


































































































visit
47 Stories To Learn About Kafka by@learn
420 reads
47 Stories To Learn About Kafka
by Learn RepoAugust 15th, 2023
Too Long; Didn't Read
Learn everything you need to know about Kafka via these 47 free HackerNoon stories.People Mentioned
Let's learn about Kafka via these 47 free stories. They are ordered by most time reading created on HackerNoon. Visit the to find the most read stories about any technology.
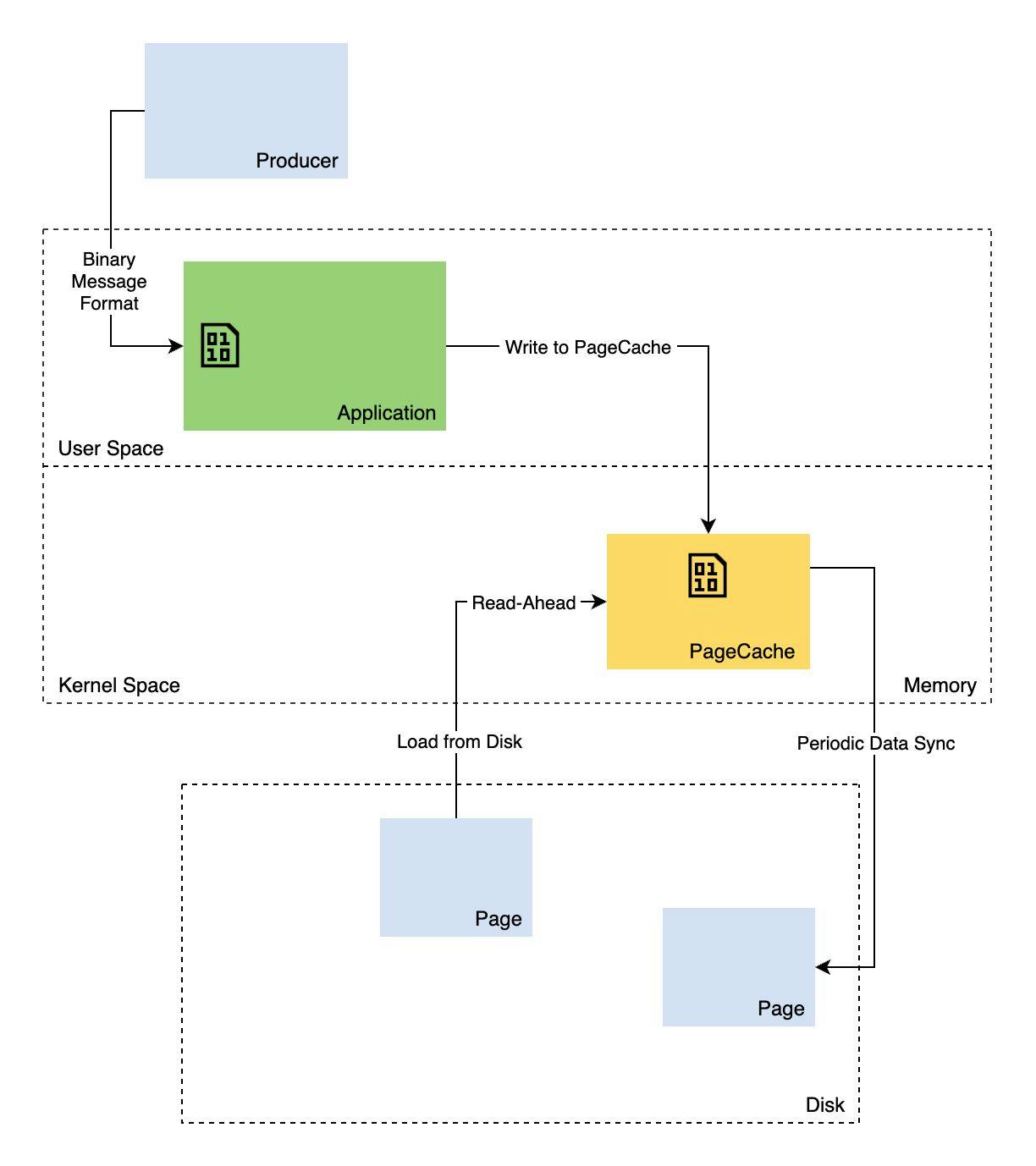
1. Kafka Storage Design - Making File Systems Cool Again!
What makes Kafka so Fast? A Deep Dive into Kafka Storage Internals.
