



















visit
FlashDecoding++: Faster Large Language Model Inference on GPUs: Evaluation by@textmodels
106 reads
FlashDecoding++: Faster Large Language Model Inference on GPUs: Evaluation
by Writings, Papers and Blogs on Text ModelsFebruary 15th, 2024
Too Long; Didn't Read
Due to the versatility of optimizations in FlashDecoding++, it can achieve up to 4.86× and 2.18× speedup on both NVIDIA and AMD GPUs compared to Hugging Face.People Mentioned
This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Ke Hong, Tsinghua University & Infinigence-AI; (2) Guohao Dai, Shanghai Jiao Tong University & Infinigence-AI; (3) Jiaming Xu, Shanghai Jiao Tong University & Infinigence-AI; (4) Qiuli Mao, Tsinghua University & Infinigence-AI; (5) Xiuhong Li, Peking University; (6) Jun Liu, Shanghai Jiao Tong University & Infinigence-AI; (7) Kangdi Chen, Infinigence-AI; (8) Yuhan Dong, Tsinghua University; (9) Yu Wang, Tsinghua University.Table of Links
- Abstract & Introduction
- Backgrounds
- Asynchronized Softmax with Unified Maximum Value
- Flat GEMM Optimization with Double Buffering
- Heuristic Dataflow with Hardware Resource Adaption
- Evaluation
- Related Works
- Conclusion & References
6 Evaluation
6.1 Experiments Setup
We evaluate the performance of FlashDecoding++ on different GPUs with various Large Language Models. We compare the performance with several state-of-the-art LLM inference engines.
6.1.1 Hardware Platforms
We evaluate the performance of FlashDecoding++ and other LLM engines on both NVIDIA and AMD platforms to make a comprehensive comparison. We choose two different GPUs for each platform: Tesla A100 and RTX3090 for NVIDIA, MI210 and RX7900XTX for AMD. We show the detailed configuration in Table 1.6.1.2 LLM Engine Baselines
We implement our FlashDecoding++ using the Pytorch-based front-end with the C++ and CUDA backend for NVIDIA GPUs while ROCm for AMD GPUs. We compare the inference performance in both prefill phase and decode phase with the following LLM engine baselines: Hugging Face (HF) [35], vLLM [11], DeepSpeed [9], TensorRT-LLM [14], OpenPPL [12], and FlashAttention2/FlashDecoding [19, 13]. These baselines are introduced in Section 7.6.1.3 Models
We evaluate the performance of FlashDecoding++ with other LLM inference engines on three typical Large Language Models: Llama2, OPT, and ChatGLM2. Table 2 shows the detailed configuration of these models. Note that there may be several models in one LLM (e.g., Llama2-7B, Llama2-13B) with different configurations (e.g., number of heads and layers).
• Llama2 [1] is a mainstream open-source LLM set released by Meta in 2023. It is a collection of pretrained and fine-tuned generative text models ranging in scale from 7B to 70B parameters.
• OPT [36], is a suite of decoder-only pre-trained transformers ranging from 125M to 175B parameters released by Meta AI.
• ChatGLM2 [37] is an open-source LLM supporting bilingual (Chinese-English) chat.
6.2 Comparison with State-of-the-art
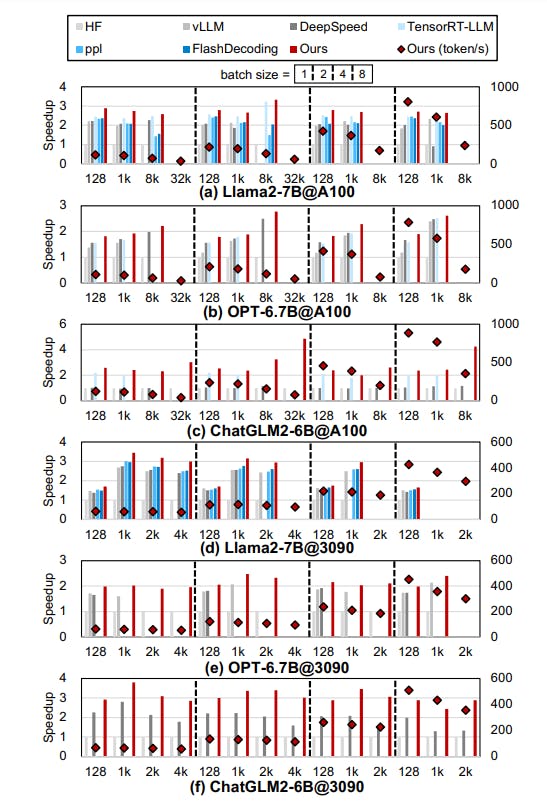
We compare FlashDecoding++ with state-of-the-art LLM inference engines in Figure 10 and Figure 11 on NVIDIA GPUs, Figure 12 and Figure 13 for AMD GPUs. For the decode phase, FlashDecoding++ achieves up to 4.86× speedup compared with Hugging Face implementations on three LLMs and two GPUs. The average speedup over vLLM, DeepSpeed, TensorRT-LLM, OpenPPL, and FlashDecoding is 1.25×, 1.48×, 1.12×, 1.34×, and 1.24× (1.37× on Tesla A100 compared with FlashDecoding), respectively. For the prefill phase, FlashDecoding++ achieves up to 1.40× speedup compared with Hugging Face implementations. The average speedup over DeepSpeed, TensorRT-LLM, OpenPPL, FlashAttention2 and FlashDecoding is 1.05×, 1.06×, 1.08×, 1.09×, and 1.08×, respectively. We also show the decode results on two AMD GPUs. Currently, only the original Hugging Face implementation can be executed on AMD GPUs as the baseline. FlashDecoding++ achieves up to 2.08× and 2.18× compared with the baseline on RX7900XTX and MI210, respectively.
L O A D I N G
. . . comments & more!
. . . comments & more!







