

























visit
Adversarial Machine Learning: A Beginner’s Guide to Adversarial Attacks and Defenses by@miguelhzbz
3,085 reads
Adversarial Machine Learning: A Beginner’s Guide to Adversarial Attacks and Defenses
by Miguel HernándezJanuary 9th, 2022
Too Long; Didn't Read
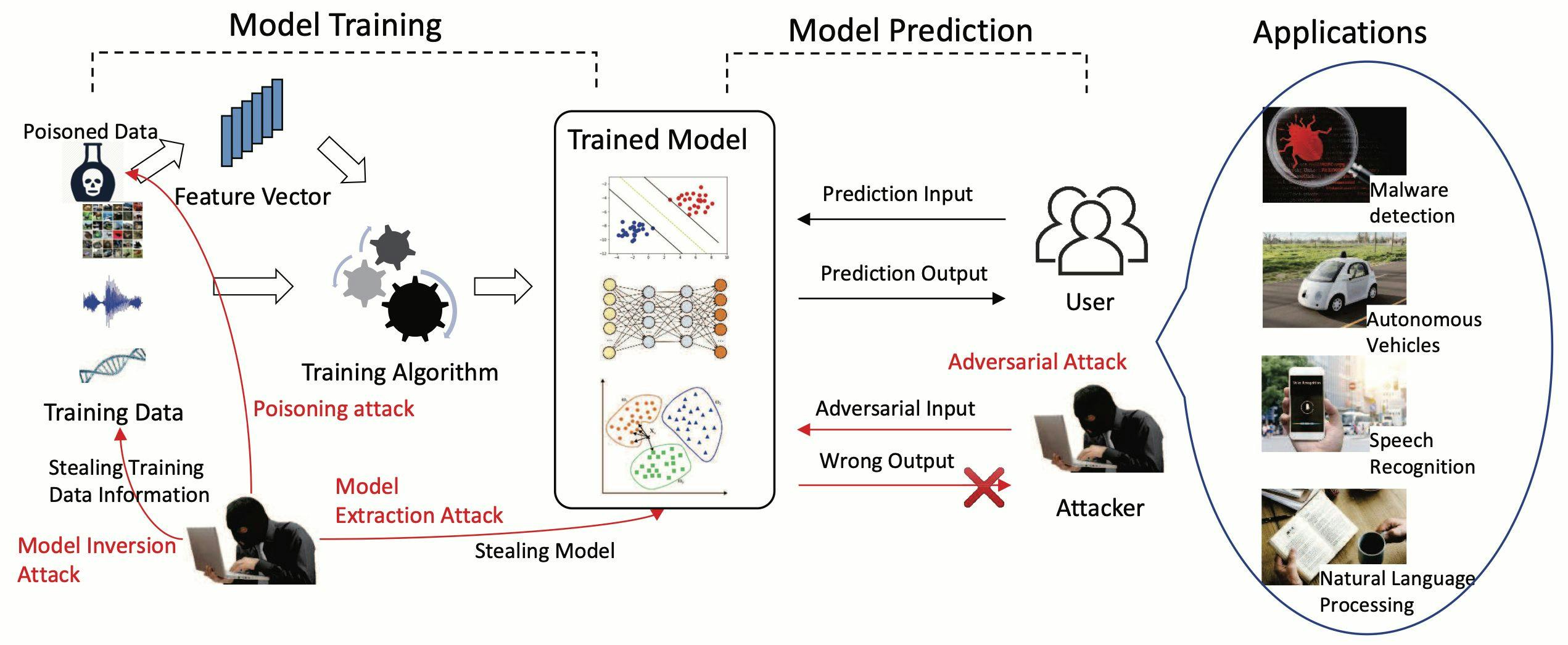
There are [four types of attacks] that ML models can suffer. An adversary steals a copy of a remotely deployed machine learning model, given oracle prediction access. Extraction attacks aim to extract as much information as possible and with the set of inputs and outputs train a model called substitute model. Extract model is hard**, the attacker needs a huge compute capacity to re-training the new model with accuracy and fidelity, and substitute model is equivalen to training a model from the ground up.Companies Mentioned
Coin Mentioned
Adversarial machine learning is concerned with the design of ML algorithms that can resist security challenges.
