal Images via a Convolutional Neural Network
Identifying patterns and extracting features on images using deep learning models
93. Machine Learning for the ISIC Cancer Classification Challenge #2: Deep learning on AWS
(The full list of lesion types types to classify in the ISIC dataset. We’ll be focusing on Melanoma vs. non-Melanoma)
94. 5 Reasons Our Cities Are Not Full of Autonomously Flying Drones (Yet!)
We are slowly but surely moving towards a world where autonomous drones will play a major role. In this article, I will show you what stopes them today.
95. Top 15 Datasets for Autonomous Driving
A2D2, ApolloScape, and Berkeley DeepDrive are among the best autonomous driving datasets available today.
96. This AI Creates Videos From a Couple of Images
Researchers created a simple collection of photos and transformed them into a 3-dimensional model.
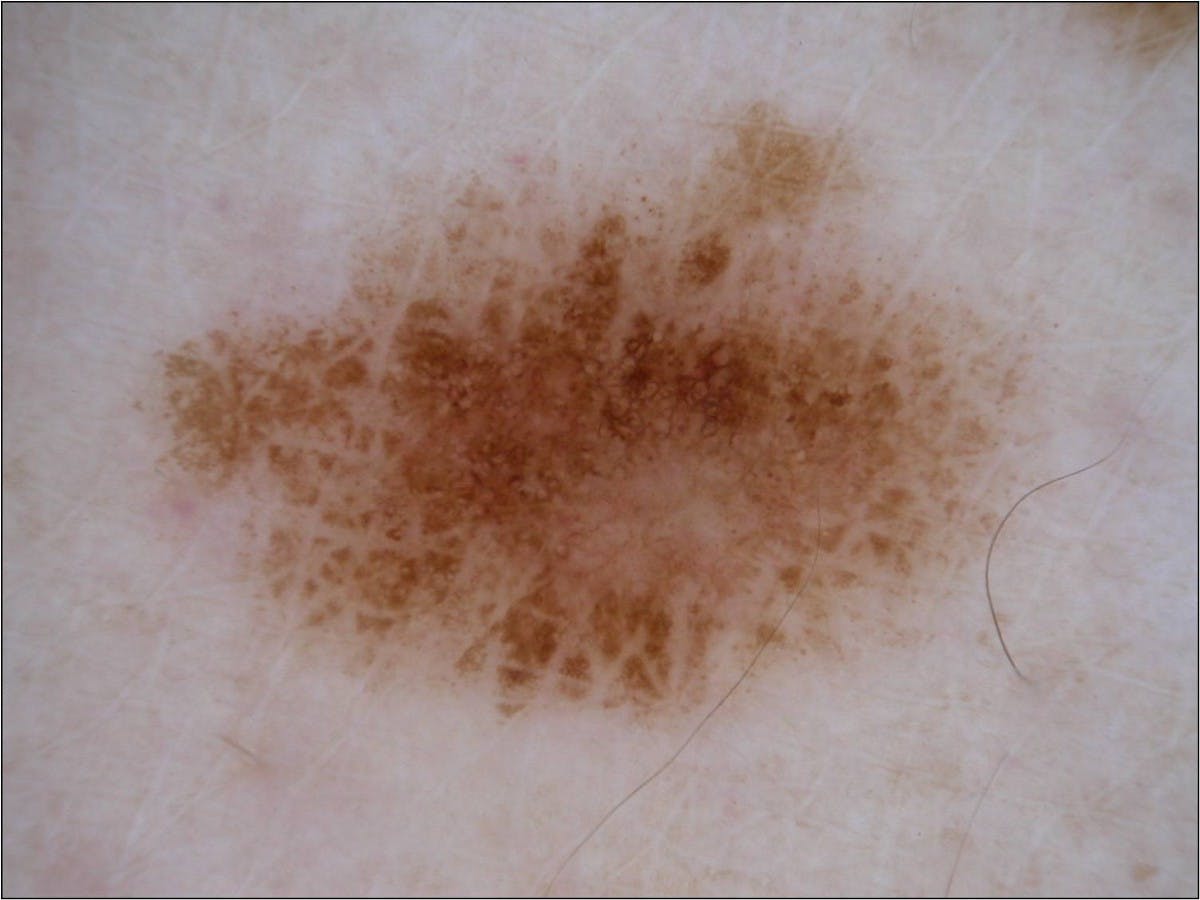
97. Machine Learning for ISIC Skin Cancer Classification Challenge
This is part 1 of my ISIC cancer classification series. You can find part 2 here.
