





















visit
High Availability: Concepts and Theory by@dclinton
10,019 reads
High Availability: Concepts and Theory
by David ClintonOctober 23rd, 2017
Too Long; Didn't Read
<em>This article is adapted from chapter 7 of my book, </em><a href="//bootstrap-it.com/index.php/books/" target="_blank"><em>Teach Yourself Linux Virtualization and High Availability: prepare for the LPIC-3 304 certification exam</em></a><em>.</em>Companies Mentioned
This article is adapted from chapter 7 of my book, .
Let’s focus more on some of the larger architectural principles of cluster management than on any single technology solution. We get to see some actual implementations later - and you can learn a lot about how this works on Amazon’s AWS in my from Manning. But for now, let’s first make sure we’re comfortable with the basics. Running server operations using clusters of either physical or virtual computers is all about improving both reliability and performance over and above what you could expect from a single, high-powered server. You add reliability by avoiding hanging your entire infrastructure on a single point of failure (i.e., a single server). And you can increase performance through the ability to very quickly add computing power and capacity by scaling up and out.
Node: A single machine (either physical or virtual) running server operations independently on its own operating system. Since any single node can fail, meeting availability goals requires that multiple nodes operate as part of a cluster.
Cluster: Two or more server nodes running in coordination with each other to complete individual tasks as part of a larger service, where mutual awareness allows one or more nodes to compensate for the loss of another.
Server failure: The inability of a server node to respond adequately to client requests. This could be due to a complete crash, connectivity problems, or because it has been overwhelmed by high demand.
Failover: The way a cluster tries to accommodate the needs of clients orphaned by the failure of a single server node by launching or redirecting other nodes to fill a service gap.
Failback: The restoration of responsibilities to a server node as it recovers from a failure.
Replication: The creation of copies of critical data stores to permit reliable synchronous access from multiple server nodes or clients and to ensure they will survive disasters. Replication is also used to enable reliable load balancing.
Redundancy: The provisioning of multiple identical physical or virtual server nodes of which any one can adopt the orphaned clients of another one that fails.
Split brain: An error state in which network communication between nodes or shared storage has somehow broken down and multiple individual nodes, each believing it’s the only node still active, continue to access and update a common data source. While this doesn’t impact shared-nothing designs, it can lead to client errors and data corruption within shared clusters.
Fencing: To prevent split brain, the stonithd daemon can be configured to automatically shut down a malfunctioning node or to impose a virtual fence between it and the data resources of the rest of a cluster. As long as there is a chance that the node could still be active, but is not properly coordinating with the rest of the cluster, it will remain behind the fence. Stonith stands for “Shoot the other node in the head”. Really.
Quorum: You can configure fencing (or forced shutdown) to be imposed on nodes that have fallen out of contact with each other or with some shared resource. Quorum is often defined as more than half of all the nodes on the total cluster. Using such defined configurations, you avoid having two subclusters of nodes, each believing the other to be malfunctioning, attempting to knock the other one out.
Disaster Recovery: Your infrastructure can hardly be considered highly available if you’ve got no automated backup system in place along with an integrated and tested disaster recovery plan. Your plan will need to account for the redeployment of each of the servers in your custer.
