









































visit
Violence Detection in Videos: Proposed Approach by@kinetograph
144 reads
Violence Detection in Videos: Proposed Approach
by Kinetograph: The Video Editing Technology PublicationJune 1st, 2024
Too Long; Didn't Read
In this paper, researchers propose a system for automatic detection of violence in videos, utilizing audio and visual cues for classification.
Authors:
(1) Praveen Tirupattur, University of Central Florida.Table of Links
- Abstract
- Acknowledgements
- Chapter 1: Introduction
- Chapter 2: Related Work
- Chapter 3: Proposed Approach
- Chapter 4: Experiments and Results
- Chapter 5: Conclusions and Future Work
- Bibliography
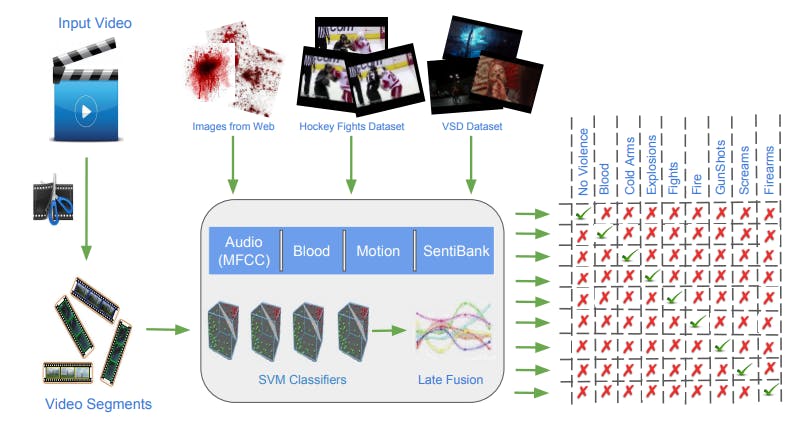
3. Proposed Approach
This chapter provides a detailed description of the approach followed in this work. The proposed approach consists of two main phases: Training and Testing. During the training phase, the system learns to detect the category of violence present in a video by training classifiers with visual and audio features extracted from the training dataset. In the testing phase, the system is evaluated by calculating the accuracy of the system in detecting violence for a given video. Each of these phases is explained in detail in the following sections. Please refer to Figure 3.1 for the overview of the proposed approach. Finally, a section describing the metrics used for evaluating the system is presented.3.1. Training
In this section, the details of the steps involved in the training phase are discussed. The proposed training approach has three main steps: Feature extraction, Feature Classification, and Feature fusion. Each of these three steps is explained in detail in the following sections. In the first two steps of this phase, audio and visual features from the video segments containing violence and no violence are extracted and are used to train two-class SVM classifiers. Then in the feature fusion step, feature weights are calculated for each violence type targeted by the system. These feature weights are obtained by performing a grid search on the possible combination of weights and finding the best combination which optimizes the performance of the system on the validation set. The optimization criteria here is the minimization of EER (Equal Error Rate) of the system. To find these weights, a dataset disjoint from the training set is used, which contains violent videos of all targeted categories. Please refer to Chapter 1 for details of targeted categories.
3.1.1. Feature Extraction
Many researchers have tried to solve the Violence detection problem using different audio and visual features. A detailed information on violence detection related research is presented in Chapter 2. In the previous works, the most common visual features used to detect violence are motion and blood and the most common audio feature used is the MFCC. Along with these three common low-level features, this proposed approach also includes SentiBank (Borth et al. [4]), which is a visual feature representing sentiments in images. The details of each of the features and its importance in violence detection and the extraction methods used are described in the following sections.3.1.1.1. MFCC-Features
Audio features play a very important role in detecting events such as gunshots, explosions etc, which are very common in violent scenes. Many researchers have used audio features for violence detection and have produced good results. Even though some of the earlier works looked at energy entropy [Nam et al. [41]] in the audio signal, most of them used MFCC features to describe audio content in the videos. These MFCC features are commonly used in voice and audio recognition.