98. AI in the Retail Industry: 10 Computer Vision Startups to Follow in 2021
AI-enhanced retail holds the promise to eliminate operational inefficiencies and provide shoppers with frictionless in-store experiences.
99. Artificial Intelligence Technology Trends That Matter for Business in 2022
Discover the top AI trends that are increasing in 2022 and will determine how companies can leverage the AI technology in the future.
100. We Built a Face and Mask Detection Web App for Google Chrome
Face and mask detection in browser using TensorFlow.js, openCV.js. Investigate results with different implementations.
101. Introductory Guide To Real-time Object Detection with Python
Researchers have been studying the possibilities of giving machines the ability to distinguish and identify objects through vision for years now. This particular domain, called Computer Vision or CV, has a wide range of modern-day applications.
102. Using Reinforcement Learning to Build a Self-Learning Grasping Robot
Tips and tricks to build an autonomous grasping Kuka robot
103. How AI from Driver Technologies Company Helps To Protect the Motorists
Across the world, more than 1.3 million people die in car accidents, and over 50 million people are seriously injured every year. That’s nearly 4,000 people each day. Drivers in developing nations are most at risk. Only 54% of the world’s motor vehicles are in developing countries, but 90% of the world’s fatal car accidents occur in those countries. Even within the wealthiest countries vehicle-related injury and death are directly correlated to personal and neighborhood incomes.
104. Optical Character Recognition Algorithms Can Redefine Business Processes
Entering data and moving it from one place to another is a time-consuming, repetitive task.
105. Use Cascade Models to Get Better Speed and Accuracy in Computer Vision Tasks
Great way to improve your Computer Vision models metrics
106. How We Implemented the Face-with-Mask Detection Web App for Chrome
How we implemented face and mask detection in the browser using JavaScript, Web Workers, TensorFlow.js, OpenCV.js.
107. OpenAI's New Model is Amazing! DALL·E 2 Explained Simply
Last year I shared DALL·E, an amazing model by OpenAI capable of generating images from a text input with incredible results. Now is time for his big brother, DALL·E 2. And you won’t believe the progress in a single year! DALL·E 2 is not only better at generating photorealistic images from text. The results are four times the resolution!
108. Imagic: AI Image Editing from Text Commands
This week’s paper may just be your next favorite model to date.
109. How Does DALL·E mini Work?
Dalle mini is amazing — and YOU can use it!
110. This AI Creates Realistic Animated Looping Videos from Static Images
This model takes a picture, understands which particles are supposed to be moving, and realistically animates them in an infinite loop!
111. How to Kalman Filter Your Way Out (Part 2: Updating Your Prediction)
Part II describes how to use Kalman filters to minimize uncertainty when using multi-sensor arrays
112. Visual Generative Modeling: Using GANsformers to Generate Scenes
They basically leverage transformers’ attention mechanism in the powerful StyleGAN2 architecture to make it even more powerful!
113. Computer Vision Is Fun To Play With
I work as a Software Engineer at Endtest.
114. Introducing Total Relighting by Google
In a new paper titled Total Relighting, a research team at Google presents a novel per-pixel lighting representation in a deep learning framework.
115. The Full Story behind Convolutional Neural Networks and the Math Behind it
Convolutional Neural Networks became really popular after 2010 because they outperformed any other network architecture on visual data, but the concept behind CNN is not new. In fact, it is very much inspired by the human visual system. In this article, I aim to explain in very details how researchers came up with the idea of CNN, how they are structured, how the math behind them works and what techniques are applied to improve their performance.
116. This AI Performs Seamless Video Manipulation Without Deep Learning or Datasets
New research by Niv Haim et al. allows us to perform infinite video manipulations without using deep learning or datasets.
117. How to Kalman Filter Your Way Out
Learn how to use Kalman filters to minimize uncertainty with multi-sensory arrays
118. DreamFusion: An AI that Generates 3D Models from Text
Here’s DreamFusion, a new Google Research model that can understand a sentence enough to generate a 3D model of it.