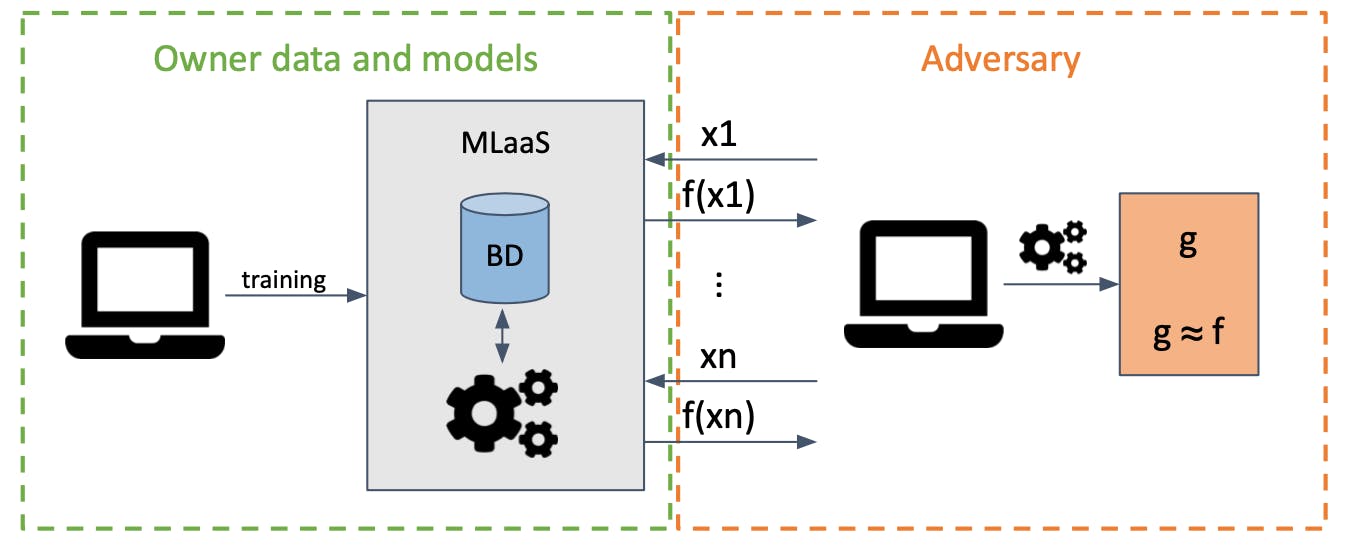
Extraction attacks
In a model extraction attack, an adversary steals a copy of a remotely deployed machine learning model, given oracle prediction access.
Extract model is hard, the attacker needs a huge compute capacity to re-training the new model with accuracy and fidelity, and substitute model is equivalent to training a model from the ground up.
Defenses
- Limit the output information when the model classifies a given input.
- Differential Privacy.
- Use ensembles.
- Proxy between end-user and model like .
- Limit the number of requests.
Inference attacks
Inference attacks aim to reverse the information flow of a machine learning model. They allow an adversary to have knowledge of the model that was not explicitly intended to be shared. Inference attacks pose severe privacy and security threats to individuals and systems. They are successful because private data are statistically correlated with public data, and ML classifiers can capture such statistical correlations.
- Membership Inference Attack (MIA).
- Property Inference Attack (PIA).
- Recovery training data.
Defenses
- Use advanced cryptography.
- Differential cryptography.
- Homomorphic cryptography.
- Secure Multi-party Computation.
- Techniques such as Dropout.
- Model compression.
Poisoning attacks
This technique involves an attacker inserting corrupt data in the training dataset to compromise a target machine learning model during training.
Some data poisoning techniques aim to trigger a specific behavior in a computer vision system when it faces a specific pattern of pixels at inference time. Other data poisoning techniques aim to reduce the accuracy of a machine learning model on one or more output classes.
Finally, the attacker could create a backdoor in a model. The model behaves correctly (returning the desired predictions) in most cases, except for certain inputs specially created by the adversary that produce undesired results. The adversary can manipulate the results of the predictions and launch future attacks.
Defenses
- Protect the integrity of training data.
- Protect the algorithms, use robust methods to train models.
