
































visit
How To Create a CD pipeline with Kubernetes, Ansible, and Jenkins by@Magalix
13,236 reads
How To Create a CD pipeline with Kubernetes, Ansible, and Jenkins
by MagalixMarch 1st, 2020
Too Long; Didn't Read
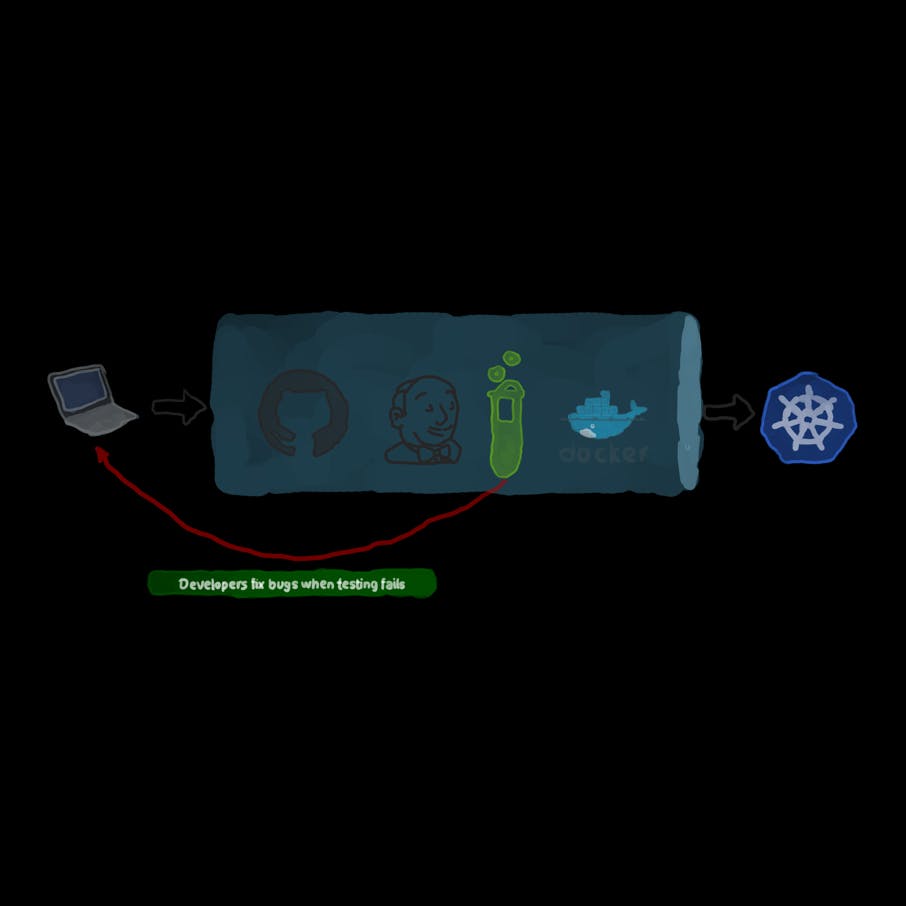
CI/CD is a term that is often heard alongside other terms like DevOps, Agile, Scrum and Kanban, automation, and others. It's considered to be just part of the DevOps process without really understanding what it is or why it was adopted. Taking it for granted is common for young DevOps engineers who might have not seen the “traditional” way of software release cycles and, hence, cannot appreciate it.CI/CD stands for Continuous Integration/Continous Delivery and/or Deployment. Automation ensures that the entire process is fast, reliable, repeatable, and less error-prone.Companies Mentioned
What does CI/CD try to solve?
CI/CD is a term that is often heard alongside other terms like DevOps, Agile, Scrum and Kanban, automation, and others. Sometimes, it’s considered to be just part of the workflow without really understanding what it is or why it was adopted. Taking CI/CD for granted is common for young DevOps engineers who might have not seen the “traditional” way of software release cycles and, hence, cannot appreciate CI/CD. CI/CD stands for Continuous Integration/Continous Delivery and/or Deployment. A team that does not implement CI/CD will have to pass through the following stages when it creates a new software product:The product manager (representing the client’s interests) provides the needed features that the product should have and the behavior it should follow. The documentation must be as thorough and specific as possible.The developers with the business analysts start working on the application by writing codes, running unit tests, and committing the results to a version control system (for example, git).Once the development phase is done, the project is moved to QA. Several tests are run against the product, like User Acceptance Tests, Integration Tests, performance tests among others. During that period, there should be no changes to the code base until the QA phase is complete. If there should be any bug, they’re passed back to the developers to fix them, and hands the product back to QA.Once QA is done, code is deployed to production by the operations team. There is a number of shortcomings for the above workflow:First, it takes so long from the time the product manager makes her request until the product is ready for production. It’s harder for developers to address bugs in code that has been written since quite a long time like a month or more ago. Remember, bugs are only spotted after the development phase is over and QA phase starts.When there’s an urgent code change like a serious bug that needs a hotfix, the QA phase tends to be shortened due to the need to deploy as fast as possible. Since there’s little collaboration between different teams, people start pointing fingers and blaming each other when bugs occur. Everybody starts caring only about his/her own part of the project and lose sight of the common goal.CI/CD solves the above problems by introducing automation. Each change in the code once pushed to the version control system, gets tested, and further deployed to staging/UAT environments for even further testing before deploying it to production for users to consume. Automation ensures that the entire process is fast, reliable, repeatable, and much less error-prone.So, what is CI/CD anyway?
