



































visit
Building Handwritten Digits Recognizer using Support Vector Machine by@kavish
2,105 reads
Building Handwritten Digits Recognizer using Support Vector Machine
by KAVISH GOYALOctober 17th, 2020
Too Long; Didn't Read
Building Handwritten Digits Recognizer using Support Vector Machine Machine Machine. The goal of this blog is to find a hyper-calculated machine algorithm that can be used in classification and regression tasks. The aim of this article is to build a machine that can read and interpret an image that uses a handwritten font. We will then use an estimator that is useful in this case is sklearn.svm.sVC, which uses the technique of Support Vector Classification (SVC) The Hypothesis to be tested is that it predicts the digit accurately 95% of the times.Company Mentioned
Handwriting Recognition:
Recognizing handwritten text is a problem that can be traced back to the first automatic machines that needed to recognize individual characters in handwritten documents. Think about, for example, the ZIP codes on letters at the post office and the automation needed to recognize these five digits. Perfect recognition of these codes is necessary in order to sort mail automatically and efficiently.To address this issue in Python, the scikit-learn library provides a good example to better understand this technique, the issues involved, and the possibility of making predictions.
The problem we are solving in this blog involves predicting a numeric value, and then reading and interpreting an image that uses a handwritten font. So even in this case, we will have an estimator with the task of learning through a fit() function, and once it has reached a degree of predictive capability (a model sufficiently valid), it will produce a prediction with the predict() function. Then we will discuss the training set and validation set, created this time from a series of images.The Digits Dataset
The scikit-learn library provides numerous datasets that are useful for testing many problems of data analysis and prediction of the results. Also in this case there is a dataset of images called Digits.
This dataset consists of 1,797 images that are 8x8 pixels in sizeLet's start with importing the dataset from scikit-learn:
from sklearn import datasets ## importing datasets from sklearn
digits = datasets.load_digits() ### loading data from scikit_learn libraryprint(digits.DESCR) ## getting information about the datadigits.images[0]
array([[ 0., 0., 5., 13., 9., 1., 0., 0.],
[ 0., 0., 13., 15., 10., 15., 5., 0.],
[ 0., 3., 15., 2., 0., 11., 8., 0.],
[ 0., 4., 12., 0., 0., 8., 8., 0.],
[ 0., 5., 8., 0., 0., 9., 8., 0.],
[ 0., 4., 11., 0., 1., 12., 7., 0.],
[ 0., 2., 14., 5., 10., 12., 0., 0.],
[ 0., 0., 6., 13., 10., 0., 0., 0.]])We can visually check the contents of this result using the matplotlib library.
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(digits.images[0], cmap=plt.cm.gray_r, interpolation='nearest') ## visualizing image of '0'digits.target ## The numerical values represented by images, i.e. the targets
array([0, 1, 2, ..., 8, 9, 8])
digits.target.size ## total images
1797The Digits data set of scikit-learn library provides numerous data-sets that are useful for testing many problems of data analysis and prediction of the results. Some Scientist claims that it predicts the digit accurately 95% of the times. Perform data Analysis to accept or reject this Hypothesis.
An estimator that is useful in this case is sklearn.svm.SVC, which uses the technique of Support Vector Classification (SVC).As it works with image datasets better compared to other machine learning algorithms.
Support vector machine is one of the simple algorithms that every machine learning expert should have used in his/her arsenal. The Support vector machine is highly preferred by many as it produces significant accuracy with less computation power. Support Vector Machine, abbreviated as SVM can be used for both regression and classification tasks. But, it is widely used in classification objectives.What is Support Vector Machine?
The objective of the support vector machine algorithm is to find a hyperplane in N-dimensional space(N — the number of features) that distinctly classify the data points.
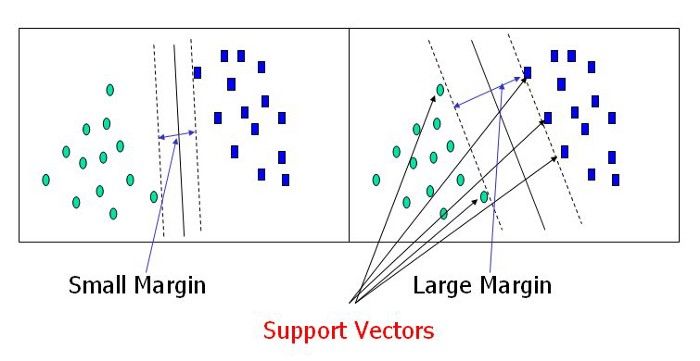
To separate the two classes of data points, there are many possible hyperplanes that could be chosen. Our objective is to find a plane that has the maximum margin, i.e the maximum distance between data points of both classes. Maximizing the margin distance provides some reinforcement so that future data points can be classified with more confidence.
Hyperplanes and Support Vectors:
Hyperplanes are decision boundaries that help classify the data points. Data points falling on either side of the hyperplane can be attributed to different classes. Also, the dimension of the hyperplane depends upon the number of features. If the number of input features is 2, then the hyperplane is just a line. If the number of input features is 3, then the hyperplane becomes a two-dimensional plane. It becomes difficult to imagine when the number of features exceeds 3.
