visit
A Detailed Analysis on the Effectiveness of Automatic Filtering by@feedbackloop
A Detailed Analysis on the Effectiveness of Automatic Filtering
by The FeedbackLoop: #1 in PM EducationJanuary 17th, 2024
Too Long; Didn't Read
Delve into the detailed analysis of automatic filtering effectiveness, revealing its impact on error identification. With only 9.6% of randomly selected dialogs containing errors, the study showcases 130 error cases identified through automatic filtering. Notably, a concentration of errors is observed in the 60%−100% similarity range, emphasizing the precision of the filtering process.Authors:
(1) Dominic Petrak, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany; (2) Nafise Sadat Moosavi, Department of Computer Science, The University of Sheffield, United Kingdom; (3) Ye Tian, Wluper, London, United Kingdom; (4) Nikolai Rozanov, Wluper, London, United Kingdom; (5) Iryna Gurevych, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany.Table of Links
Manual Error Type Analysis and Taxonomies
Automatic Filtering for Potentially Relevant Dialogs
Conclusion, Limitation, Acknowledgments, and References
A Integrated Error Taxonomy – Details
B Error-Indicating Sentences And Phrases
C Automatic Filtering – Implementation
D Automatic Filtering – Sentence-Level Analysis
E Task-Oriented Dialogs – Examples
F Effectiveness Of Automatic Filtering – A Detailed Analysis
G Inter-Annotator Agreement – Detailed Analysis
I Hyperparameters and Baseline Experiments
J Human-Human Dialogs – Examples
F Effectiveness Of Automatic Filtering – A Detailed Analysis
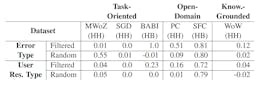
For the statistical analysis in Section 6, we consider 20 dialogs from each similarity range, i.e., 50%−60%, 60%−70%, 70%−80%, 80%−90%, 90% − 100% (if available, see also Appendix D) for each dataset examined. As the data in the upper ranges (80%−100%) is scarce in case of WoW (Dinan et al., 2019), PC (Zhang et al., 2018), and BABI (Bordes et al., 2017), the filtered dialogs consists only of 555 dialogs (instead of 600 like the randomly selected dialogs). Table 12 shows the errors annotated for the statistical analysis with respect to the similarity ranges identified by automatic filtering (meaning that each dialog contains at least one user response with a sentence identified to be similar to at least one error-indicating sentence in this similarity range). Overall (O) represents the number of dialogs randomly sampled from the respective similarity range, and Error (E) represents the number of dialogs identified in our manual analysis to contain an error in a system utterance.
This paper is under CC BY-NC-SA 4.0 DEED license.
L O A D I N G
. . . comments & more!
. . . comments & more!