

























visit
From Git Flow to CI/CD: A Practical Guide to Implement Git Workflow by@keviny
9,438 reads
From Git Flow to CI/CD: A Practical Guide to Implement Git Workflow
by Kevin YangJuly 11th, 2023
Too Long; Didn't Read
How to evaluate and improve your current Git workflow, and reduce overhead in development and release processes.
Table of Contents
- Introduction
- A Git Branching Model from Vincent Driessen
- Drawbacks of Git Flow
- Improvements on Git Flow
- Continuous Integration (CI) and Continuous Delivery (CD)
- Semantic Versioning
- Git Tagging
- Git Tagging and Semantic Versioning in Practice
- How to Implement a Better Git Workflow
Introduction
In today’s fast-paced and ever-evolving software development landscape, Git, a version control system, plays a crucial role in enabling collaborative software development, tracking the entire history of codebase changes, and facilitating error recovery. It has become a must-know skill for every developer.
In this guide, I would like to share my understanding of Git branching models, starting from the classic Git Flow proposed by Vincent Driessen in 2010 and progressing to the more contemporary . I will analyze the drawbacks of Git Flow and demonstrate how GitHub Flow mitigates these issues. Additionally, I will introduce some practices, including / , , and .
A Git Branching Model from Vincent Driessen
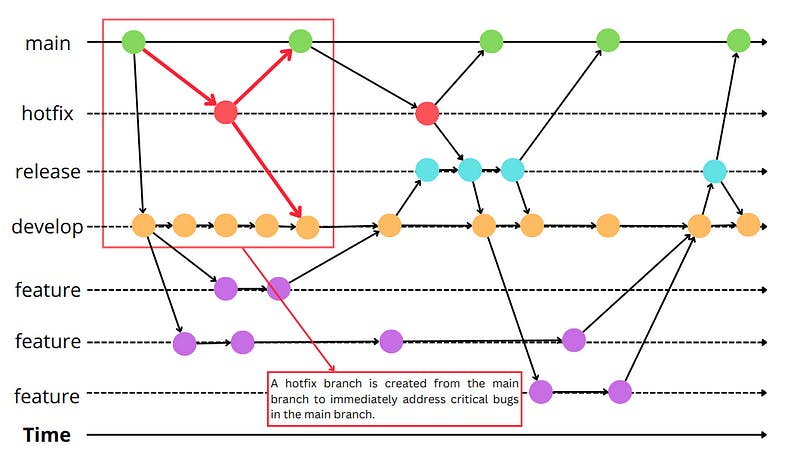
Vincent introduced a branching model that designates various branches, including main (or master), develop, feature, release, and hotfix, each with a specific purpose. Since the original post has already provided a detailed explanation of the workflow, I will focus on highlighting the key points of each branch and illustrating the relationships between them.
The main branch represents the production-ready state of the codebase. Each time changes are merged back into the main branch, it signifies a new production release. On the other hand, the develop branch reflects the latest changes intended for the next release. Also, this is where nightly builds are built from.
To develop a new feature, it is recommended to create a feature branch by branching off from the develop branch. Once the feature implementation is complete, the feature branch should be merged back into the develop branch.
A release branch is created from the develop branch when the develop branch reaches the desired state for the new release. It is used to prepare for a new production release, incorporating bug fixes and last-minute changes. The release branch is eventually merged into both the main and develop branches, and a tag is added to the main branch to mark the release. Merging the release branch into the develop branch ensures that the develop branch includes any last-minute changes made in the release branch. This ensures that future releases and feature implementations will also incorporate these changes.
The hotfix branches are created to immediately address critical bugs in the main branch, which represents the live production version. They are created from the tagged commit on the main branch corresponding to the production version. Once the hotfix is complete, it should be merged into both the main and develop branches. The reason for merging it into the develop branch is to ensure that future releases also include the bugfix.
However, if a release branch exists, the hotfix changes should be merged into that specific release branch instead of the develop branch because the fixes will eventually be merged into the develop branch when the release branch is finished. Meanwhile, the upcoming release can also include the changes to fix the issues in the next production version.
Drawbacks of Git Flow
Git Flow appears to effectively manage new feature development, bug fixes, and the creation of stable releases. However, reviewing the process once more, we can see that managing multiple branches in Git Flow can introduce complexity, especially when it comes to the process of releasing new features. The process of incorporating new features into a release can become complex when there is a need to release multiple features at the same time. Developers would have to check the develop branch, merge the release with the required features, and potentially exclude certain features, which can lead to increased coordination efforts and potential conflicts.
Also, a feature branch can remain active for an extended period of time, and it gradually becomes a long-lived feature branch. As you start working on a new feature, you create a feature branch to implement it. However, as the development progresses, you encounter some challenges that require additional time and effort to overcome, such as dependency on external factors or the complexity of the feature. During this time, other changes are pushed to the develop branch, and the longer your feature branch exists, the greater the risk of encountering merge conflicts and difficulties in keeping the branch up-to-date.
Moreover, in Git Flow, the integration and testing typically occur after feature branches are merged into the develop branch. This pattern introduces delays in the integration and testing phase, increasing the likelihood of encountering conflicts, compatibility issues, or bugs. Thus, it can lead to additional time spent on debugging and fixing issues. Moreover, the delay in testing can extend the feedback loop between developers and testers.
Improvements on Git Flow
As discussed above, the main drawbacks of Git Flow are the complexity of its branching model and the delayed feedback loop. It also provides us with ideas to mitigate these problems.
- A simpler branching model
- Testing at an early stage to shorten the feedback loop
GitHub flow simplifies Git Flow’s branching model by eliminating the complexity associated with managing multiple long-lived branches such as feature, release, and potentially hotfix. Instead, it emphasizes the use of feature branches for specific tasks or fixes.