Complete books have been written about this subject. The how, why, and when to implement it in your infrastructure. However, we always prefer less theory and more practice whenever possible. Having said that, the following is a brief description of the automated steps that should be executed once a code change is committed:Continuous Integration (CI): the first step does not include QA. In other words, it does not focus on whether the code provides the features requested by the client. Rather, it ensures that the code is of good quality. Through unit tests, integration tests, the developers are quickly notified of any issues in the code quality. We can further augment the tests with code coverage and static analysis for even more quality assurance.User Acceptance Testing: this is the first part of the CD process. In this phase, automated tests are performed on the code to ensure that it meets the client’s expectations. For example, a web application may work without throwing any errors, but the client wants the visitor to come across a landing page where an offer is presented before navigating to the main page. The current code brings the visitor directly to the main page, which is a deviation from the client’s demands. This sort of issue is pointed out by the UAT testing. In non-CD environments, this is the job of human QA testers.Deployment: this is the second part of the CD process. It involves making changes to the servers/pods/containers that will host the application so that they reflect the updated version. This should be done in an automated way, preferably through a configuration management tool like Ansible, Chef, or Puppet.And what is a pipeline?
A pipeline is a fancy term for a very simple concept; when you have a number of scripts that need to be executed in a certain order to achieve a common goal, they’re collectively referred to as a “pipeline”. For example, in Jenkins, a pipeline may consist of one or more stages that must all complete for a build to be successful. Using stages helps visualize the entire process, learn how long each stage is taking, and determine where exactly the build is failing.LAB: Create a pipeline for a golang app
In this lab, we are building a continuous delivery (CD) pipeline. We are using a very simple application written in Go. For the sake of simplicity, we are going to run only one type of test against the code. The prerequisites for this lab are as follows:- A running Jenkins instance. This could be a cloud instance, a virtual machine, a bare metal one, or a docker container. It must be publicly accessible from the internet so that the repository can connect to Jenkins through webhooks.
- Image registry: you can use Docker Registry, a cloud-based offering like or , or even a custom registry.
- An account on GitHub. Although we use GitHub in this example, the procedure can work equally with other repositories like Bitbucket with minor changes.
Step 01: The application files
Our sample application will respond with ‘Hello World’ to any GET request. Create a new file called main.go and add the following lines:package main
import (
"log"
"net/http"
)
type Server struct{}
func (s *Server) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(http.StatusOK)
w.Header().Set("Content-Type", "application/json")
w.Write([]byte(`{"message": "hello world"}`))
}
func main() {
s := &Server{}
http.Handle("/", s)
log.Fatal(http.ListenAndServe(":8080", nil))
}package main
import (
"log"
"net/http"
)
type Server struct{}
func (s *Server) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(http.StatusOK)
w.Header().Set("Content-Type", "application/json")
w.Write([]byte(`{"message": "hello world"}`))
}
func main() {
s := &Server{}
http.Handle("/", s)
log.Fatal(http.ListenAndServe(":8080", nil))
}The Dockerfile
This is where we package our application:FROM golang:alpine AS build-env
RUN mkdir /go/src/app && apk update && apk add git
ADD main.go /go/src/app/
WORKDIR /go/src/app
RUN CGO_ENABLED=0 GOOS=linux go build -a -installsuffix cgo -ldflags '-extldflags "-static"' -o app .
FROM scratch
WORKDIR /app
COPY --from=build-env /go/src/app/app .
