










































visit
Efficient Data Deduplication: Optimizing Storage Space with NTFS, ZFS, & BTRFS by@ikarin
1,091 reads
Efficient Data Deduplication: Optimizing Storage Space with NTFS, ZFS, & BTRFS
by Iliya KarinJuly 18th, 2023
Too Long; Didn't Read
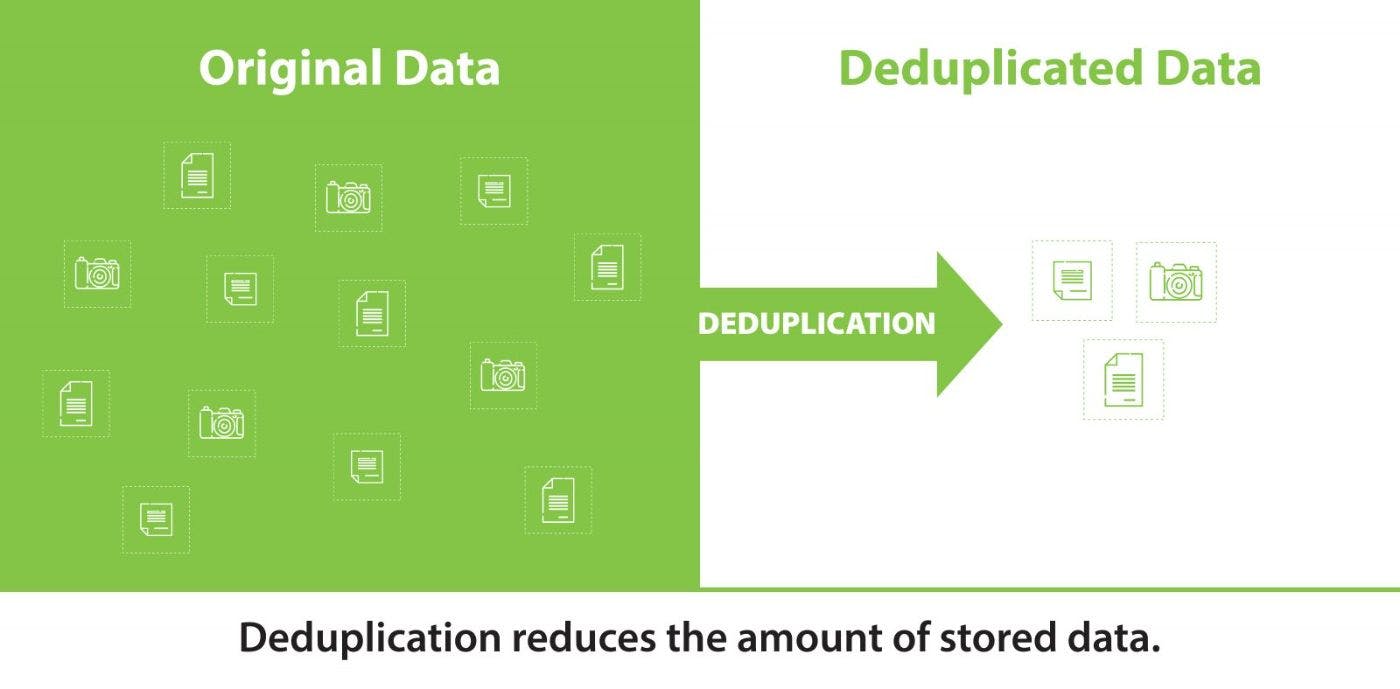
Consider the situation where you possess a vast collection of personal photos stored on your computer. To ensure a backup of these photos, you wish to replicate them onto an external USB HDD. However, due to the immense quantity of photos, they exceed the disk's capacity. While purchasing additional storage is not part of your plan, having some form of backup is crucial. This is where deduplication technology comes into play, offering a viable solution.Deduplication serves a variety of purposes and can be applied in numerous scenarios to address specific challenges effectively.
So, what exactly is deduplication?
Deduplication, in the context of data management, refers to the process of identifying and eliminating duplicate data within a file system. By doing so, deduplication reduces overall data size and mitigates storage costs. It's worth noting that deduplication can also be implemented within databases, although that aspect falls beyond the scope of this article.Types and Variants of Data Deduplication:
Block-level Deduplication:
This method involves identifying redundant data blocks within a file system and retaining only one instance of each unique block. Rather than duplicating these blocks, references to the singular copy are established, resulting in significant savings in disk space.File-level Deduplication:
With file-level deduplication, redundancy is assessed at the file level. The system identifies duplicate files and stores only a single copy of each unique file. Instead of creating duplicate files, the system employs references that point to the shared copy.Content-aware Deduplication at the Block Level:
Content-aware deduplication analyzes the actual content of data blocks to identify duplicates. It can detect and remove identical blocks, even when they are physically scattered across different locations within the file system or exhibit minor discrepancies. Implementations of data deduplication often combine multiple approaches to achieve optimal results.