119. Can AI and Computer Vision Replace Human Intuition?
Computer vision now lives with us with exceptional AI capabilities. Learn how AI and computer vision is playing a key role in outsmarting human beings.
120. [Tutorial] Build a Gender Classifier for Live Webcam Stream using Tensorflow and OpenCV
Training a Neural Network from scratch suffers two main problems. First, a very large, classified input dataset is needed so that the Neural Network can learn the different features it needs for the classification.
121. How Deep Learning Can Help Quantify, Monitor, and Remove Marine Plastic: The DeepPlastic Way
Towards a generalized object detector capable of identifying and quantifying sub-surface plastic around the world
122. Style Transferring with TensorFlow
Style transfer is a computer vision-based technique combined with image processing. Learn about style transfer with Tensorflow, a prominent framework in AI & ML
123. How To Creat an Audible Object Detector [DIY Tutorial]
For people with vision problems.
124. Computer Vision Applications: The Development and Deployment Processes
‘Computer Vision’ (CV) refers to processing visual data as a human would with their eyes, so that we can make conclusions about what is in an image. Once we know what is in an image, we can make our application respond, much like a human would when processing visual data. This is what enables technology like self-driving cars.
125. 11 Torchvision Datasets for Computer Vision You Need to Know
With torchvision datasets, developers can train and test their machine learning models on a range of tasks, such as image classification and object detection.
126. 8 Companies Using Machine Learning in Cool Ways
When asked what advice he'd give to world leaders, Elon Musk replied, "Implement a protocol to control the development of Artificial Intelligence."
127. A Quick Guide to Image Processing in Computer Vision Using OpenCV
The image processing library which stands for Open-Source Computer Vision Library was invented by intel in 1999 and written in C/C++
128. IoT Can Help Control The COVID-19 Pandemic in 2021
The Internet of Things is a paradoxical technology: despite its simplicity, it can dramatically improve people’s daily lives and make businesses more profitable and less risky. Yet the majority of companies still hesitate when it comes to the implementation of IoT in business operations.
129. Fabio Manganiello on Home-Made Computer Vision, IoT, Automation, AI
Fabio Manganiello writes about solutions he's discovered while building a platform, library of plugins and an API to connect/manage any device and service through any backend, allowing users to easily set up any kind of automation. Fabio is based in Amsterdam, the Netherlands, and has been nominated for a 2020 #Noonie for exceptional contributions to the IoT tag category on Hacker Noon.
130. AI and Machine Learning for Manufacturing Industry: Use Cases
Artificial Intelligence(AI) has already proven to solve some of the complex problems across the wide array of industries like automobile, education, healthcare, e-commerce, agriculture etc. and yield greater productivity, smart solutions, improved security and care, business intelligence with the aid of predictive, prescriptive and descriptive analytics. So what can AI do for Manufacturing Industry?
131. 7 Real-World Applications of AI in Healthcare
132. 70-Page Report on the COCO Dataset and Object Detection [Part 3]
133. 8 Benefits of Computer Vision in the Security Industry
AI has revolutionized the physical security industry with computer vision. Here are eight of the most significant benefits.
134. Synthesizing Images of Marine Plastic Using Deep Convolutional Generative Adversarial Networks
A generative approach towards synthesizing images of marine plastic using DCGANs
135. What Makes "Good" Fashion Image Tagging
Fashion image tagging is infamously tedious for eCommerce. But, how can AI help create accurate tags--and go a step beyond in understanding fashion information?
136. A Self-supervised Attention Mechanism To Help With Dense Optical Flow Estimation
Multi-object Tracking using self-supervised deep learning
137. The Need for Privacy Protection in Computer Vision Applications
This article describes why privacy concerns should be top of mind while building or adopting computer vision based applications
138. NSFW Filter Introduction: Building a Safer Internet Using AI
Filtering out NSFW images with a web extension built using TensorFlow JS.
139. Building Real-Time Vehicle Detection System
From vehicle counting and smart parking systems to Autonomous Driving Assistant Systems, the demand for detecting cars, buses, and motorbikes is increasing and soon will be as common of an application as face detection.
And of course, they need to run real-time to be usable in most real-world applications, because who will rely on an Autonomous Driving Assistant Systems if it cannot detect cars in front of us while driving. In this post, I will show you how you can implement your own car detector using pre-trained models that are available for download: MobileNet SSD and Xailient Car Detector.140. How Does Facial Recognition Work with Face Masks? [Explained]
With the spread of COVID-19 wearing face masks became obligatory. At least for most of the population. This created a problem for the current identification systems. For example, Apple’s FaceID struggled to recognize faces with masks.
