




























visit
Deploying a Terraform Remote State Backend with AWS S3 and DynamoDB by@michaelmekuleyi
9,282 reads
Deploying a Terraform Remote State Backend with AWS S3 and DynamoDB
by monareneFebruary 24th, 2023
Too Long; Didn't Read
The acronym IaC is a short form for the popular DevOps term `Infrastructure As Code` This concept represents the ability to set up networking, hardware, and operating system components in the cloud by writing them as code and code alone. In this article, we are going to be focusing on Terraform, an open-source DevOps tool developed by Hashicorp in 2014. Terraform is used by engineers to deploy infrastructure on multiple Infrastructure providers like Amazon Web services (AWS), Google Cloud Platform (GCP), Azure, Digital Oceans, and over 90 others.
The acronym IaC is a short form for the popular DevOps term Infrastructure As Code. This concept represents the ability to set up networking, hardware, and operating system components in the cloud by writing them as code and code alone. The advantages of IaC include speed, efficiency, consistency, and agility.
Terraform provides a rich interface of platform-agnostic components used across multiple providers to maintain the desired state of infrastructure and also detect changes made in Infrastructure. Terraform makes use of a lightweight dynamic language called Hashicorp Configuration Language (HCL). Terraform also generates a JSON file named terraform.tfstate that stores the state of your managed infrastructure and configuration.
Table of Contents
- Understanding remote state objects
- Setting up your AWS account
- Deploying S3 and DynamoDB infrastructure
- Testing the remote state backend
- Cleaning up
- Conclusion
Understanding remote state objects
In this article, we are going to be deep diving into remote state management in terraform. Terraform state file (terraform.tfstate) ensures that code in the configuration script is a representation of the infrastructure deployed, hence when there is a deployment, the values in the state file change to reflect the new infrastructure that is deployed.
Let’s dive in!
Setting up your AWS account
In this article, we will start from scratch, from setting up an IAM role with the correct permissions down to the final S3 configurations. Kindly note that this is the only time we will be actively setting up configurations in the AWS console, the rest of the journey will be done using Terraform. We will also try to keep resources that we are provisioning within the limits of the free tier so that this tutorial is easy to follow and you don't spend ANY money.
- AWSEC2FullAccess
- AWSDynamoDBFullAccess
- AWSS3FullAccess
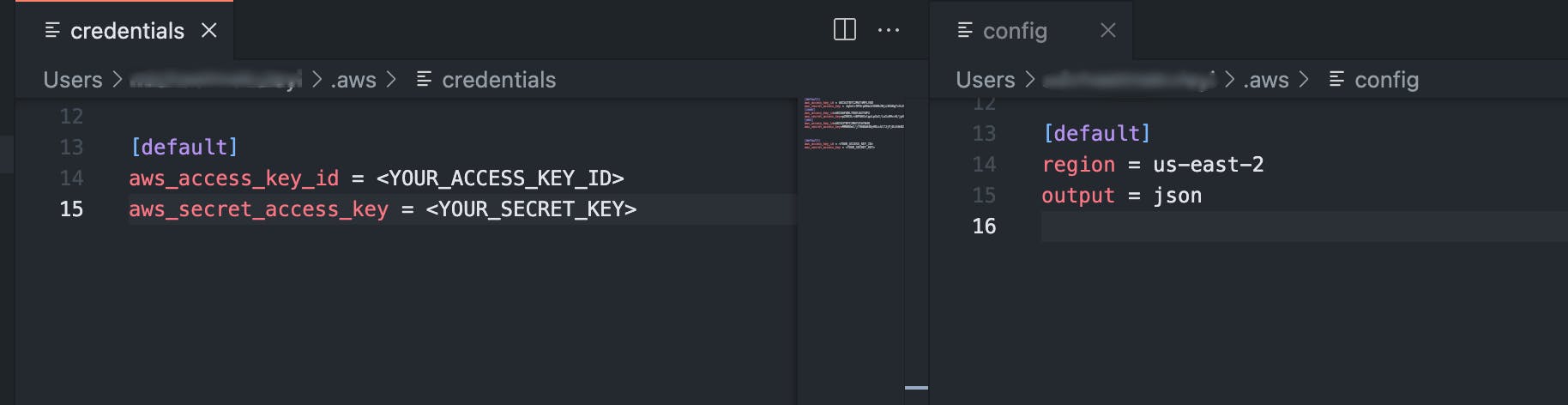
The next step after the above is to set up and configure your credentials on your local computer. You can set this up by editing the AWS config file (located at ~/.aws/config on ) and the AWS credentials file (~/.aws/credentials ).. The picture below shows how your credential file and config file would look when properly set.
