















visit
Cost Effective Data Warehousing: Delta View and Partitioned Raw Table by@handoff
182 reads
Cost Effective Data Warehousing: Delta View and Partitioned Raw Table
by handoff.cloud by ANELENSeptember 17th, 2021
Too Long; Didn't Read
As your data and team grow bigger, the query cost and efficiency become a headache to analytics managers. The use of a partitioned table and the materialized table save you DWH cost and increase the cluster efficiency. Delta views are an efficient way of pulling up-to-date metrics while keeping the query cost low.Companies Mentioned
Introduction
The worst nightmare of analytics managers is accidentally blowing up the data warehouse (DWH) cost. This could happen by accidentally running a query that scans the entire raw table that is huge. Even when the table is not at the petabyte scale, the accumulation of repeated queries could add up to.
- How can we avoid receiving unexpectedly expensive bills from the BigQuery/Athena/Redshift Spectrum?
- How can we keep our queries efficient, so we don't need to increase the over cost from DWH and operational inefficiency?
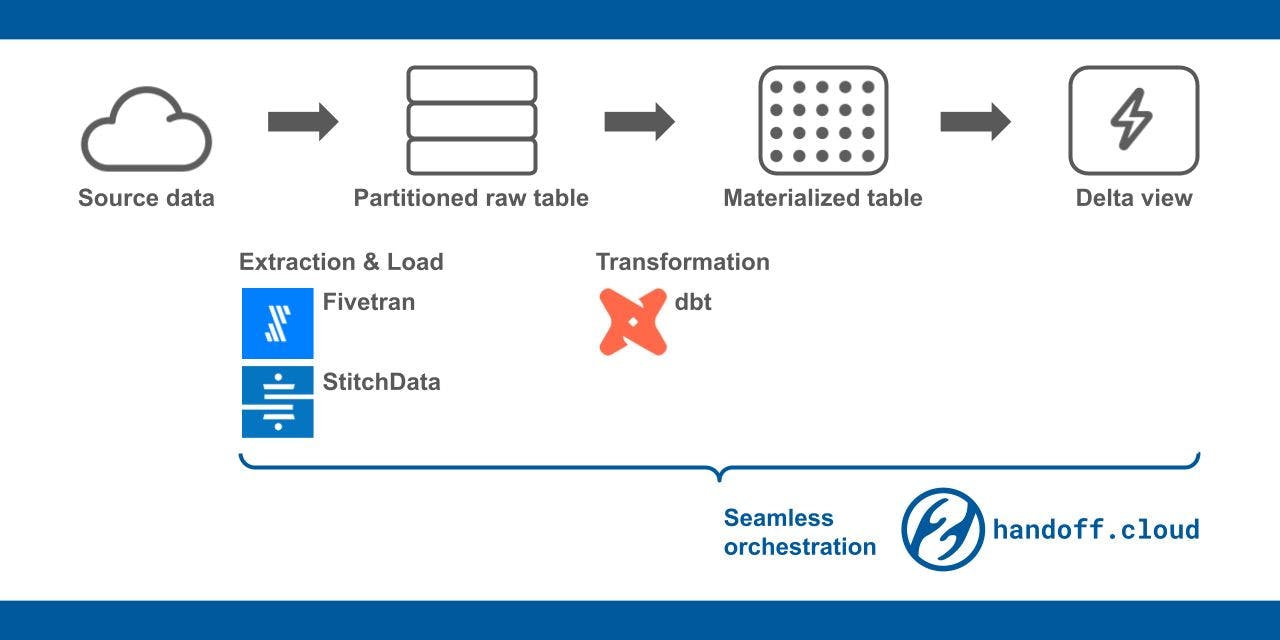
Enforce partitions to the raw tables
The first thing you can do is to enforce partitions on the raw tables. The big tables are almost always tied to the day-to-day ingestion of the raw data. The DWH can internally divide the big data into chunks, typically based on one of the timestamp columns in the table. The smaller chunks in the table are called partitions.
Note: If you are a BigQuery user, loader does this automatically. We can also help you set up partitions for other DWHs. Learn more at handoff.cloud, or just let us know by dropping an email to [email protected].
Set up materialized tables
The raw tables are cleaned and aggregated before they are put to use. You may be doing so by defining SQL views. Such views may be hooked to your dashboard. So, every time someone opens the dashboard, the DWH may be executing a query through the views.
Use delta view to get fresh data efficiently
One problem with the above approach is data freshness. Say, your data extractor (StitchData, Fivetran, Airflow, etc) pulls data from the source every hour but materialization happens daily basis. By accessing the materialized table, you only get yesterday's metrics and of course, you want to peek at today's intra-day progress. The so-called delta view will help you achieve that.
{% macro events_delta(
source_table,
primary_keys,
event_tstamp_key,
etl_tstamp_key,
all_keys=["*"],
historical_table=None,
current_date='current_date()',
lookback=30)
%}
/*
This query block is created by events_delta macro.
1. events_delta checks the (hopefuly partitioned-) destination {{ destination }}
table within the time-window {{ lookback }} (days) since the last ingestion
{{ etl_tstamp_key }}.
2. The new data is identified in source {{ source_table }} table having
{{ etl_tsamp_key }} > the last destination ETL timestamp.
3. If the destination has an entry with the primary key, it will honor the
existing one. So, to replace the old one, you need to drop the partition
(or just that record) before running this query.
Assumption: event time is always older than the etl time
Usage:
{% set primary_keys = ["pk-1", "pk-2", "pk-3",...] %}
{% set all_keys = ["pk-1", "pk-2", "pk-3",..., "non-pk-1", "non-pk-2", "non-pk-3", ...] %}
WITH
source AS (
-- I'm inserting a CTE to demonstrate pre-casting a field before calling the macro