2. Build a Live Dashboard with Materialize, Airbyte, MySQL and Redpanda/Kafka
3. Deploying Apache Kafka With Kubernetes
Deploying Kafka on Kubernetes is a low-effort approach to setting up an event-driven architecture to support your API ecosystem in the cloud.
4. Top Apache Kafka® Interview Questions for Juniors In 2023
Prep for an Apache Kafka interview by reading this questions! Aimed at juniors.
5. Comparing Apache Kafka with Oracle Transactional Event Queues (TEQ) as Microservices Event Mesh
This blog contrasts and compares transactional and message delivery behavior of Kafka with the converged Oracle DB and Oracle Transactional Event Queues/AQ
6. Kuma 1.0 GA Released With 70+ New Features & Improvements
Today is a big day for Kuma! Kuma 1.0 is now generally available with over 70 features and improvements ready to use and deploy in production to create modern distributed service meshes for every application running on multiple clusters, clouds, including Kubernetes and VM-based workloads.
7. Setting up Kafka on Docker for Local Development
In a world where data is king, Kafka is a valuable tool for developers and data engineers to learn.
8. A Brief Introduction to Commit Logs
Logs are everywhere in software development. Without them there’d be no relational databases, git version control, or most analytics platforms.
9. Key Apache KafkaⓇ Concepts Every Dev Needs to Know
In my first few months learning Apache Kafka, I drew up a blog post on the fundamental concepts behind implementing it.
10. Using dbt with Materialize and Redpanda
11. Take your Materialized Views to the Next Level by Joining MySQL and Postgres
12. How to Execute a Scheduled Task in Keycloak on Startup
In this article, we will look at how to execute a scheduled task in Keycloak on startup using a Kafka consumer as an example.
13. Kafka Administration and Monitoring UI Tools
Kafka itself comes with command line tools that can do all the administration tasks, but those tools aren’t very convenient because they are not integrated into one tool and you need to run a different tool for different tasks. Moreover, it is getting difficult to work with them when your clusters grow large or when you have several clusters.
14. Build your Own Live Chart With Deno, WebSockets, Chart.js and Materialize
We will build a simple dashboard app that displays data from a Deno Web Socket server.
15. How to Easily Stream Data From a Headless BI and SQL Engine
Now, you can use Cube to build data modeling, caching, and access control layers on top of streaming SQL, just as with cloud data warehouses.
16. Stream and Display Data in Realtime with Materialize and Adonis
In this tutorial, we are going to build a web application using AdonisJS and integrate it with Materialize to create a real-time dashboard
17. Auto-generation of Documentation for Event-driven Architecture
Auto-generation of documentation for Event-driven architecture
18. Using Kafka & Zookeeper Offsets
Kafka version 0.9v and above provide the capability to store the topic offsets on the broker directly instead of relying on the Zookeeper.
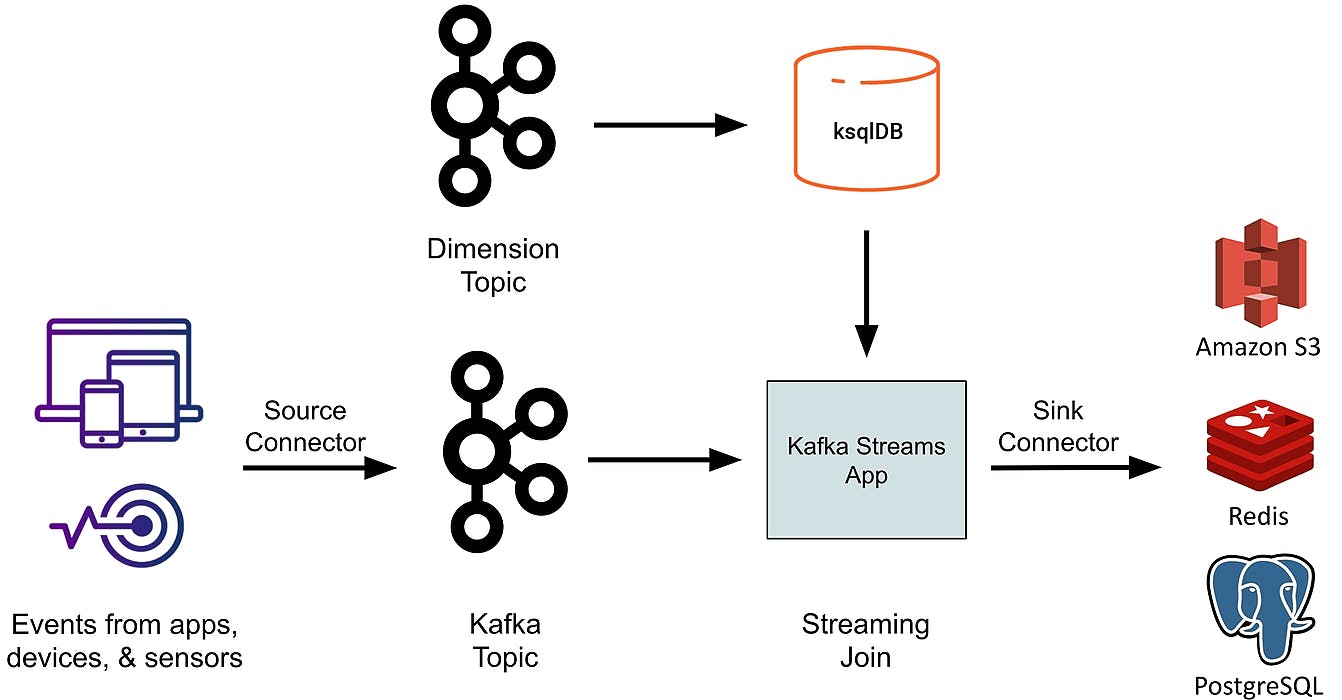
19. Using KSQL Stream Processing & Real-Time Databases to Analyze Kafka Streaming Data [A How-To Guide]
Intro
20. Apache Kafka: the Complicated Simplicity
This post is about issues, misunderstandings and sometimes heroic solutions from our experience of using Kafka as the main data exchange platform.
