




















visit
Skip List From Scratch: A Guide by@dmitriiantonov90
138 reads
Skip List From Scratch: A Guide
by Dmitrii AntonovApril 17th, 2024
Too Long; Didn't Read
A skip list is a probabilistic data structure that serves as a dynamic set. It offers an alternative to red-black or AVL trees. Skip lists are memory buffers in various NoSQL solutions, including Redis and RocksDB. Let’s code the base structure of our skip list.The Preface and Base Structure of a Skip List
A skip list is a probabilistic data structure that serves as a dynamic set, offering an alternative to red-black or AVL trees. It supports operations like search, inserts, and delete, which typically have an average time complexity of O(log(n)), although in the worst cases, time complexity will be O(n). Skip lists are memory buffers in various NoSQL solutions, including Redis and RocksDB.
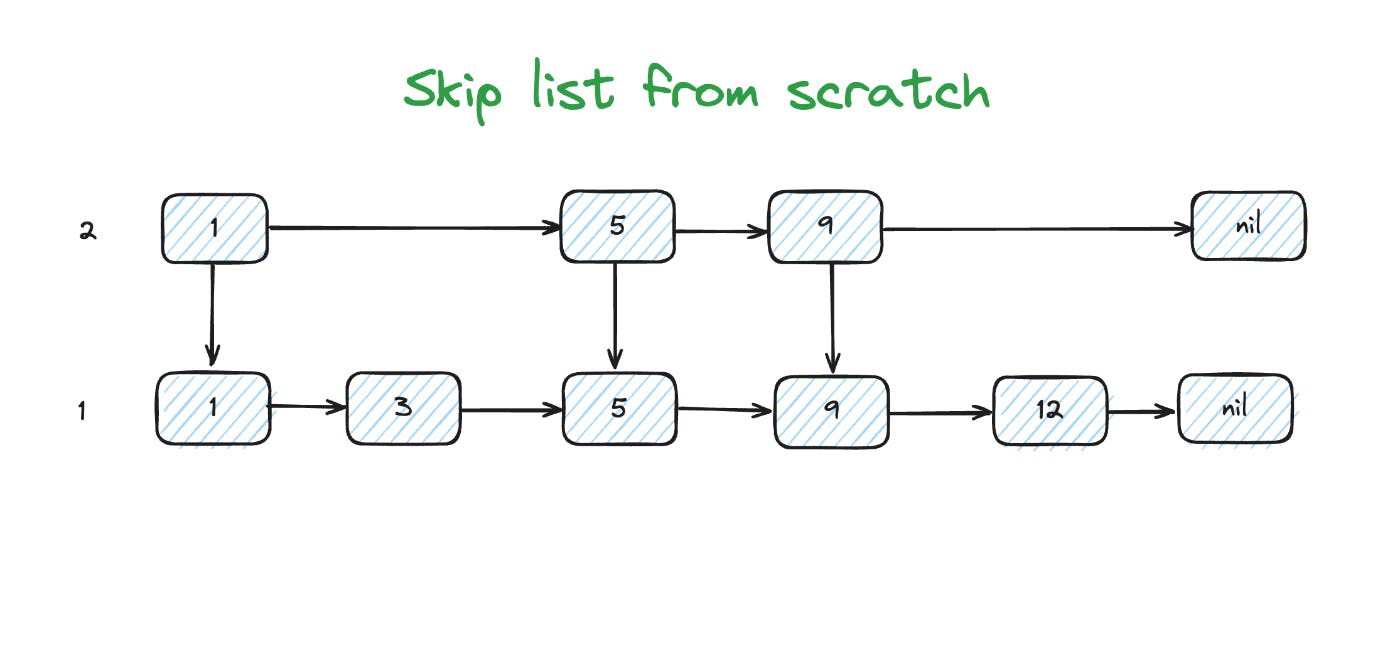
As you can see, our skip list consists of the levels. All the values of each skip list are sorted. Also, we must think about the high bound of levels. We take the const 16 because the original paper refers to it, and it ensures log(n) time complexity for lists that contain 2^16 elements. Let’s code the base structure of our skip list.
const (
maxLevel = 16
probability = 0.5
)
type node[T any] struct {
value T
next []*node[T]
}
type SkipList[T any] struct {
compare func(a, b T) int // returns -1 if a is less than b, 0 if a and b are equal, and 1 if a is greater than b
len int // number of elements of a skip list
level int // current level
head *node[T] // dummy node
}
func newNode[T any](value T) *node[T] {
return &node[T]{
value: value,
next: make([]*node[T], maxLevel),
}
}
func New[T any](compare func(a, b T) int) *SkipList[T] {
return &SkipList[T]{
compare: compare,
level: 1,
head: newNode[T](*new(T)),
}
}
Search Operation
The search operation of the skip list is very simple. We will follow by the highest level before our node is less than the current node; then we down to the next level and so on. We don’t go to the first level. This image illustrates our route. We want to find the node with the value 12. We have to pass through two nodes at level 3, one node at level 2, and two nodes at level 1.In our implementation, we will start from the highest level of our skip list and will go unless the current node is smaller than the desired node. We will repeat our doing until we get to level 1.
func (s *SkipList[T]) Search(value T) (T, bool) {
current := s.head
for i := s.level - 1; i >= 0; i-- {
for current.next[i] != nil && s.compare(current.next[i].value, value) < 0 {
current = current.next[i]
}
}
if current.next[0] != nil && s.compare(key, current.next[0].value) == 0 {
return current.next[0].value, true
}
return *new(T), false
}
Insert Operation
The insertion operation is somewhat more complex than the search operation. We introduce a new update variable that records the last node smaller than the inserted value at each level. If the inserted node is already present in the skip list, no action is taken. Next, we need to determine the level to which the new node will be promoted. If this calculated level exceeds the current level, additional levels will be added. We then update the references.
The code of the insert operation.
func (s *SkipList[T]) Insert(value T) {
current := s.head
update := make([]*node[T], maxLevel)
for i := s.level - 1; i >= 0; i-- {
for current.next[i] != nil && s.compare(current.next[i].value, value) < 0 {
current = current.next[i]
}
update[i] = current
}
if current.next[0] != nil && s.compare(current.next[0].value, value) == 0 {
return
}
level := randomLevel()
if level > s.level {
for i := s.level; i < level; i++ {
update[i] = s.head
}
s.level = level
}
x := newNode[T](value)
for i := 0; i < level; i++ {
x.next[i] = update[i].next[i]
update[i].next[i] = x
}
s.len++
}
func randomLevel() int {
level := 1
for rand.Float64() < probability && level < maxLevel {
level++
}
return level
}
Delete Operation
The delete operation is similar to the insert operation. We use the update variable to store the last node smaller than the node to be deleted. After identifying all relevant nodes, we remove them if the subsequent node is the one to be deleted. If the dummy node points to nil, we will decrement the level.
func (s *SkipList[T]) Remove(value T) bool {
current := s.head
update := make([]*node[T], maxLevel)
for i := s.level - 1; i >= 0; i-- {
for current.next[i] != nil && s.compare(current.next[i].value, value) < 0 {
current = current.next[i]
}
update[i] = current
}
if current.next[0] == nil || s.compare(current.next[0].value, value) != 0 {
return false
}
for i := 0; i < s.level; i++ {
if update[i].next[i] == nil || s.compare(current.next[i].value, value) != 0 {
break
}
update[i].next[i] = update[i].next[i].next[i]
}
for s.level > 1 && s.head.next[s.level-1] == nil {
s.level--
}
s.len--
return true
}
L O A D I N G
. . . comments & more!
. . . comments & more!