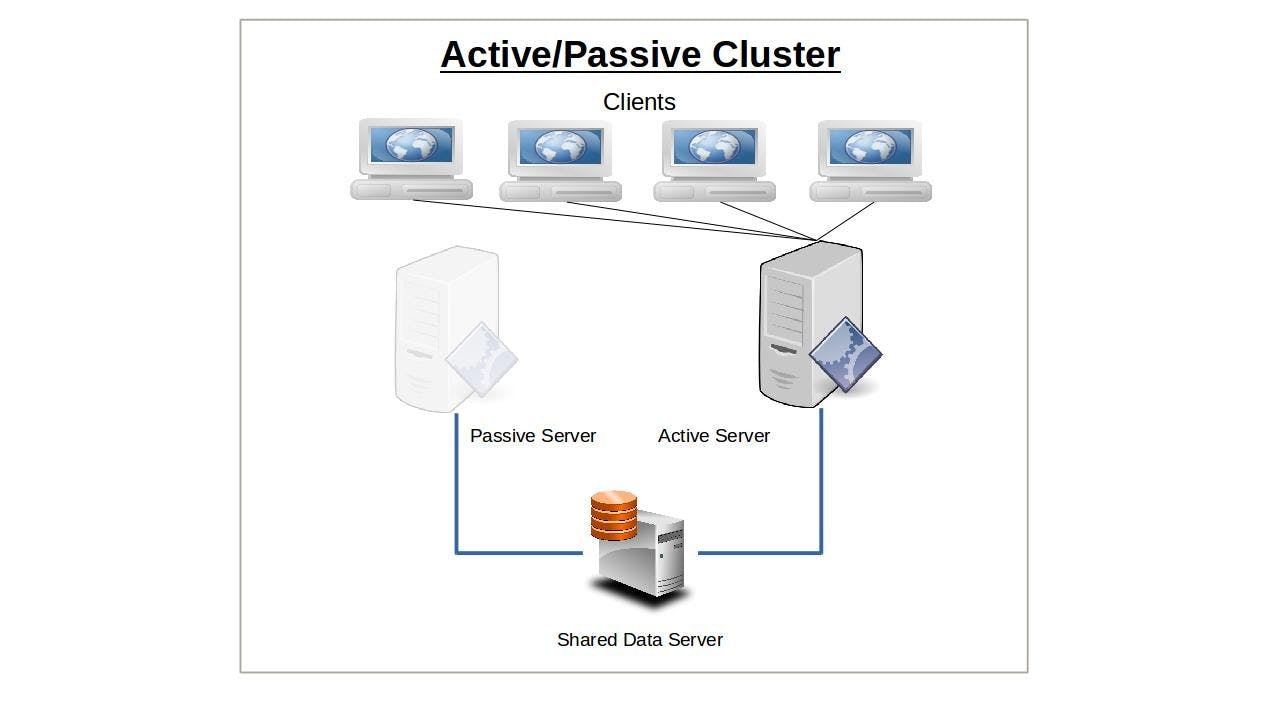
Active/Passive Cluster
The idea behind service failover is that the sudden loss of any one node in a service cluster would quickly be made up by another node taking its place. For this to work, the IP address is automatically moved to the standby node in the event of a failover. Alternatively, network routing tools like load balancers can be used to redirect traffic away from failed nodes. The precise way failover happens depends on the way you have configured your nodes. Only one node will initially be configured to serve clients, and will continue to do so alone until it somehow fails. The responsibility for existing and new clients will then shift (i.e., “failover”) to the passive — or backup — node that until now has been kept passively in reserve. Applying the model to multiple servers or server room components (like power supplies), n+1 redundancy provides just enough resources for the current demand plus one more unit to cover for a failure.
Active/Active Cluster
A cluster using an active/active design will have two or more identically configured nodes independently serving clients.Should one node fail, its clients will automatically connect with the second node and, as far as resources permit, receive full resource access.
Once the first node recovers or is replaced, clients will once again be split between both server nodes. The primary advantage of running active/active clusters lies in the ability to efficiently balance a workload between nodes and even networks. The load balancer — which directs all requests from clients to available servers — is configured to monitor node and network activity and use some predetermined algorithm to route traffic to those nodes best able to handle it. Routing policies might follow a round-robin pattern, where client requests are simply alternated between available nodes, or by a preset weight where one node is favored over another by some ratio. Having a passive node acting as a stand-by replacement for its partner in an active/passive cluster configuration provides significant built-in redundancy. If your operation absolutely requires uninterrupted service and seamless failover transitions, then some variation of an active/passive architecture should be your goal.