Deploying S3 and DynamoDB infrastructure
As aforementioned, we will be using AWS S3 to store the terraform state file (terraform.tfstate) while utilizing a DynamoDB table to store the LockId. Again, the code files for this article can be found .
First, we will deploy the S3 bucket and DynamoDB with our default local state (because we can not store our state files in a bucket that does not exist), then we move the local backend of this base deployment to a remote S3 backend. The final thing to note here is The Golden Rule of Terraform, this rule states that when you start configuration management with terraform, use only terraform. This is to prevent what we call a configuration drift - a phenomenon where the infrastructure present in the configuration script is different from what is in deployment.
Each deployment contains a very generic configuration of main.tf, outputs.tf and variables.tf.
- main.tf: This file contains the core configurations for the deployment, here the terraform version and all the resources to be deployed are explicitly defined.
- outputs.tf: This file contains the defined outputs of the configuration in the main terraform file.
- variables.tf: This file contains the variables that would be used in our configuration, such variables include the name of the server, the name of the S3 bucket, the server port, and information that we would not want to hardcode into our configuration.
Head to global/s3/main.tf and define the terraform block
terraform {
required_version = ">= 1.0.0"
/* backend "s3" {
# Replace this with your bucket name!
bucket = "<YOUR_S3_BUCKET_HERE>"
key = "global/s3/terraform.tfstate"
region= "us-east-2"
# Replace this with your DynamoDB table name!
dynamodb_table = "YOUR_DYNAMODB_TABLE_NAME_HERE"
encrypt = true
} */
}
provider "aws" {
region = "us-east-2"
}
resource "aws_s3_bucket" "terraform_state" {
bucket = var.bucket_name
force_destroy = true
versioning {
enabled = true
}
# Enable server-side encryption by default
server_side_encryption_configuration {
rule {
apply_server_side_encryption_by_default {
sse_algorithm = "AES256"
}
}
}
}
Here we define the bucket and set the force_destroy as true, this means that even when the bucket contains objects if we run terraform destroy the bucket should be completely emptied and deleted. We also set versioning to true so that we can view previous versions of the state file in the bucket. Finally, we enable server-side encryption to protect the contents of our bucket.
resource "aws_dynamodb_table" "terraform_locks" {
name = var.table_name
billing_mode = "PAY_PER_REQUEST"
hash_key = "LockID"
attribute {
name = "LockID"
type = "S"
}
}
Now to define the variables in global/s3/variables.tf
variable "bucket_name" {
description = "The name of the S3 bucket. Must be globally unique."
type = string
default = "<YOUR VARIABLE NAME>"
}
variable "table_name" {
description = "The name of the DynamoDB table. Must be unique in this AWS account."
type = string
default = "terraform-remote-state-dynamo"
}
We go to global/s3/outputs.tf
output "s3_bucket_arn" {
value = aws_s3_bucket.terraform_state.arn
description = "The ARN of the S3 bucket"
}
output "dynamodb_table_name" {
value = aws_dynamodb_table.terraform_locks.name
description = "The name of the DynamoDB table"
}
Here we define the s3_bucket_arn and dynamo_table_nameas outputs and we are ready to deploy.
To start the deployment, we run terraform init to initialize terraform local backend and download all the necessary dependencies.