141. Understanding Convolution Neural Networks
142. Top 10 Computer Vision Papers of 2020
This is a video of the 10 most interesting research papers on computer vision in 2020.
143. Innovation Opportunities in Data, AI, AR, Robots, Biotech, More [Overview]
Digital Technology is everywhere and it is redefining how we live, communicate, and work. Most importantly, it accelerates how we innovate.
144. LensAI: Associative Advertising as An Inevitable Evil
"Association in psychology refers to a mental connection between concepts, events, or mental states that usually stems from specific experiences." [1] Once the associative link between events A and B has been built, the appearance of event A naturally entails the appearance of event B. [2]
145. How Machines See the World: 7 Use Cases of Object Detection
Object detection is a product of Computer Vision and is a very effective technique to precisely locate items of different shapes and sizes and label them.
146. Counting Objects by Estimating a Density Map With Convolutional Neural Networks
Introduction
147. Computer Vision Could Improve Health and Workplace Safety
Recent developments in the field of training Neural Networks (Deep Learning) and advanced algorithm training platforms like Google’s TensorFlow and hardware accelerators from Intel (OpenVino), Nvidia (TensorRT) etc., have empowered developers to train and optimize complex Neural Networks in small edge devices like Smart Phones or Single Board Computers.
148. Facial Recognition Benefits, Applications, and Issues Businesses Should Consider
Facial recognition is everywhere. What once started as an attribute specific to sci-fi movies is now a part of everyday life: we rely on facial recognition every time we unlock our phones, tag friends in a Facebook post, or go through customs.
149. Kannada-MNIST:A new handwritten digits dataset in ML town
TLDR:
150. The Human Cost of Amazon Sparrow: How Automation is Impacting Warehouse Workers
Amazon's new Sparrow robot aims to improve the efficiency of its order fulfillment centers, but workers worry about the potential job loss.
151. This AI Prevents Bad Hair Days
This AI can transfer your hair to see how it would look like before committing to the change.
152. Big Tech, "I Want To Tell You That I Love You"
Credit : Emmanuel Chaligné
153. How Data Selection Impacts Model Performance: An AMA with SiaSearch
SiaSearch is a Berlin-based AI startup on a mission to accelerate computer vision application development.
154. Image Annotation Business Models [Reviewed]
In the rise of robotics, computer vision and image processing cameras, image annotation comes as the first step to get the right AI training data for Deep Learning models. Whether you build an app to allow users to snap fashion items at the store as a new omni-channel sales or use machine vision installed at edge device at the industrial facility to monitor anomalies: it starts with training massive image data sets.
155. CVPR 2022 Best Paper Honorable Mention: Dual-Shutter Optical Vibration Sensing
TLDR: They reconstruct sound using cameras and a laser beam on any vibrating surface, allowing them to isolate music instruments, focus on a specific speaker, remove ambient noises, and many more amazing applications.Watch the video to learn more and hear some crazy results!
156. The Challenges of Running Computer Vision on the Edge
Artificial intelligence (AI) is the field of making computers able to act intelligently, to make decisions in real environments that will have favorable outcomes.
157. Introducing NVIDIA's EditGAN: Alter Images Instantly via Quick Sketches
EditGAN allows you to control any feature from quick drafts, and it will only edit what you want keeping the rest of the image the same!
158. What is Human Pose Estimation?
Part of the broader artificial intelligence and computer vision realms, human pose estimation (HPE) technology has been gradually making its presence seen in all kinds of software apps and hardware solutions. Still, human pose estimation seemed to be stuck at the edge, failing to cross into mainstream adoption.
159. How Neural Networks Hallucinate Missing Pixels for Image Inpainting
When a human sees an object, certain neurons in our brain’s visual cortex light up with activity, but when we take hallucinogenic drugs, these drugs overwhelm our serotonin receptors and lead to the distorted visual perception of colours and shapes. Similarly, deep neural networks that are modelled on structures in our brain, stores data in huge tables of numeric coefficients, which defy direct human comprehension. But when these neural network’s activation is overstimulated (virtual drugs), we get phenomenons like neural dreams and neural hallucinations. Dreams are the mental conjectures that are produced by our brain when the perceptual apparatus shuts down, whereas hallucinations are produced when this perceptual apparatus becomes hyperactive. In this blog, we will discuss how this phenomenon of hallucination in neural networks can be utilized to perform the task of image inpainting.
