































visit
How to Build a Reddit Clone with React and Dgraph Cloud by@thawkin3
500 reads
How to Build a Reddit Clone with React and Dgraph Cloud
by Tyler HawkinsMay 11th, 2021
Too Long; Didn't Read
How to Build a Reddit clone with React and Dgraph Cloud makes it easy for frontend developers to get exactly the data they need for each page of their app. The demo app we’ll be using throughout the rest of the article is Readit. The app is built using React for the UI, React Router for the client-side routing. Dgraph is a native GraphQL graph database built for the cloud. The code for this app can be found on GitHub, all of the code can also be found here.Company Mentioned
Social media apps are perfect candidates for using graph databases and GraphQL APIs. The combinations of complex data queries and relationships are endless.Take Reddit for example. The app consists of “subreddits”, or topics. Users can create posts in these subreddits, which means that there is a many-to-one relationship between posts and subreddits. Each post belongs to exactly one subreddit, and each subreddit can contain many posts. Users can comment on posts, leading to another many-to-one relationship between posts and comments. Each comment belongs to exactly one post, and each post can have many comments. There is also a many-to-one relationship between users and posts and between users and comments. Each comment and post is made by a single user, and a single user can have many comments and posts.In an app like Reddit, each page of the app requires different subsets of this data. Using traditional REST API endpoints could mean developing several unique endpoints each tailored to meet the needs of a specific use case. GraphQL APIs, however, are based around the idea of having a single API endpoint that developers can use to pick and choose the relevant pieces of data they need for any given page.This article will highlight the flexibility of GraphQL and how easy using a hosted backend from makes it for frontend developers to get exactly the data they need for each page of their app.
Demo App — Readit
The we’ll be using throughout the rest of the article is Readit, a Reddit clone, but for book lovers (…get it?). The app is built using:- for the UI
- for the client-side routing
- for the GraphQL backend and database
- for facilitating the communication between the frontend and the backend
Node relationships in the graph
The app contains routes for viewing the home page, viewing a single subreadit, viewing a specific post, and viewing an individual user. Here we see the home page:Readit home page
If you’d like to follow along at home or try this out on your machine, all of the . You can also .Configuring the Dgraph Cloud Backend
Now that we have an overview of the app, let’s get started. First, we’ll create a backend with . For those not familiar with this service, Dgraph is a native GraphQL graph database built for the cloud.With a little configuration, you get a graph database as well as an API endpoint for working with your database. Dgraph’s free tier is great for learning and getting started, so that’s what I used. More advanced features like shared and dedicated clusters are available on additional paid tiers if you need to make your backend production-ready.After signing in to our account, we click the “Launch a new backend” button, which will bring up the following setup page:Configuring a new Dgraph Cloud backend
Since this is a demo app, we can choose the Starter option for the product type. Production apps should use a higher tier with a shared or dedicated instance though. I left my region as “us-west-2”, since that’s the region closest to me. I used “reddit-clone” for the name, but feel free to use whatever you like.After filling out all the options, we can click “Launch” to spin up the new backend. Once the backend has been created, we’ll see an overview page with the new backend API endpoint:New backend API endpoint
Now it’s time to build a schema. This schema declares the various types of data that we’ll be working with in our app and storing in our database. We can either enter our schema info directly in the Schema Editor, or, for a more interactive experience, use UI Mode. Let’s use UI Mode to create our schema. The GUI helps us configure our types, their fields, and even the relationship between various types and fields.Creating a schema in UI Mode
After creating the schema, we can click the “Deploy” button to make it official. If we now look at the Schema Editor view, we’ll see the resulting GraphQL snippet:As you can see, each field has an associated type. For instance, the