ENTRYPOINT [ "./app" ]The Service
Since we are using Kubernetes as the platform on which we host this application, we need at least a service and a deployment. Our service.yml file looks like this:apiVersion: v1
kind: Service
metadata:
name: hello-svc
spec:
selector:
role: app
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 32000
type: NodePortThe deployment
The application itself, once dockerized, can be deployed to Kubernetes through a Deployment resource. The deployment.yml file looks as follows:apiVersion: apps/v1
kind: Deployment
metadata:
name: hello-deployment
labels:
role: app
spec:
replicas: 2
selector:
matchLabels:
role: app
template:
metadata:
labels:
role: app
spec:
containers:
- name: app
image: "{{ image_id }}"
resources:
requests:
cpu: 10mThe playbook
In this lab, we are using Ansible as our deployment tool. There are many other ways to deploy Kubernetes resources including , but I thought Ansible is a much easier option. Ansible uses playbooks to organize its instructions. Our playbook.yml file looks as follows:- hosts: localhost
tasks:
- name: Deploy the service
k8s:
state: present
definition: "{{ lookup('template', 'service.yml') | from_yaml }}"
validate_certs: no
namespace: default
- name: Deploy the application
k8s:
state: present
validate_certs: no
namespace: default
definition: "{{ lookup('template', 'deployment.yml') | from_yaml }}"Step 02: Install Jenkins, Ansible, and Docker
Let’s install Ansible and use it to automatically deploy a Jenkins server and Docker runtime environment. We also need to install the openshift Python module to enable Ansible connect with Kubernetes.Ansible’s installation is very easy; just install Python and use pip to install Ansible:- Log in to the Jenkins instance
- Install Python 3, Ansible, and the openshift module:
sudo apt update && sudo apt install -y python3 && sudo apt install -y python3-pip && sudo pip3 install ansible && sudo pip3 install openshift - By default, pip installs binaries under a hidden directory in the user’s home folder. We need to add this directory to the $PATH variable so that we can easily call the command:
echo "export PATH=$PATH:~/.local/bin" >> ~/.bashrc && . ~/.bashrc - Install the Ansible role necessary for deploying a Jenkins instance:
ansible-galaxy install geerlingguy.jenkins - Install the Docker role:
ansible-galaxy install geerlingguy.docker - Create a playbook.yaml file and add the following lines:
- Run the playbook through the following command:
Notice that we’re using the public IP address of the instance as the hostname that Jenkins will use. If you are using DNS, you may need to replace this with the DNS name of the instance. Also, notice that you must enable port 8080 on the firewall (if any) before running the playbook.ansible-playbook playbook.yaml. - In few minutes, Jenkins should be installed. You can check by navigating to the IP address (or the DNS name) of the machine and specifying port 8080:
- Click on the Login link and supply “admin” as the username and “admin” as the password. Note that those are the default credentials set by the Ansible role that we used. You can (and should) change those defaults when using Jenkins in production environments. This can be done by setting the role variables. You can refer to the .
- The last thing you need to do is install the following plugins that will be used in our lab: git, pipeline, CloudBees Docker Build and Publish, GitHub.
- hosts: localhost
become: yes
vars:
jenkins_hostname: 35.238.224.64
docker_users:
- jenkins
roles:
- role: geerlingguy.jenkins
- role: geerlingguy.dockerStep 03: Configuring Jenkins User To Connect To The Cluster
As mentioned, this lab assumes that you already have a Kubernetes
cluster up and running. To enable Jenkins to connect to this cluster, we
need to add the necessary kubeconfig file. In this specific lab, we are
using a Kubernetes cluster that’s hosted on Google Cloud so we’re using
the gcloud command. Your specific case may be different. But in all
cases, we must copy the kubeconfig file to the Jenkins’s user directory
as follows:
<code class=" language-yaml">$ sudo cp ~/.kube/config ~jenkins/.kube/
$ sudo chown <span class="token punctuation">-</span>R jenkins<span class="token punctuation">:</span> ~jenkins/.kube/</code>Step 04: Create The Jenkins Pipeline Job
Create a new Jenkins job and select the Pipeline type. The job settings should look as follows:
The settings that we changed are:
- We used the Poll SCM as the build trigger; setting this option instructs Jenkins to check the Git repository on a periodic basis (every minute as indicated by * * * * *). If the repo has changed since the last poll, the job is triggered.
- In the pipeline itself, we specified the repository URL and the credentials. The branch is master.
- In this lab, we are adding all the job’s code in a Jenkinsfile that is stored in the same repository as the code. The Jenkinsfile is discussed later in this article.
Step 05: Configure Jenkins Credentials For GitHub and Docker Hub
Go to and add the credentials to both targets. Make sure that you give a meaningful ID and description to each because you’ll reference them later:Step 06: Create the Jenkinsfile
The Jenkinsfile is what instructs Jenkins about how to build, test, dockerize, publish, and deliver our application. Our Jenkinsfile looks like this:pipeline {
agent any
environment {
registry = "magalixcorp/k8scicd"
GOCACHE = "/tmp"
}
stages {
stage('Build') {
agent {
docker {
image 'golang'
}
}
steps {
// Create our project directory.
sh 'cd ${GOPATH}/src'
sh 'mkdir -p ${GOPATH}/src/hello-world'
// Copy all files in our Jenkins workspace to our project directory.
