LinkedIn’s feed has come a long way since the early days of assembling the machine learning infrastructure that powers it. Recently, a major update to this infrastructure was released. We caught up with the people behind it to discuss how the principle of being people-centric translates to technical terms and implementation.
People Mentioned
LinkedIn’s feed has come a long way since the early days of assembling the machine-learning infrastructure that powers it. Recently, a major update to this infrastructure was released. We caught up with the people behind it to discuss how the principle of being people-centric translates to technical terms and implementation.
How do data and machine learning-powered algorithms work to control newsfeeds and spread stories? How much of that is automated, how much should you be able to understand and control, and where is it all headed?
That was the introduction to my , exploring what was then a newly revamped LinkedIn newsfeed in terms of how the underlying machine learning algorithm worked and what the principles governing it were. Six years is a long time in technology. Back then, it was the early days of machine learning (aka “AI”) entering the mainstream. Today we live in the ChatGPT era.
In the last year interest in AI has peaked, and it seems like there are new developments almost on a weekly basis. LinkedIn could not possibly have stayed behind, and its machine-learning models and infrastructure have evolved significantly. Recently, LinkedIn Engineering published a blog post titled ““.
This blog post is a deep dive into LinkedIn’s newly revamped machine learning models and infrastructure that power its newsfeed. Unlike 2017, these changes are not directly perceptible. There are no new features per se, but rather, improvements in the underlying technology with the goal of enhancing the feed’s relevance.
We caught up with Jason Zhu, Staff Software Engineer, and Tim Jurka, Senior Director of Engineering at LinkedIn, to discuss how the principle of being people-centric translates to technical terms.
Click to listen to the conversation on the Orchestrate all the Things podcast
Human in the loop
The gist of the update is that LinkedIn’s model, powering the feed, can now handle a larger number of parameters, resulting in higher-quality content delivery. In the process, Zhu’s team also ended up upgrading the hardware infrastructure that powers the model.
Zhu is a member of the LinkedIn Foundational AI Technologies team. He defines the team’s mission as “prototyping and building the foundations behind those advanced algorithms that can benefit multiple vertical use cases at LinkedIn”. Zhu provided a good overview of LinkedIn’s previous major update to the feed in 2021, how that led to the latest update, as well as insights into the inner workings of LinkedIn’s approach.
However, we were also interested in finding out what else has changed compared to LinkedIn’s 2017 incarnation of the feed. Most notably, LinkedIn’s spokespeople in 2017 emphasized the , and we were wondering if that is still a thing. As Jurka put it, it’s definitely still a thing, probably even more of a thing now than it was then:
“It boils down to two applications for the feed. The first is we’re really trying to prioritize insightful, authentic, knowledge-oriented content in the LinkedIn feed, and it’s a very hard problem to get right just with AI alone. But we have an entire team of award-winning journalists led by our editor-in-chief, Dan Roth.
We’ve actually created AI algorithms that train on the content that they curate and believe is really the cream of the crop in terms of LinkedIn insights. That AI algorithm then tries to say – Would an editor promote this on LinkedIn’s platform? And if so, let’s try to distribute on the platform and see which audiences resonate with that particular piece of content.
The second is just with large language models, really taking the world by storm. The way that we make those high quality is by fine-tuning them using techniques like reinforcement learning with human feedback. And so large language models, again, are presenting yet another way where human loop is much more deeply integrated into the AI workflow versus where it was maybe five or six years ago”, Jurka said.
The human-in-the-loop approach also applies to spam detection. While LinkedIn employs AI-powered spam detection, there is also the option for users to report spam as well as content moderators to look out for anything the AI may have missed.
Jurka went on to add that as far as spam detection for the feed is concerned, some things have stayed the same, while others have changed. The three-bucket classification system described in 2017 has not changed much. What has changed is that LinkedIn has invested a lot more in deeper content understanding, aiming to understand the intent behind each post.
For example, is it somebody trying to share a job opportunity? Is it somebody trying to share their opinion about the news? Getting more granular about the content helps LinkedIn know how to distribute it across the platform.
From linear to neural, from single to multiple points of view
As Jurka shared, the evolution of the feed ranking algorithm really follows the evolution of the LinkedIn feed. Compared to 2017, there are . A lot of the complexity is about making sure that the AI models can capture all those diverse use cases. And this is where understanding intent is also relevant.
“For example, you might have a post from a member mentioning that they raised their Series A for their startup, and now they’re hiring. And that post can be perceived through three very different lenses.
If you’re a job seeker, that post might actually be an entry point for you to reach out and get a job, and the AI model has to understand that value to you. If you’re a first-degree connection of that individual, it might be just to congratulate them and say, Hey, I’m just checking to see you raised Series A. Congrats. If it’s somebody who’s in the venture capital space, this is actually an insight where they are like, I didn’t know that this particular company raised Series A”, Jurka said.
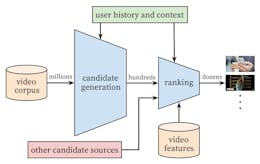
Picking up on that, Zhu explained that LinkedIn’s feed contains a heterogeneous list of updates from members, connections and a variety of recommendations such as jobs, people, and articles. The objective is to provide a personalized ranked list for each member, to help professionals on the platform be more productive and successful. To achieve this, LinkedIn has adopted a two stage ranking process.