160. 5 Best Data Curation Tools for Computer Vision in 2021
In this article, we’ll dive into the importance of data curation for computer vision, as well as review the top data curation tools on the market.
161. Intro to Image Processing in Python with Pillow
Pillow is Python Imaging Library that is free and open-source an additional library for the Python programming language that adds support for opening, manipulating, and saving in a variety of extension.
162. 3D Articulated Shape Reconstruction from Videos
With LASR, you can generate 3D models of humans or animals moving using only a short video as input.
163. 10 Computer Vision Startups on Product Hunt with the Most Upvotes
From self-driving cars and facial recognition to AI surveillance and GANs, computer vision tech has been the poster child of the AI industry in recent years. With such a collaborative global data science community, the advancements have come both from research teams, big tech, and computer vision startups alike.
164. The State of AI in 2022: An End-of-Year Recap of the Machine Learning Industry
An 8-minute AI rewind with results and limitations of all the hottest AI models shared in 2022!
165. Top Tips For Competing in a Kaggle Competition
Hi, my name is Prashant Kikani and in this blog post, I share some tricks and tips to compete in Kaggle competitions and some code snippets which help in achieving results in limited resources. Here is my Kaggle profile.
166. Top Computer Vision Applications and Opportunities
Computer vision applications have become ever-present and can be found in every industry nowadays. In this article, we look deep at AI.
167. 7 Reasons Why Your Automation Efforts Are Failing Right Now
“Companies that failed to incorporate automation in their roadmap experienced a 25% drop in their customer retention,” concluded a survey by Gartner.
168. Mind Mapping, Creative Thinking, And The Augmented Reality (AR) Technologies Driving Them
Scientists have dedicated centuries to studying our brain, trying to understand how this super-powerful computer is wired, how it comprehends the world, testing the limits of its capabilities.
169. SDEdit Helps Regular People Do Complex Graphic Design Tasks
Say goodbye to complex GAN and transformer architectures for image generation. This new method can generate new images from any user-based inputs.
170. What is General Video Recognition?
We’ve seen AI generate text, then generate images and most recently even generate short videos
171. 70-Page Report on the COCO Dataset and Object Detection [Part 2]
This blog is part 1 of (and contains a link to) a 70+ page report was created to quickly find data resources and/or assets for a given dataset and a specific ta
172. Is Subjective Beauty Something We Can Model with AI?
This AI reads your brain to generate personally attractive faces. It generates images containing optimal values for personal attractive features.
173. New SOTA Image Captioning: ClipCap
We’ve seen AI generate images from other images using GANs. Then, there were models able to generate questionable images using text. In early 2021, DALL-E was published, beating all previous attempts to generate images from text input using CLIP, a model that links images with text as a guide. A very similar task called image captioning may sound really simple but is, in fact, just as complex. It is the ability of a machine to generate a natural description of an image.
174. Face Recognition On The Wall; Google's AutoML Edge Democratizes ML For All
Machine learning can be complex and overwhelming. Luckily Google is on its way to democratize machine learning by providing Google AutoML, a Google Cloud tool to handle all the complexity of machine learning for common use cases.
175. 3D Models at City Scale!
Last year we saw NeRF, NeRV, and other networks able to create 3D models and small scenes from images using artificial intelligence. Now, we are taking a small step and generating a bit more complex models: whole cities. Yes, you’ve heard that right, this week’s paper is about generating city-scale 3D scenes with high-quality details at any scale. It works from satellite view to ground-level with a single model. How amazing is that?! We went from one object that looked okay to a whole city in a year! What’s next!? I can’t even imagine.
176. Top 10 Computer Vision Papers of 2021: HackerNoon Edition
The 10 most interesting computer vision papers in 2021 with video demos, articles, code, and paper reference.
177. Python Tutorial: How to Perform Real Time Vehicle Detection
In this article, I will guide you on how to do real-time vehicle detection in python using the OpenCV library and trained cascade classifier in just a few lines of code.