CommentidcommentContentvoteCountuserpostThe relationship between the comment and the user is designated by the
@hasInverseCommentUsercommentsUserYou’ll also notice that a few of our fields include the
@searchnameuserNameConfiguring the Frontend
Now that we have the backend created, we can move along to building the frontend. We’ll use to generate a skeleton app as a starting point and then continue to build upon the app from there.yarn create react-app reddit-clone
cd reddit-cloneNext, we’ll install
react-router-domyarn add react-router-domUsing React Router, we can create routes for each of our pages: home, subreadit, post, and user. Below is the
AppThen, we’ll install a couple of packages for , which is a JavaScript state management library for working with GraphQL. While it’s possible to make requests to a GraphQL API endpoint directly using something like the
fetchyarn add @apollo/client graphql(You’ll note that we’ve installed the
graphql@apollo/clientgraphqlgraphqlpeerDependency@apollo/clientAnd then we can wrap our main
AppApolloProviderindex.jsHome Page
Now that we have our routing set up and Apollo ready to go, we can begin building the pages for each of our routes. The home page shows a list of popular subreadits and a list of popular users.Readit home page
We can query our endpoint for that information and then use Apollo to declaratively handle the
loadingerrorresponseHomePageNote how when retrieving the user info, we don’t need to fetch all of the user’s posts and comments. The only thing we’re interested in for the home page is how many posts and how many comments each user has. We can use the
countpostsAggregatecommentsAggregateSubreadit Page
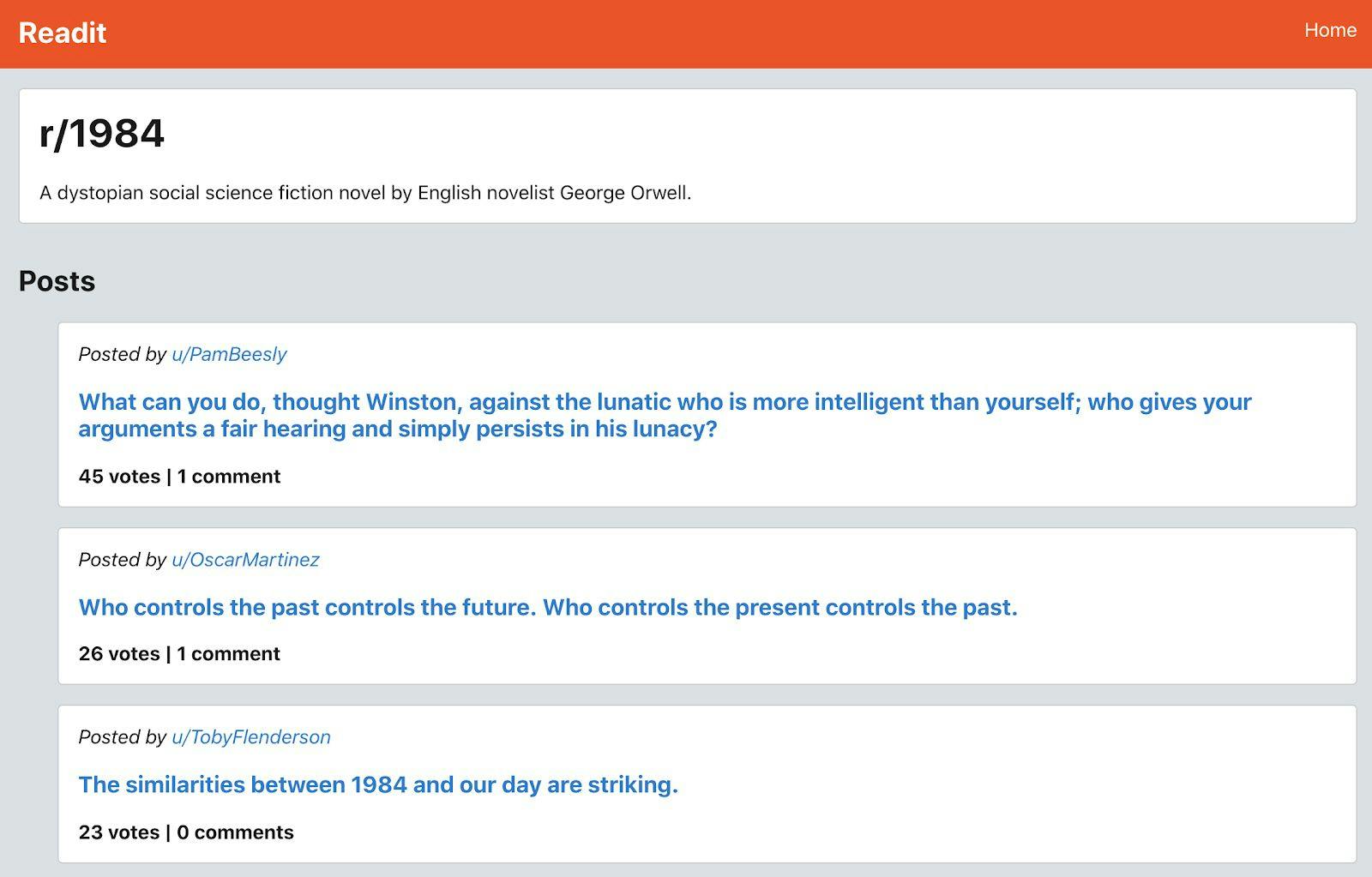
If we click on one of the subreadits from the home page, we’ll be taken to that particular subreadit’s page where we can see all the posts under that topic.Readit subreadit page for the 1984 subreadit
On this page, we need the data for the subreadit name and description, just like we did on the home page. We now also need to fetch all of the posts that are part of this subreadit. For each post, we need the post title, the number of votes and comments, and the username of the user who posted it. We don’t need the actual comments yet though since they’re not displayed on this page.Here’s the code for the
SubreaditPagePost Page
Once we’ve found an interesting post we’d like to view, we can click on the link to view the individual post page. This page shows us the original post as well as all of the comments on the post.Readit post page for Oscar’s post
Here we need all the same post data that we did on the subreadit page, but now we also need to know the subreadit it was posted on, and we need all of the comments on the post. For each comment, we need to know the username for the user who posted it, what the actual comment content was, and how many votes it has.The code for the
PostPageUser Page
Finally, if we decide to view a user’s profile, we can see all of their posts and comments they’ve made.Readit user page for Oscar Martinez
This page should show the user’s username, bio, number of posts, and number of comments. We also need all of their posts and all of their comments. On each post, we need to know the subreadit it was posted on, the post title, as well as the number of votes and comments. For each comment, we need to know which post it was a comment on, what the comment content was, and the number of votes it’s received.The code for the
UserPageConclusion
As we’ve seen, each page in our app requires unique portions of data. Some pages need only high-level summaries, like the number of comments or posts a user has made. Other pages need more in-depth results, like the actual comments and actual posts. Depending on the page, you may need more or less information.The benefit of using GraphQL and Dgraph Cloud is the flexibility in querying exactly the data we need for each page — no more and no less. For each request, we used the same single API endpoint but requested different fields. This greatly simplifies the development work as we don’t need to create a new backend endpoint for each page. (Or worse, create a single endpoint that retrieves a monstrous payload of data we then have to sift through to find the minor subset of data that we need.)GraphQL makes it easy to quickly and painlessly request exactly the right data exactly when you need it.Also published .
L O A D I N G
. . . comments & more!
. . . comments & more!