There is something called the first pass ranker which is applied for each type of update. So the top-k candidates of each type of update are selected by individual algorithms before being sent to the second pass ranker for a final green ranking.
LinkedIn’s models are presented with a set of features from both member and content sets. The model is trying to predict a set of likelihood of responses such as the likelihood of starting a conversation or the likelihood of performing certain actions on a particular post.
Previously, LinkedIn transitioned its ranking from a linear-based model to a deep learning / neural network-based model. Zhu noted that the deep learning model is more effective because it introduces non-linearities through activation functions. That enables the models to capture more complex and non-linear relationships in the data and learn more powerful representations.
Instead of an individual linear model to predict each different response separately, a multitask deep learning model shares parameters between different tasks. So this learning of each task can benefit the other tasks through transfer learning, Zhu said.
However, he added, LinkedIn’s data is highly skewed between different types of responses. There are more click responses than engagement, for example. Therefore, cautious sampling and re-weighting is needed to avoid negative task interference during the model training process, because all those tasks are sharing parameters.
Harnessing the power of large corpus sparse ID embeddings
Zhu introduced LinkedIn’s previous major update of the feed, . As he shared, LinkedIn’s model size has grown by a factor of 500, while the data sets have also grown by a factor of 10. In addition, the training period was expanded and more training data is now sampled. This also presents some challenges in terms of overcoming bias.
However, this was just the starting point for the latest update Zhu’s team implemented. Their objective was to optimize for engagement, which means improving the prediction of likelihood in terms of how users will interact with different posts. Then by enhancing the prediction of this likelihood, LinkedIn can better rank feed items to provide more engaging experience to users. The key to this was sparse . Let’s see what these are and how they are relevant.
As a LinkedIn user interested in AI, you may have interacted with the #AI and #ML hashtags. Another user has interacted with the #generativeAI hashtag. These are different hashtags. However, via embeddings, their semantic meanings in the embedding space are close. As a result, the model can understand you may have similar tastes as mine, and the model can recommend similar content in the AI domain to both users.
For each content item on LinkedIn, and for each user, the recommendation system uses a vector of embeddings. This means that those vectors will be very large, but also very sparse. They will be large, i.e. have many dimensions, because there are many different topics and corresponding hashtags. But they will also be sparse because not all users have interacted with all hashtags.
Zhu’s focus is on transforming large corpus sparse ID features (such as hashtag ID or item/post ID) into embedding space using embedding lookup tables with hundreds of millions of parameters trained on multi-billions of records. For example, Zhu noted, that there are millions of dimensions for member IDs because there are millions of members on LinkedIn.
“For each member the goal is to learn a personalized tensor representation. This tensor representation will encode user preferences, such as interaction with other users or hashtag preferences in a fixed period. All this information will be encoded in a dense vector during training. By presenting the model with such a personalized vector, the model will be able to capture the dynamic, shifting world as well as member preferences better”, Zhu said.
Sparse features can be interpreted as categorical one-hot representations where the cardinality is several millions, Zhi noted. In these representations, all entries are zero except one, which corresponds to an ID index. That could be a hashtag ID or a member ID, for example. These are transformed into a low dimensional continuous dense space, called the embedding space, using embedding lookup tables with hundreds of millions of parameters trained on multibillion records.
As Zhu noted, the embedding table itself is highly coupled with the data set and the problem at hand. However, the technique is definitely generalizable. The same approach is already leveraged in different use cases within LinkedIn such as job recommendation and Ads recommendation. “We are adopting a very similar strategy of converting those sparse IDs to the dense representation. We believe that’s a scalable way of developing AI at LinkedIn”, Zhu said.
Scaling up, going forward
Zhu’s work also touched upon hardware upgrades. As he explained, the team was facing challenges in serving dozens of large models in parallel on their serving host after enlarging the model size by 100x. The host was just not designed to be able to handle such a scale, so the team chose to serve the model with a two-stage strategy.
In the first stage, a global model is trained in the usual way. ID features are converted to dense vectors from large embedding tables first and then these dense vectors are sent to a deep neural network along with existing features for implicit feature interactions.
In the second stage, the global model is split at the boundary of the embedding table and deep neural network. From the deep neural network’s perspective, it only needs a set of dense vectors, which is the embedding representation of those sparse features for predicting the result. The ID conversion step is not necessary to present it on the critical path of model serving.Embeddings are converted offline and pushed to high-performance key-value stores. Therefore, these embedding tables don’t have to be hosted in the serving host which has limited memory.
This strategy is used while in parallel LinkedIn is working on upgrading the host. Once the upgrade is complete, Zhu said, everything will be moved in memory and memory optimizations will be applied. The team adopted and extended the open-source framework .
Zhu identified a few directions his team would like to explore going forward. In addition to serving both memory-intensive and compute-intensive models, scaling model size by adding more sparse features is another objective. The team is also exploring something called continuous training or incremental training to capture the dynamics of a shifting world.
As Zhu explained, embeddings currently are trained on a fixed period basis. This could potentially introduce the problem of inconsistent offline vs. online results or diminished gains over a long period of time. Zhu thinks that by having more frequent retrieval, embeddings can capture the dynamics of the system and better predict a personalized feed for LinkedIn members.