178. The 2021 AI Rewind: HackerNoon Edition
A curated list of the latest breakthroughs in AI and Data Science by release date with a clear video explanation
179. How to Create Realistic Slow Motion Videos With AI
TimeLens can understand the movement of the particles in-between the frames of a video to reconstruct what really happened at a speed even our eyes cannot see.
180. PULSE: Photo Upsampling Makes Blurry Faces 60 Times Sharper
The new PULSE: Photo Upsampling algorithm transforms a blurry image into a high-resolution image.
181. TextStyleBrush Translates Text in Images While Emulating the Font
This new Facebook AI model can translate or edit the text in an image, while maintaining the same font and design as the original.
182. AI Rewind: A Year of Amazing Machine Learning Papers
A curated list of the latest breakthroughs in AI by release date with a clear video explanation, link to a more in-depth article, and code.
183. How the Retail Industry is Implementing Machine Learning and Deep Learning
Stores are changing. We see it happening before our eyes, even if we don’t always realize it. Little by little, they are becoming just one extra step in an increasingly complex customer journey. Thanks to digitalisation and retail automation, the store is no longer an end in itself, but a mean of serving the needs of the brand at large. The quality of the experience, a feeling of belonging and recognition, the comfort of the purchase… all these parameters now matter as much as sales per square meter, and must therefore submit themselves to the optimizations prescribed by Data Science and its “intelligent algorithms” (aka artificial Intelligence in the form of machine learning and deep learning).
184. Infinite Nature: Fly Into a 2D Image and Explore it as a Drone
The next step for view synthesis: Perpetual View Generation, where the goal is to take an image to fly into it and explore the landscape!
185. Efficient NeRFs for Real-Time Portrait Synthesis (RAD-NeRF)
We’ve heard of deepfakes, we’ve heard of NeRFs, and we’ve seen these kinds of applications allowing you to recreate someone’s face and pretty much make him say whatever you want.
186. How AI Can Spot Wildfires Faster Than Humans
Here's how artificial intelligence can be used to reduce fire detection time from an average of 40 minutes to less than five minutes!
187. What is the InfiniteNature-Zero AI Model?
This AI generates infinite new frames as if you would be flying into your image!
188. AI and Automation, What's Next? A Take Over Or a Symbiosis?
Rethinking the future we want not the one that will befall us. We are in charge of our destiny.
189. Computer Vision Applications are Everywhere: Top Use cases in 2021
Computer vision applications have become ubiquitous nowadays. It’s hard to think of a domain where the ability of computers to “see” what’s going on around them has not yet been leveraged.
190. RANSAC, OLS, PCA: 3 Ways to Draw a Straight Line Across a Set of Points
How I approached solving an interview task for autonomous driving from 3 different perspectives: RANSAC, PCA, and Ordinary Least Squares (OLS).
191. How I Created a Simpsons Dataset for Instance Segmentation
This post is about creating your own custom dataset for Image Segmentation/Object Detection. It provides an end-to-end perspective on what goes on in a real-world image detection/segmentation project.
192. What Did AI Bring to Computer Vision?
In this video, I will openly share everything about deep nets for computer vision applications, their successes, and the limitations we have yet to address.
193. Unwrapping Wine Labels - How We Trained A Neural Network To Do It
In the previous article, it was described a six-point method to unwrap wine labels. Finding anchor points were performed with Hough transform. It gave fair results for good labels, but for many real cases it was quite unstable, and the efforts to tune it didn’t help much. It became clear at some point, Hough transform itself wasn’t capable of handling the variety of label forms, so the next step was training a neural network.
194. CVPR 2021 Best Paper Award: GIRAFFE Controllable Image Generation
Using a modified GAN architecture, they can move objects in the image without affecting the background or the other objects!
195. How the Use of Machine Learning is Challenging the Retail Apocalypse
Whether retailers like it or not, the future of retail is here, in the form of smart algorithms. Machine learning will change much of the industry's norms, often for the better. Retail trends point to the store of the future being automated using the latest technology. Brick & Mortar, physical retail... however you like to call it, your favourite real-world store is about to get a whole lot more digital. Whether that's the best idea remains to be seen.
196. Meta's Groundbreaking AI Film Maker: Make-A-Scene
Meta AI’s new model make-a-video is out and in a single sentence: it generates videos from text. It’s not only able to generate videos, but it’s also the new state-of-the-art method, producing higher quality and more coherent videos than ever before!