3.1.1.2. Blood-Features
Blood is the most common visible element in scenes with extreme violence. For example, scenes containing beating, stabbing, gunfire, and explosions. In many earlier works on violence detection, detection of pixels representing blood is used as it is an important indicator of violence. To detect blood in a frame, a pre-defined color table is used in most of the earlier works, for example, Nam et al. [41] and Lin and Wang [38]. Other approaches to detecting blood, such as the use of Kohonen’s Self-Organizing Map (SOM)(Clarin et al. [12]), are also used in some of the earlier works.
3.1.1.3. Motion-Features
Motion is another widely used visual feature for violence detection. The work of Deniz et al. [21], Nievas et al. [42] and Hassner et al. [28] are some of the examples in which motion is used as the main feature for violence detection. Here, motion refers to the amount of spatio-temporal variation between two consective frames in a video. Motion is considered a good indicator of violence as substantial amount of violence is expected in the scenes that contain violence. For example, in the scenes that contain person-on-person fights, there is fast movement of human body parts like legs and hands, and in scenes that contain explosions, there is a lot of movement from the parts that are flying apart because of the explosion.
3.1.1.3.1. Using Codec
In this method, the motion information is extracted from the video codec. The magnitude of motion at each pixel per frame called the motion vector is retrieved from the codec. This motion vector is a two-dimensional vector and has the same size as a frame from the video sequence. From this motion vector, a motion feature which represents the amount of motion in the frame is generated. To generate this motion feature, first the motion vector is divided into twelve sub-regions of equal sizes by slicing it along the x and y-axis into three and four regions respectively. The amount of motion along the x and y-axis at each pixel from each of these sub-regions are aggregated and these sums are used to generate a two-dimensional motion histogram for each frame. This histogram represents the motion vector for a frame. Refer to the image on the left in Figure 3.5 to see the visualization of the aggregated motion vectors for a frame from a sample video. In this visualization, the motion vectors are aggregated for sub-regions of size 16 × 16 pixels. The magnitude and direction of motion in these regions is represented using the length and orientation of the green dashed lines which are overlaid on the image.3.1.1.3.2. Using Optical Flow
The next approach to detect motion uses Optical flow (Wikipedia [57]). Here, the motion at each pixel in a frame is calculated using Dense Optical Flow. For this, the implementation of Gunner Farneback’s algorithm (Farneb¨ack [24]) provided by OpenCV (Bradski [5]) is used. The implementation is provided as a function in OpenCV and for more details about the function and the parameters, please refer to the documentation provided by OpenCV (OpticalFlow [43]). The values 0.5, 3, 15, 3, 5, 1.2 and 0 are passed to the function parameters pyr scale, levels, win-size, iterations, poly n, poly sigma and flags respectively. Once the motion vectors at every pixel are calculated using Optical flow, the motion feature from a frame is extracted using the same process mentioned in the above Section 3.1.1.3.1. Refer to the image on the rights in Figure 3.5 to get an impression of the aggregated motion vectors extracted from a frame. The motion vectors are aggregated for sub-regions of size 16×16 pixels as in the previous approach to provide a better comparison between the features extracted by using Codec information and Optical flow.
3.1.1.4. SentiBank-Features
In addition to the aforementioned low-level features, the SentiBank feature introduced by Borth et al. [4] is also applied. SentiBank is a mid-level representation of visual content based on the large-scale Visual Sentiment Ontology (VSO) [1]. SentiBank consists of 1,200 semantic concepts and corresponding automatic classifiers, each being defined as an Adjective Noun Pair (ANP). Such ANPs combine strong emotional adjectives to be linked with nouns, which correspond to objects or scenes (e.g. “beautiful sky”, “disgusting bug”, or “cute baby”). Further, each ANP (1) reflects a strong sentiment, (2) has a link to an emotion, (3) is frequently used on platforms such as Flickr or YouTube and (4) has a reasonable detection accuracy. Additionally, the VSO is intended to be comprehensive and diverse enough to cover a broad range of different concept classes such as people, animals, objects, natural or man-made places and, therefore, provides additional insights about the type of content being analyzed. Because SentiBank demonstrated its superior performance as compared to low-level visual features on the analysis of sentiment Borth et al. [4], it is used now for the first time to detect complex emotion such as violence from video frames.