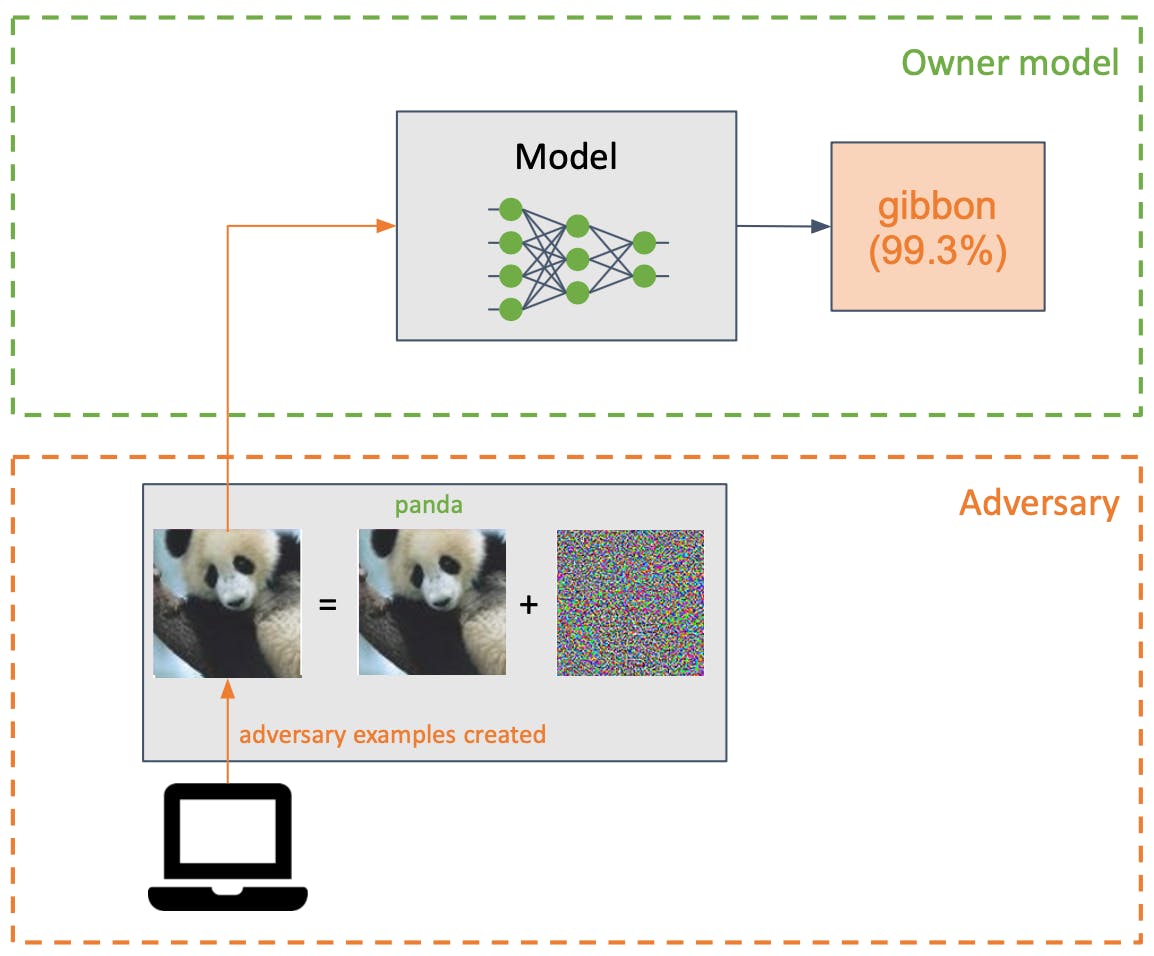
Evasion attacks
An adversary inserts a small perturbation (in the form of noise) into the input of a machine learning model to make it classify incorrectly (example adversary).
An evasion attack happens when the network is fed an “adversarial example” — a carefully perturbed input that looks and feels exactly the same as its untampered copy to a human — but that completely throws off the classifier.
Defenses
- Training with adversarial examples which robust the model.
- Transform the input to the model (Input sanitization).
- Gradient regularization.
Tools
Adversarial Robustness Toolbox (ART)
is a Python library for Machine Learning Security. ART provides tools that enable developers and researchers to defend and evaluate Machine Learning models and applications against the adversarial threats of Evasion, Poisoning, Extraction, and Inference.
ART supports all popular machine learning frameworks:
- TensorFlow
- Keras
- PyTorch
- scikit-learn
- Images
- Tables
- Audio
- Video
- Classification
- Object detection
- Speech recognition
pip install adversarial-robustness-toolbox
from art.attacks.evasion import FastGradientMethod
attack_fgm = FastGradientMethod(estimator = classifier, eps = 0.2)
x_test_fgm = attack_fgm.generate(x=x_test)
predictions_test = classifier.predict(x_test_fgm)
from art.defences.trainer import AdversarialTrainer
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=tf.keras.optimizers.Adam(lr=0.01), metrics=["accuracy"])
defence = AdversarialTrainer(classifier=classifier, attacks=attack_fgm, ratio=0.6)
(x_train, y_train), (x_test, y_test), min_pixel_value, max_pixel_value = load_mnist()
defence.fit(x=x_train, y=y_train, nb_epochs=3)
Counterfit
---------------------------------------------------
Microsoft
__ _____ __
_________ __ ______ / /____ _____/ __(_) /_
/ ___/ __ \/ / / / __ \/ __/ _ \/ ___/ /_/ / __/
/ /__/ /_/ / /_/ / / / / /_/ __/ / / __/ / /
\___/\____/\__,_/_/ /_/\__/\___/_/ /_/ /_/\__/
#ATML
---------------------------------------------------
list targets
list frameworks
load <framework>
list attacks
interact <target>
predict -i <ind>
use <attack>
run
scan
Final words
"If you use machine learning, there is the risk for exposure, even though the threat does not currently exist in your space." and "The gap between machine learning and security is definitely there." by
## ReferencesThanks
Special thanks to , co-writer of this article.This article was first published .
L O A D I N G
. . . comments & more!
. . . comments & more!