select cast(timestamp as date) as date,
* except(timestamp, date) -- This is a BigQuery dialect
from {{ source('my_schema', 'my_raw_data_table') }}
),
{{ events_delta(
'source',
primary_keys,
'date',
'my_etl_timestamp',
all_keys=all_keys,
historical_table=source('my_schema', 'my_historical_table'),
lookback=30)
}}
select * from events_delta
union all
select * from source('my_schema', 'my_historical_table')
*/
_events_delta_new AS (
SELECT
{% for key in all_keys %}
n.{{ key }}{% if not loop.last %},{% endif %}
{% endfor %}
FROM {{ source_table }} AS n
{% if historical_table %}
LEFT JOIN (
SELECT
{% for key in primary_keys %}
{{ key }}{% if not loop.last %},{% endif %}
{% endfor %}
FROM {{ historical_table }}
WHERE DATE_ADD({{ current_date }}, INTERVAL -{{ lookback }} day) <= CAST({{ event_tstamp_key }} AS DATE)
) AS p
ON 1=1
{% for key in primary_keys %}
AND n.{{ key }} = p.{{ key }}
{% endfor %}
{% endif %}
WHERE DATE_ADD({{ current_date }}, INTERVAL -{{ lookback }} day) <= CAST(n.{{ etl_tstamp_key }} AS DATE)
AND DATETIME_ADD({{ current_date }}, INTERVAL -{{ lookback }} day) < CAST(n.{{ event_tstamp_key }} AS DATETIME)
{% if historical_table %}
{% for key in primary_keys %}
AND p.{{ key }} IS NULL
{% endfor %}
{% endif %}
),
events_delta AS (
SELECT o.*
FROM _events_delta_new AS o
INNER JOIN (
SELECT
{% for key in primary_keys %}
{{ key }},
{% endfor %}
MAX({{ etl_tstamp_key }}) AS {{ etl_tstamp_key }},
FROM _events_delta_new
GROUP BY
{% for key in primary_keys %}
{{ key }}{% if not loop.last %},{% endif %}
{% endfor %}
) AS oo
ON o.{{ etl_tstamp_key }} = oo.{{ etl_tstamp_key }}
{% for key in primary_keys %}
AND o.{{ key }} = oo.{{ key }}
{% endfor %}
)
{% endmacro %}
/* This is the end of the query block generated by events_delta macro */
Seamlessly run extraction and materialization
Delta view works by coordinating data extraction and materialization. You may do so by:
- Schedule data extraction by StitchData, Fivetran, or create a task in Airflow.
- Define delta views. We recommend managing it with dbt with a macro like in the example above.
- Schedule the materialization by DWH's scheduling feature if available or set up a job by yourself.
Note: handoff.cloud can run all 3 steps together whenever the data is replicated. This seamless delta view process resolves the coordination issues and generates the most up-to-date data with the lowest query cost. Plus, our fully customizable service can integrate data from the applications not supported by existing connectors in the market. We can also support more complex ELT logic and custom transformations. Learn more at
Conclusion
As your data and team grow bigger, the query cost and efficiency become a headache to analytics managers. The use of a partitioned table and the materialized table save you DWH cost and increase the cluster efficiency. Delta views are an efficient way of pulling up-to-date metrics while keeping the query cost low.About the author
Daigo Tanaka is CEO and data scientist at ANELEN, a boutique consulting firm focused on data engineering, analytics, and data science. ANELEN’s mission is to help innovative businesses make smarter decisions with data science. ANELEN is the provider of . Also published on:L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES



6 Reasons to Use Amazon Redshift #amazon-redshift
Jul 23, 2021

How Costly is AWS Redshift Serverless? #aws
Oct 04, 2023

