visit
Best Practices for Implementing Test Data into Your CI/CD Pipeline by@datprof
1,420 reads
Best Practices for Implementing Test Data into Your CI/CD Pipeline
by DATPROFNovember 2nd, 2021
Too Long; Didn't Read
Test data as a part of software development is the poor relation that has been ignored for far too long. Test data is refreshed at too low a frequency, which can be detrimental to the quality of your product. In many organizations, multiple teams have to share their test database with others. Refreshes cause long waiting time: one data refresh takes 6 days on average. Good quality and fast test data can actually act as an accelerator! So how to implement test data into your CI/CD pipeline?Companies Mentioned
Test data as a part of software development is the poor relation that has been ignored for far too long. That is striking since it’s one of the biggest bottlenecks in software testing. Several studies, including our own , show that:
- Test data is refreshed at too low a frequency, which can be detrimental to the quality
- In many organizations, multiple teams have to share their test database with others
- Refreshes cause long waiting time: one data refresh takes 6 days on average
Compliant Test Data
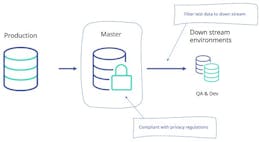
First of all, most testers give preference to production data for testing purposes. That makes perfect sense because when your application tests succeed using a copy of production, you may assume that the application will work in production, too. But when your production data contains personal (customer) information, it may not be used for testing purposes. Various laws and regulations like GDPR, PCI, and HIPAA have established this. So you need to think about an alternative.Actually, there are two options:- Mask the privacy-sensitive data in your test database
- Generate synthetic test data
Exclusive Test Databases
When you’re sure that your test data is compliant and of the right quality, you need to think about who may use which database. The last thing you need is another team messing up your test database while you’re trying to do your job. The ideal world? Each team has its own test database. The reason we don't see this happening often is the costs involved. A full (masked) copy production can easily contain several terabytes of data. Just placing copies everywhere will increase your storage costs enormously.The solution lies in . Using only a small part of a
(masked) production database makes it more feasible to give every test or QA team their own dataset. As a user, you can indicate which data you need for your tests, and the smart subset tool extracts exactly those records and any related records from other tables or systems. This results in a referential intact test data set of maybe only a few percent size.
Self-service Test Data Portal
Last, you want to shorten the time waiting on a refresh. On average, it takes 3.5 people to get a test data refresh, and it takes 6 days on average to actually get the data. This is very outdated. With the help of a self-service test data portal, testers or QA engineers can easily without the interference of a test manager or a database administrator.Imagine what this would mean for your CI/CD pipeline, how much time (and money) can be saved. And not to forget what the impact is on the quality of your product.Conclusion
Good quality test data that is compliant and easily accessible, and refreshable can have a significant impact on your CI/CD pipeline. It will speed up your development and testing processes and helps to achieve the highest possible quality for your product.L O A D I N G
. . . comments & more!
. . . comments & more!