Additionally, it promotes code reviews through the use of Pull Requests (PR), allowing team members to provide feedback, suggest improvements, and catch potential issues earlier in the development cycle.
Furthermore, it incorporates Continuous Integration (CI) to enable automated testing on the code changes in the pull requests. This ensures that new features or fixes are thoroughly tested before they are merged into the main branch.
Continuous Integration (CI) and Continuous Delivery (CD)
Now, let’s shift our focus from the branching model to practices that can further streamline the development process and release management. As mentioned earlier, Continuous Integration automates testing to help developers identify issues early on. Continuous Integration refers to the practice of developers testing and building their code changes as frequently as possible. The purpose of CI is to shorten the development feedback loop and detect errors and problems as early as possible in the development process.
CI is typically implemented using pipelines that run periodically or are triggered when a developer pushes a code change. The code section below demonstrates a part of the CI pipeline that executes unit tests on code changes triggered by three events: 1.) push to the main branch, 2.) opening a pull request, and 3.) manual triggering.
name: unit-test
on:
push:
branches: [main]
pull_request:
workflow_dispatch:
env:
POETRY_VERSION: "1.5.1"
jobs:
build:
runs-on: ubuntu-20.04
strategy:
matrix:
python-version: ["3.8", "3.9", "3.10", "3.11"]
test_type: ["unit"]
name: Python ${{ matrix.python-version }}
steps:
- uses: actions/checkout@v3
- name: Set up Python ${{ matrix.python-version }}
uses: "./.github/actions/poetry_setup"
with:
python-version: ${{ matrix.python-version }}
poetry-version: "1.4.2"
cache-key: ${{ matrix.test_type }}
install-command: |
if [ "${{ matrix.test_type }}" == "unit" ]; then
echo "Running unit tests, installing dependencies with poetry..."
poetry install
fi
- name: Run ${{ matrix.test_type }} tests
run: |
if [ "${{ matrix.test_type }}" == "unit" ]; then
make test
fi
shell: bash
The abbreviation CD typically refers to Continuous Delivery or Continuous Deployment. Although these terms are often used interchangeably, in this guide, we distinguish between them as separate practices. Continuous Delivery refers to the ability to release code at any time, specifically releasing it as a specific artifact. For instance, you can automate the process of distributing your build artifacts from the CI pipeline to designated locations like Docker Hub or PyPI. The objective of CD is to ensure the frequent and reliable release of your production-ready codebase.
Semantic Versioning
Semantic Versioning is a versioning schema used for software that provides meaning to version numbers. It follows the format: MAJOR.MINOR.PATCH. The purpose of semantic versioning is to provide developers, users, and systems with a clear understanding of the nature of changes between different versions of software. It allows developers to effectively communicate the impact and compatibility of new versions, making it easier for users to decide when to upgrade and ensuring compatibility with dependent libraries and systems. The provides a detailed guideline for creating version numbers. In simple terms, the version number MAJOR.MINOR.PATCH follows these principles:
MAJOR: Increment this number when making incompatible API changes. It indicates that the new version may not be backward compatible with the previous version. Major version changes often involve significant updates, redesigns, or new features.MINOR: Increment this number when adding functionality in a backward-compatible manner. It indicates that the changes are added to the software in a way that maintains compatibility with the previous version’s interface and functionality.PATCH: Increment this number when making backward-compatible bug fixes. It indicates that the new version only includes fixes to address issues in the previous version without introducing new features or breaking changes.
Git Tagging
In Git, tagging refers to the action of creating a label that is associated with a specific commit. A tag serves as a reference point that allows developers and users to easily identify and access specific versions of the codebase. In practice, people use this functionality to mark release points (i.e., when changes merged into the main branch).
In software release management, each tagged commit represents a stable and well-defined version of the software that is ready for deployment or distribution. It is recommended to tag a commit using a version number specified by the Semantic Versioning Specification. As mentioned before, the version numbers help developers understand the impact and compatibility of a new release.
Git supports two types of tags: lightweight and annotated. A lightweight tag is a simple pointer to a specific commit, while an annotated tag is an object that includes a tagging message and additional metadata such as the tagger name, email, and date. It is recommended to create annotated tags so you can have all the information.
Git Tagging and Semantic Versioning in Practice
In many open-source projects, such as and , you can see tag is commonly used to manage package releases.
How to Implement a Better Git Workflow?
In this guide, we have explained a classic branching model, analyzed its drawbacks, and brainstormed about its improvement. Additionally, we have discussed practices such as CI/CD, Semantic Versioning, and Git tagging. When considering the implementation of a Git workflow, it is important not to view a specific model or pattern as a one-size-fits-all solution. Instead, careful analysis of project requirements is necessary. Factors to consider include project complexity, frequency of creating new releases, testing duration (e.g., testing a long-running data pipeline versus testing a connection to an external database), and more.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES




Play-to-Earn Games: Fad or Promising Future? #gaming
Oct 14, 2024


10 GitHub Repositories to Follow #git
Jun 06, 2021