The next thing here should be to run terraform plan , terraform plan allows us to view the infrastructure that terraform intends to deploy and to make sure that it is the intended result, below are the results of terraform plan
Let's deploy our infrastructure by running terraform apply -auto-approve
As we can see above the infrastructure is deployed and the outputs we defined in the output.tf file are printed here.
As seen above, the s3 bucket has been deployed and is ready for use. The next thing to do is to add the s3 bucket as a remote backend for Terraform, so head over back to global/s3/main.tf and uncomment the remote backend code block, make sure to add your defined s3 bucket and your DynamoDB table.
terraform {
required_version = ">= 1.0.0"
backend "s3" {
# Replace this with your bucket name!
bucket = "<YOUR_S3_BUCKET_HERE>"
key = "global/s3/terraform.tfstate"
region= "us-east-2"
# Replace this with your DynamoDB table name!
dynamodb_table = "YOUR_DYNAMODB_TABLE_NAME_HERE"
encrypt = true
}
}
Next, we run terraform init so that we reinitialize our s3 bucket as our new remote state backend. Terraform will ask if this is the intended action, kindly type 'yes' to proceed.
Terraform will go ahead to automatically use this backend as the preferred backend unless the backend configuration changes. To save the latest change run terraform apply -auto-approve so that the latest change can be saved on the backend.
You can see that at global/s3 we have our terraform state file and it is updated anytime there is a change to the state. This way multiple teams can collaborate on the same configuration management file without the stress of losing work.
Testing the remote state backend
In the second part of this article, we deploy a test web server and we save the state to the s3 bucket, this is just to show that the S3 bucket can contain multiple states depending on the key that is set in the terraform configuration.
Head over to stage/web-server/main.tf and see the terraform configuration block
terraform {
required_version = ">= 1.0.0"
backend "s3" {
# Replace this with your bucket name!
bucket = "<YOUR_S3_BUCKET_HERE>"
key = "stage/web-server/terraform.tfstate"
region= "us-east-2"
# Replace this with your DynamoDB table name!
dynamodb_table = "YOUR_DYNAMODB_TABLE_NAME_HERE"
encrypt = true
}
}
Note that I am always using the path to main.tf as the key of configuration, this is best practice because whoever picks up the project at any point in time knows which configuration file is for what configuration and where to make changes. Remember to head over to stage/web-server/variables.tfto fill in your variable names and also appropriately fill in your S3 bucket name and the DynamoDB table name.
Let's go ahead to start this configuration by running terraform init
After initializing terraform we can go ahead and check the infrastructure that is to be deployed by running terraform plan
Great! The output of terraform plan looks exactly like what we intend our configuration to do, we will go ahead to run terraform apply -auto-approve to deploy the configuration.
Terraform also outputs a public IP address, as defined in the stage/web-server/outputs.tf, Head over to the AWS Console to see the EC2 instance deployed by terraform
To also see that the instance configuration works //<PUBLIC_IP_OF_YOUR_EC2_INSTANCE>:8080, you should see something like the screen below.
Cleaning Up
After successfully deploying the EC2 instance with a remote state backend, it is best you delete all the resources used so that AWS does not charge you indefinitely. Head over to stage/web-server on your local machine and run terraform destroy -auto-approve to clean up all the resources, remember to also check the EC2 console to confirm that the instance has been terminated.
When that is over, head to global/s3 and run terraform destroy -auto-approve to destroy the S3 bucket and delete the DynamoDB table. Note that the state may not refresh since deleting the S3 bucket would mean that there would be no place to store the current state, and that is okay because you would rarely have to clean up the bucket if you are actively using it as a remote backend. Please ensure to confirm that all the resources are deleted and that the slate is clean through the AWS console before you abandon the environment.
Conclusion
In this article, we did a deep dive on terraform remote state backend, How to define your remote state backend, and how to optimize it for collaboration between teams and engineers. In the next article, I will be discussing more topics on configuration management with terraform and how you can leverage infrastructure as code to build out a clean reusable work environment,
L O A D I N G
. . . comments & more!
. . . comments & more!