sh 'cp -r ${WORKSPACE}/* ${GOPATH}/src/hello-world'
// Build the app.
sh 'go build'
}
}
stage('Test') {
agent {
docker {
image 'golang'
}
}
steps {
// Create our project directory.
sh 'cd ${GOPATH}/src'
sh 'mkdir -p ${GOPATH}/src/hello-world'
// Copy all files in our Jenkins workspace to our project directory.
sh 'cp -r ${WORKSPACE}/* ${GOPATH}/src/hello-world'
// Remove cached test results.
sh 'go clean -cache'
// Run Unit Tests.
sh 'go test ./... -v -short'
}
}
stage('Publish') {
environment {
registryCredential = 'dockerhub'
}
steps{
script {
def appimage = docker.build registry + ":$BUILD_NUMBER"
docker.withRegistry( '', registryCredential ) {
appimage.push()
appimage.push('latest')
}
}
}
}
stage ('Deploy') {
steps {
script{
def image_id = registry + ":$BUILD_NUMBER"
sh "ansible-playbook playbook.yml --extra-vars \"image_id=${image_id}\""
}
}
}
}
}
- Build is where we build the Go binary and ensure that nothing is wrong in the build process.
- Test is where we apply a simple UAT test to ensure that the application works as expected.
- Publish, where the Docker image is built and pushed to the registry. After that, any environment can make use of it.
- Deploy, this is the final step where Ansible is invoked to contact Kubernetes and apply the definition files.
Testing our CD pipeline
The last part of this article is where we actually put our work to the test. We are going to commit our code to GitHub and ensure that our code moves through the pipeline until it reaches the cluster:- Add our files:
git add * - Commit our changes:
git commit -m "Initial commit" - Push to GitHub:
git push - On Jenkins, we can either wait for the job to get triggered automatically, or we can just click on “Build Now”.
- If the job succeeds, we can examine our deployed application using the following commands.
- Get the node IP address:
- Now, let’s initiate an HTTP request to our app:
kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
gke-security-lab-default-pool-46f98c95-qsdj Ready <none> 7d v1.13.11-gke.9 10.128.0.59 35.193.211.74 Container-Optimized OS from Google 4.14.145+ docker://18.9.7$ curl 35.193.211.74:32000
{"message": "hello world"}
package main
import (
"log"
"net/http"
)
type Server struct{}
func (s *Server) ServeHTTP(w http.ResponseWriter, r *http.Request) {
w.WriteHeader(http.StatusOK)
w.Header().Set("Content-Type", "application/json")
w.Write([]byte(`{"message": "Hello World!"}`))
}
func main() {
s := &Server{}
http.Handle("/", s)
log.Fatal(http.ListenAndServe(":8080", nil))
}$ git add main.go
$ git commit -m "Changes the greeting message"
[master 24a310e] Changes the greeting message
1 file changed, 1 insertion(+), 1 deletion(-)
$ git push
Counting objects: 3, done.
Delta compression using up to 4 threads.
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 319 bytes | 319.00 KiB/s, done.
Total 3 (delta 2), reused 0 (delta 0)
remote: Resolving deltas: 100% (2/2), completed with 2 local objects.
To //github.com/MagalixCorp/k8scicd.git
7954e03..24a310e master -> masterBy clicking on the failed job, we can see the reason why it failed:
Our faulty code will never make its way to the target environment. If you enjoyed this, check out our other tutorials at the , sign up for our newsletter, or
TL;DR
- CI/CD is an integral part of any modern environment that follows the Agile methodology.
- Through pipelines, you can ensure a smooth transition of code from the version control system to the target environment (testing/staging/production/etc.) while applying all the necessary testing and quality control practices.
- In this article, we had a practical lab where we built a continuous delivery pipeline to deploy a Golang application.
- Through Jenkins, we were able to pull the code from the repository, build and test it using a relevant Docker image.
- Next, we Dockerize and push our application - since it passed our tests - to Docker Hub.
- Finally, we used Ansible to deploy the application to our target environment, which is running Kubernetes.
- Using Jenkins pipelines and Ansible makes it very easy and flexible to change the workflow with very little friction. For example, we can add more tests to the Test stage, we can change the version of Go that’s used to build and test the code, and we can use more variables to change other aspects in deployment and service definitions.
- The best part here is that we are using Kubernetes deployments, which ensures that we have zero downtime for the application when we are changing the container image. This is possible because Deployments use the rolling update method by default to terminate and recreate containers one at a time. Only when the new container is up and healthy does the Deployment terminate the old one.
Previously published at //www.magalix.com/blog/create-a-ci/cd-pipeline-with-kubernetes-and-jenkins
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES




139 Stories To Learn About Cicd #cicd
Apr 11, 2023