3.1.2. Feature Classification
The next step in the pipeline after feature extraction is feature classification and this section provides the details of this step. The selection of classifier and the training techniques used play a very important role in getting good classification results. In this work, SVMs are used for classification. The main reason behind this choice is the fact that the earlier works on violence detection have used SVMs to classify audio and visual features and have produced good results. In almost all the works mentioned in Chapter 2 SVMs are used for classification, even though they may differ in the kernel functions used.
3.1.3. Feature Fusion
In the feature fusion step, the output probabilities from each of the feature classifiers are fused to get the final score of the violence in a video segment along with the class of violence present in it. This fusion is done by calculating the weighted sum of the probabilities from each of the feature classifiers. To detect the class of violence to which a video belongs, the procedure is as follows. First, the audio and visual features are extracted from the videos belonging to each of the targeted violence classes. These features are then passed to the trained binary SVM classifiers to get the probabilities of each of the video containing violence. Now, these output probabilities from each of the feature classifiers are fused by assigning each feature classifier a weight for each class of violence and calculating the weighted sum. The weights assigned to each of the feature classifiers represent the importance of a feature in detecting a specific class of violence. These feature weights have to be adjusted appropriately for each violence class for the system to detect the correct class of violence.
3.2. Testing
In this stage, for a given input video, each segment containing violence is detected along with the class of violence present in it. For a given video, the following approach is used to detect the segments that contain violence and the category of violence in it. First, the visual and audio features are extracted from one frame every 1-second starting from the first frame of the video, rather than extracting features from every frame. These frames from which the features are extracted, represent a 1-second segment of the video. The features from these 1-second video segments are then passed to the trained binary SVM classifiers to get the scores for each video segment to be violent or non-violent. Then, weighted sums of the output values from the individual classifiers are calculated for each violence category using the corresponding weights found during fusion step. Hence, for a given video of length ‘X’ seconds, the system outputs a vector of length ‘X’. Each element in this vector is a dictionary which maps each violence class with a score value. The reason for using this approach is two fold, first to detect time intervals in which there is violence in the video and to increase the speed of the system in detecting violence. The feature extraction, especially extracting the Sentibank feature, is timeconsuming and doing it for every frame will make the system slow. But this approach has a negative effect on the accuracy of the system as it detects violence not for every frame but for every second.3.3. Evaluation Metrics
There are many metrics that can be used to measure the performance of a classification systems. Some of the measures used for binary classification are Accuracy, Precision, Recall (Sensitivity), Specificity, F-score, Equal Error Rate (EER), and Area Under the Curve (AUC). Some other measures such as Average Precision (AP) and Mean Average Precision (MAP) are used for systems which return a ranked list as a result to a query. Most of these measures that are increasingly used in Machine Learning and Data Mining research are borrowed from other disciplines such as Information Retrieval (Rijsbergen [49]) and Biometrics. For a detailed discussion on these measures, refer to the works of Parker [44] and Sokolova and Lapalme [53]. The ROC (Receiver Operating Characteristic) curve is another widely used method for evaluating or comparing binary classification systems. Measures such as AUC and EER can be calculated from the ROC curve.
3.4. Summary
In this chapter, a detailed description of the approach followed in this work to detect violence is presented. The first section deals with the training phase and the second section deals with the testing phase. In the first section, different steps involved in the training phase are explained in detail. First the extraction of audio and visual features is discussed and the details of what features are used and how they are extracted are presented. Next, the classification techniques used to classify the extracted features are discussed. Finally, the process used to calculate feature weights for feature fusion is discussed. In the second section, the process used during the testing phase to extract video segments containing violence and to detect the class of violence in these segments is discussed.
This paper is under CC 4.0 license.
[1] //visual-sentiment-ontology.appspot.com
L O A D I N G
. . . comments & more!
. . . comments & more!