Our lab environment:
Virtualbox 7.0.4 Host PC: Intel Core i7-10510U CPU 1.80GHz / 2.30 GHz 4 CPU 32GB RAM NVME Samsung SSD 970 EVO Plus 1TB
//www.zabbix.com/download_appliance
Linux ZFS
Initiating the dataset copy process
~$ zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
dedup-pool 119G 104G 15.4G - - 2% 87% 1.00x ONLINE -
$ zpool list
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
dedup-pool 119G 30.6G 88.4G - - 1% 25% 3.39x ONLINE -
Conclusions.
In conclusion, ZFS proves to be an effective solution for optimizing disk space utilization. However, it is crucial to consider the balance between memory and disk resources carefully. Additionally, the type of data being stored and deduplicated plays a significant role in achieving optimal results. By making informed decisions regarding resource allocation and understanding the nature of the data, users can maximize the benefits of ZFS deduplication.Linux BTRFS
Initiating the file copying process:
$ sudo btrfs fi usage /mnt/btrfs_disk
Overall:
Device size: 120.00GiB
Device allocated: 107.02GiB
Device unallocated: 12.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 103.73GiB
Free (estimated): 14.47GiB (min: 7.98GiB)
Free (statfs, df): 14.47GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 112.08MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:105.00GiB, Used:103.51GiB (98.58%)
/dev/sdb 105.00GiB
Metadata,DUP: Size:1.00GiB, Used:113.28MiB (11.06%)
/dev/sdb 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/sdb 16.00MiB
Unallocated:
/dev/sdb 12.98GiB
$ sudo btrfs fi usage /mnt/btrfs_disk
Overall:
Device size: 120.00GiB
Device allocated: 108.02GiB
Device unallocated: 11.98GiB
Device missing: 0.00B
Device slack: 0.00B
Used: 82.30GiB
Free (estimated): 35.88GiB (min: 29.89GiB)
Free (statfs, df): 35.87GiB
Data ratio: 1.00
Metadata ratio: 2.00
Global reserve: 97.64MiB (used: 0.00B)
Multiple profiles: no
Data,single: Size:106.01GiB, Used:82.11GiB (77.46%)
/dev/sdb 106.01GiB
Metadata,DUP: Size:1.00GiB, Used:100.41MiB (9.81%)
/dev/sdb 2.00GiB
System,DUP: Size:8.00MiB, Used:16.00KiB (0.20%)
/dev/sdb 16.00MiB
Unallocated:
/dev/sdb 11.98GiB
Windows NTFS
Initiating the file transfer process to our system:
PS C:\Windows\system32> Get-DedupStatus
FreeSpace SavedSpace OptimizedFiles InPolicyFiles Volume
--------- ---------- -------------- ------------- ------
16.38 GB 0 B 0 0 E:
PS C:\Windows\system32> Get-DedupVolume -Volume E:
Enabled UsageType SavedSpace SavingsRate Volume
------- --------- ---------- ----------- ------
True Default 0 B 0 % E:
PS C:\Windows\system32> Get-DedupProperties -DriveLetter E
InPolicyFilesCount : 0
InPolicyFilesSize : 0
OptimizedFilesCount : 0
OptimizedFilesSavingsRate : 0
OptimizedFilesSize : 0
SavingsRate : 0
SavingsSize : 0
UnoptimizedSize : 0
PSComputerName :
PS C:\Windows\system32> Get-DedupStatus
FreeSpace SavedSpace OptimizedFiles InPolicyFiles Volume
--------- ---------- -------------- ------------- ------
112.85 GB 98.11 GB 377 377 E:
PS C:\Windows\system32> Get-DedupVolume -Volume E:
Enabled UsageType SavedSpace SavingsRate Volume
------- --------- ---------- ----------- ------
True Default 98.11 GB 93 % E:
PS C:\Windows\system32> Get-DedupProperties -DriveLetter E
InPolicyFilesCount : 377
InPolicyFilesSize : 8
OptimizedFilesCount : 377
OptimizedFilesSavingsRate : 94
OptimizedFilesSize : 8
SavingsRate : 93
SavingsSize : 4
UnoptimizedSize : 6
PSComputerName :
Remarkably, the deduplication results proved to be quite impressive. The data size was reduced by an astonishing 93%! As a result, the occupied disk space now stands at a mere 7.13GB, compared to the initial 103GB. This substantial reduction in data volume not only optimizes storage efficiency but also enables significant savings in precious disk space.
Results:
Deduplication proved to be remarkably efficient for my Windows dataset, offering an exceptional data compression ratio - a true dream! However, it's regrettable that Microsoft has imposed proprietary restrictions and limitations that prevent the utilization of deduplication in the regular version of Windows. Unfortunately, this feature is only available in Windows Server.
L O A D I N G
. . . comments & more!
. . . comments & more!