Shared-Nothing vs. Shared-Disk Clusters
One of the guiding principles of distributed computing is to avoid having your operation rely on any single point of failure. That is, every resource should be either actively replicated (redundant) or independently replaceable (failover), and there should be no single element whose failure could bring down your whole service. Now, imagine that you’re running a few dozen nodes that all rely on a single database server for their function. Even though the failure of any number of the nodes will not affect the continued health of those nodes that remain, should the database go down, the entire cluster would become useless. Nodes in a shared-nothing cluster, however, will (usually) maintain their own databases so that — assuming they’re being properly synced and configured for ongoing transaction safety — no external failure will impact them. This will have a more significant impact on a load balanced cluster, as each load balanced node has a constant and critical need for simultaneous access to the data. The passive node on a simple failover system, however, might be able to survive some time without access.
While such a setup might slow down the way the cluster responds to some requests — partly because fears of split-brain failures might require periodic fencing through stonith — the trade off can be justified for mission critical deployments where reliability is the primary consideration.
Availability
When designing your cluster, you’ll need to have a pretty good sense of just how tolerant you can be of failure. Or, in other words, given the needs of the people or machines consuming your services, how long can a service disruption last before the mob comes pouring through your front gates with pitch forks and flaming torches. It’s important to know this, because the amount of redundancy you build into your design will have an enormous impact on the down-times you will eventually face. Obviously, the system you build for a service that can go down for a weekend without anyone noticing will be very different from an e-commerce site whose customers expect 24/7 access. At the very least, you should generally aim for an availability average of at least 99% — with some operations requiring significantly higher real-world results. 99% up time would translate to a loss of less than a total of four days out of every year. There is a relatively simple formula you can use to build a useful estimate of Availability (A). The idea is to divide the Mean Time Before Failure by the Mean Time Before Failure plus Mean Time To Repair. A = MTBF / (MTBF + MTTR) The closer the value of A comes to 1, the more highly available your cluster will be. To obtain a realistic value for MTBF, you’ll probably need to spend time exposing a real system to some serious punishment, and watching it carefully for software, hardware, and networking failures. I suppose you could also consult the published life cycle metrics of hardware vendors or large-scale consumers like Backblaze to get an idea of how long heavily-used hardware can be expected to last. The MTTR will be a product of the time it takes your cluster to replace the functionality of a server node that’s failed (a process that’s similar to, though not identical with, disaster recovery — which focuses on quickly replacing failed hardware and connectivity). Ideally, that would be a value as close to zero seconds as possible.Server Availability The problem is that, in the real world, there are usually far too many unknown variables for this formula to be truly accurate, as nodes running different software configurations and built with hardware of varying profiles and ages will have a wide range of life expectancies. Nevertheless, it can be a good tool to help you identify the cluster design that’s best for your project. With that information, you can easily generate an estimate of how much overall downtime your service will likely in the course of an entire year. A related consideration, if you’re deploying your resources on a third-party platform provider like VMWare or Amazon Web Services, is the provider’s Service Level Agreement (SLA). Amazon’s EC2, for instance, guarantees that their compute instances and block store storage devices will deliver a Monthly Uptime Percentage of at least 99.95% — which is less than five hours’ down time per year. AWS will issue credits for months in which they missed their targets — though not nearly enough to compensate for the total business costs of your downtime. With that information, you can arrange for a level of service redundancy that’s suitable for your unique needs. Naturally, as a service provider to your own customers, you may need to publish your own SLA based on your MTBF and MTTR estimates.
Session Handling
For any server-client relationship, the data generated by stateful HTTP sessions needs to be saved in a way that makes it available for future interactions. Cluster architectures can introduce serious complexity into these relationships, as the specific server a client or user interacts with might change between one step and the next. To illustrate, imagine you’re logged onto Amazon.com, browsing through their books on LPIC training, and periodically adding an item to your cart (hopefully, more copies of this book). By the time you’re ready to enter your payment information and check out, however, the server you used to browse may no longer even exist. How will your current server know which books you decided to purchase?
This article is adapted from “”. Check out my , including and — a hybrid course made up of more than two hours of video and around 40% of the text of Linux in Action.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES



105 Stories To Learn About K8s #k8s
Aug 14, 2023