21. How to Use Materialize and Redpanda to Analyze Raspberry Pi Temperature Data
This is a self-contained demo using Materialize to process data IoT devices data directly from a PostgreSQL server.
22. Debezium Introduction: Another Change Data Capture Tool
Building an enterprise data warehouse can be either relatively straightforward or very sophisticated. It depends on many factors, such as the conceptual data model complexity and the variety of source systems. In many cases, applying the Change Data Capture (CDC) approach can make the data integration simpler. Fortunately, there are plenty of CDC tools available in the market, many of which are easy-to-use and affordable, while others are cumbersome and expensive (for what it is).
23. Tips About Kafka Connect On Heroku You Can't Afford To Miss
Introduction
24. Best Practices For Apache Kafka Configuration
Having worked with Kafka for more than two years now, there are two configs whose interaction I've seen be ubiquitously confused.
25. Deploy Your Application with Kafka and Docker in 20 Minutes
In this tutorial, we'll walk you through how to use Docker, Kafka, and Kubernetes to deploy a simple application.
26. Data Pipelines and Expiring Dictionaries
Designing a data pipeline comes with its own set of problems. Take lambda architecture for example. In the batch layer, if data somewhere in the past is incorrect, you’d have to run the computation function on the whole (possibly terabytes large) dataset, the result of which would be absorbed in serving layer and are reflected.
27. Choosing Between Enterprise Messaging and Event Streaming For Your Architecture
Comparing Enterprise messaging and event streaming across different dimensions to see how they excel at solving different but related messaging problems
28. Lambda Architecture Batch Layer: Visualizing All Time Taxi Data [Part 3]
In this part i would be talking about the batch layer of the Lambda Architecture. Batch layer is computed by applying a function to the whole historical dataset, to answer some high level questions which cannot be answered by either speed layer or serving layer. The computations typically take hours or days to run, and the results are stored usually in a distributed file system (although this is not a requirement). For example, the queries that might need to be answered would range from the beginning of the dataset to now, in our case, till date how many cabs have served how many passengers, or what is the total distance driven by all the cabs. In this article i would try to answer questions like these based on the dataset that i have. The code for the article can be found here.
29. Understanding Kafka Partitions: How to Get the Most out of Your Kafka Cluster
This blog provides an overview around the two fundamental concepts in Apache Kafka: Topics and Partitions. While developing and scaling our Anomalia Machina application we have discovered that distributed applications using Kafka and Cassandra clusters require careful tuning to achieve close to linear scalability, and critical variables included the number of Kafka topics and partitions. In this blog, we test that theory and answer questions like “What impact does increasing partitions have on throughput?” and “Is there an optimal number of partitions for a cluster to maximize write throughput?” And more!
30. Apache Kafka: How Does It Work?
This article was originally posted to the Confluent blog.