Support vectors are data points that are closer to the hyperplane and influence the position and orientation of the hyperplane. Using these support vectors, we maximize the margin of the classifier. Deleting the support vectors will change the position of the hyperplane. These are the points that help us build our SVM.Large Margin Intuition:In SVM, we take the output of the linear function and if that output is greater than 1, we identify it with one class and if the output is -1, we identify is with another class. Since the threshold values are changed to 1 and -1 in SVM, we obtain this reinforcement range of values([-1,1]) which acts as margin.Cost Function and Gradient Updates:In the SVM algorithm, we are looking to maximize the margin between the data points and the hyperplane. The loss function that helps maximize the margin is hinge loss.
Hinge loss function
Loss function for SVM
Gradients
Gradient update when no misclassification
Gradient Update - MIsclassificationfrom sklearn import svm
svc = svm.SVC(gamma=0.001, C=100.)
This dataset contains 1,797 elements, and so you can consider the first 1,750 as a training set and will use the remaining as a validation set. We can see in detail a few of these remaining handwritten digits by using the matplotlib library:
plt.subplot(321)
plt.imshow(digits.images[1750], cmap=plt.cm.gray_r,
interpolation='nearest')
plt.subplot(322)
plt.imshow(digits.images[1751], cmap=plt.cm.gray_r,
interpolation='nearest')plt.subplot(323)
plt.imshow(digits.images[1780], cmap=plt.cm.gray_r,
interpolation='nearest')
plt.subplot(324)
plt.imshow(digits.images[1784], cmap=plt.cm.gray_r,
interpolation='nearest')
plt.subplot(323)
plt.imshow(digits.images[1795], cmap=plt.cm.gray_r,
interpolation='nearest')
plt.subplot(324)
plt.imshow(digits.images[1796], cmap=plt.cm.gray_r,
interpolation='nearest')
Training the model :
Now we can train the svc estimator that we have defined earlier on the training data.svc.fit(digits.data[:1750], digits.target[:1750]) ## fitting on training set
SVC(C=100.0, gamma=0.001)svc.predict(digits.data[1751:1796]) ## making prediction on validation set
array([2, 1, 7, 4, 6, 3, 1, 3, 9, 1, 7, 6, 8, 4, 3, 1, 4, 0, 5, 3, 6, 9,
6, 1, 7, 5, 4, 4, 7, 2, 8, 2, 2, 5, 7, 9, 5, 4, 8, 8, 4, 9, 0, 8,
9])digits.target[1751:1796]
array([2, 1, 7, 4, 6, 3, 1, 3, 9, 1, 7, 6, 8, 4, 3, 1, 4, 0, 5, 3, 6, 9,
6, 1, 7, 5, 4, 4, 7, 2, 8, 2, 2, 5, 7, 9, 5, 4, 8, 8, 4, 9, 0, 8,
9])Case-1:
print(svc.fit(digits.data[:1790], digits.target[:1790])) ## fitting on training set
print(svc.predict(digits.data[1791:1796])) ## making prediction on validation set
digits.target[1791:1796]
outputs:
SVC(C=100.0, gamma=0.001)
[4 9 0 8 9]
array([4, 9, 0, 8, 9])
Case_2:
print(svc.fit(digits.data[:1700], digits.target[:1700])) ## fitting on training set
print(svc.predict(digits.data[1701:1796])) ## making prediction on validation set
digits.target[1701:1796]
outputs:
SVC(C=100.0, gamma=0.001)
[6 5 0 9 8 9 8 4 1 7 7 3 5 1 0 0 2 2 7 8 2 0 1 2 6 3 8 7 5 3 4 6 6 6 4 9 1
5 0 9 5 2 8 2 0 0 1 7 6 3 2 1 7 4 6 3 1 3 9 1 7 6 8 4 3 1 4 0 5 3 6 9 6 1
7 5 4 4 7 2 8 2 2 5 7 9 5 4 8 8 4 9 0 8 9]
array([6, 5, 0, 9, 8, 9, 8, 4, 1, 7, 7, 3, 5, 1, 0, 0, 2, 2, 7, 8, 2, 0,
1, 2, 6, 3, 3, 7, 3, 3, 4, 6, 6, 6, 4, 9, 1, 5, 0, 9, 5, 2, 8, 2,
0, 0, 1, 7, 6, 3, 2, 1, 7, 4, 6, 3, 1, 3, 9, 1, 7, 6, 8, 4, 3, 1,
4, 0, 5, 3, 6, 9, 6, 1, 7, 5, 4, 4, 7, 2, 8, 2, 2, 5, 7, 9, 5, 4,
8, 8, 4, 9, 0, 8, 9])Case_3:
We will take 80% of data as a training set and 20% as validation.print(svc.fit(digits.data[:1438], digits.target[:1438])) ## fitting on training set
y_pred = svc.predict(digits.data[1438:1796]) ## making prediction on validation set
y_test = digits.target[1438:1796]
from sklearn.metrics import accuracy_score, classification_report
print(accuracy_score(y_test,y_pred))
print(classification_report(y_test,y_pred))
outputs:
0.9636871508379888
precision recall f1-score support
0 1.00 0.97 0.99 35
1 0.97 1.00 0.99 36
2 1.00 1.00 1.00 34
3 1.00 0.84 0.91 37
4 0.97 0.92 0.94 37
5 0.93 1.00 0.96 37
6 1.00 1.00 1.00 37
7 1.00 1.00 1.00 36
8 0.86 0.97 0.91 32
9 0.92 0.95 0.93 37
accuracy 0.96 358
macro avg 0.97 0.96 0.96 358
weighted avg 0.97 0.96 0.96 358
I am thankful to mentors at for providing awesome problem statements and giving many of us a Coding Internship Experience. Thank you
L O A D I N G
. . . comments & more!
. . . comments & more!