197. High-Resolution Photorealistic Image Translation in Real Time
You can apply any design, lighting, or graphics style to your 4K image in real-time using this new machine learning-based approach
198. Eight Awesome AI Youtube Videos Under 10 Minutes
Machine learning educational content is often in the form of academic papers or blog articles. These resources are incredibly valuable. However, they can sometimes be lengthy and time-consuming. If you just want to learn basic concepts and don’t require all the math and theory behind them, concise machine learning videos may be a better option.
199. Data Testing for Machine Learning Pipelines Using Deepchecks, DagsHub, and GitHub Actions
A complete setup of a ML project using version control (also for data with DVC), experiment tracking, data checks with deepchecks and GitHub Action
200. With AI, You Can Count 1000+ Sunflower Seeds In Seconds
In this post I will explain how we use artificial intelligence to count sunflower seeds on a photo taken with a mobile device.
201. An Intro to eDiffi: NVIDIA's New SOTA Image Synthesis Model
eDiffi, NVIDIA's most recent model, generates better-looking and more accurate images than all previous approaches like DALLE 2 or Stable Diffusion.
202. OpenAI’s DALL·E: Text-to-Image Generation Explained
OpenAI just released the paper explaining how DALL-E works! It is called "Zero-Shot Text-to-Image Generation".
203. DeOldify can Colorize your Black & White Photos with Full Photorealistic Renders
DeOldify is a technique to colorize and restore old black and white images or even film footage. It was developed by Jason Antic.
204. Using AI to Detect and Count Plastic Waste in the Ocean
A deep-learning-based algorithm that is able to detect and quantify floating garbage from aerial images of the ocean.
205. BlobGAN: A BIG step for GANs
BlobGAN allows for unreal manipulation of images, made super easily controlling simple blobs. All these small blobs represent an object, and you can move them around or make them bigger, smaller, or even remove them, and it will have the same effect on the object it represents in the image. This is so cool!
206. Realistic Face Manipulation in Videos With AI
You've most certainly seen movies like the recent Captain Marvel or Gemini Man where Samuel L Jackson and Will Smith appeared to look like they were much younger. This requires hundreds if not thousands of hours of work from professionals manually editing the scenes he appeared in. Instead, you could use a simple AI and do it within a few minutes.
207. ShaRF: Create a 3D Model of an Object Using Just a Single Image
ShaRF stands for Shape-conditioned Radiance Fields from a Single View. The goal is to take a picture of a real-life object, and translate this into a 3D scene.
208. StyleCLIPDraw: Text-to-Drawing Synthesis with Artistic Control
Have you ever dreamed of taking the style of a picture, like this cool TikTok drawing style on the left, and applying it to a new picture of your choice? Well, I did, and it has never been easier to do. In fact, you can even achieve that from only text and can try it right now with this new method and their Google Colab notebook available for everyone (see references).
209. How to Spot a DeepFake in 2021
How to Spot a Deep Fake in 2021. Breakthrough US Army technology using artificial intelligence to find deepfakes.
210. How to Create Realistic Slow Motion Videos With AI
TimeLens can understand the movement of the particles in-between the frames of a video to reconstruct what really happened at a speed even our eyes cannot see.
211. Meta AI's Make-A-Scene Generates Artwork with Text and Sketches
Make-A-Scene is not “just another Dalle”. The goal of this new model isn’t to allow users to generate random images following text prompt as dalle does — which is really cool — but restricts the user control on the generations.
212. Image Segmentation: Tips and Tricks from 39 Kaggle Competitions
Imagine if you could get all the tips and tricks you need to hammer a Kaggle competition. I have gone over 39 Kaggle competitions including
213. The Hitchhikers's Guide to PyTorch for Data Scientists
PyTorch has sort of became one of the de facto standard for creating Neural Networks now, and I love its interface. Yet, it is somehow a little difficult for beginners to get a hold of.
214. Would You Swipe Right for an AI Profile?
Most of us are convinced that we can dissociate humans from machines, but is it really the case? Would you swipe right for an AI-generated profile?
Thank you for checking out the 214 most read stories about Computer Vision on HackerNoon.
to find the most read stories about any technology.L O A D I N G
. . . comments & more!
. . . comments & more!