31. RocksDB Is Steadily Eating the Database World
Technical design. Because one of the most common use cases of the new databases is storing data that is generated by high-throughput sources, it is important that the store engine is able to handle write-intensive workloads, all while offering acceptable read performance. RocksDB implements what is known in the database literature as a log-structured merge tree aka LSM tree.
32. How to Authenticate Kafka Using Kerberos (SASL), Spark, and Jupyter Notebook
Kafka & Spark integration may be tricky when Kafka is protected by Kerberos. Here is the guide on how to access Kafka with Spark and Spark Streaming.
33. Lambda Architecture Serving Layer: Real-Time Visualization For Taxi [Part 2]
In this part i would be talking about the serving layer of the Lambda Architecture. Serving layer is derived either by performing computation on batch data to arrive at a view that is mid way from speed layer and batch layer
34. The Only Decoupling Checklist You Need To Know About
My team has recently successfully decoupled one of the critical business domains of the company. The initial integration had such a tough deadline that the only way to meet it was to add code to the monolith. And… The feature that went from conception to production in three weeks ended up taking almost one year to decouple.
35. Getting Started with Spring Cloud Stream
This post was co-written with Ben Wilcock, Product and Technical Marketing Manager for Spring at Pivotal.
36. How Stream Processing Makes Your Event-Driven Architecture Better
If you’re an architect or developer looking at event-driven architectures, stream processing might be just what you need to make your app faster, more scalable, and more decoupled.
37. 5 Problems and Their Solutions With Creating a High-Load Service Using .NET and Kafka
Specifics and complications of creating a high-load service using .NET and Kafka.
38. Real-time Analytics and Data Processing with Kafka & Spark
Real-time analytic systems use data processing frameworks, including Apache Kafka and Apache Spark. Learn more here!
39. Lambda Architecture Speed Layer: Real-Time Visualization For Taxi [Part 1]
Lambda architecture has 3 components, a) Speed layer, which is the streaming data layer or real time data layer, b) serving layer, which is the database layer, which is derived by aggregating data from speed layer, and c) batch layer, which is the set of computations which are perfomed on large sets of data, typically stored in a distributed file system. In this post i will be talking about how to implement the speed layer, by visualizing real time taxi data. Post that, the visualization will allow us to make some real time business decisions. Code for this article can be found here.
40. How to Stream XML messages from IBM MQ into Kafka into MongoDB
Let’s imagine we have XML data on a queue in IBM MQ, and we want to ingest it into Kafka to then use downstream, perhaps in an application or maybe to stream to a NoSQL store like MongoDB.
41. Kafka Gotchas
I’ve assisted several large clients in building a microservices-style architecture using Kafka as a messaging backbone, having a reasonably good understanding of its abilities and the use cases that really bring them out. But I’m not a Kafka apologist by any stretch; any technology that has gone through such a rapid adoption curve is bound to polarise its audience and rub certain developers up a wrong way, and Kafka is no exception. Like anything else, you need to invest a significant amount of time in getting across Kafka and event streaming in general, before you become fully proficient and can harness its might. And be prepared to face one or two frustrations, to put it mildly, along the way.
42. Kafka Connect Framework: Creating a Real-Time Data Pipeline Using CDC
Microservices, Machine Learning & Big Data are making waves among organizations. Curiously they all share the same biggest concern: data.
43. Kafka Basics and Core Concepts: Explained
In this article we will cover the core concepts of Kafka and also will touch upon a few of the advanced topics.
44. Jaeger Persistent Storage with Elasticsearch, Cassandra and Kafka
Running systems in production involve requirements for high availability, resilience and recovery from failure. When running cloud-native applications this becomes even more critical, as the base assumption in such environments is that compute nodes will suffer outages, Kubernetes nodes will go down and microservices instances are likely to fail, yet the service is expected to remain up and running.
45. How the ZooKeeper Solves the Dining Philosophers Problem
In this blog by Paul Brebner, Instaclustr's tech evangelist explains the Apache ZooKeeper using the famous dining philosophers problem.
46. Introduction to Event Streaming with Kafka and Kafdrop
Event sourcing, eventual consistency, microservices, CQRS... These are quickly becoming household names in mainstream application development. But do you know what makes them tick? What are the basic building blocks required to assemble complex, business-centric applications from fine-grained services without turning the lot into a big ball of mud?
47. 5 Things Every Apache Kafka Dev Needs To Know: A Performance and Architectural Deep Dive
Here are five tips on how Kafka works and how you can get started with Apache Kafka.
Thank you for checking out the 47 most read stories about Kafka on HackerNoon.
to find the most read stories about any technology.L O A D I N G
. . . comments & more!
. . . comments & more!







