
























visit
How to Train Computer Vision Models Efficiently by@alwaysai
740 reads
How to Train Computer Vision Models Efficiently
by alwaysAI November 9th, 2020
Too Long; Didn't Read
alwaysAI is a developer platform for creating & deploying computer vision applications on the edge. The alwaysAI Model Training Toolkit leverages transfer learning to train your own computer vision models. Transfer learning is the key to efficiently customizing a computer vision model. With alwaysAI you can get all of the power of the COCO dataset tuned to your specific task or application. After training a model, you can upload it and use it to build your own custom computer vision application with our easy to use Python API.Company Mentioned
The starting point of building a successful computer vision application is the model. Computer vision model training can be time-consuming and challenging if one doesn’t have a background in data science. Nonetheless, it is a requirement for customized applications. Several developers who build computer vision applications have experience with Python, but do not have experience with data science. This poses a challenge to most developers who want to customize a model. There are tools that you can use to train your own computer vision model, such as TensorFlow, PyTorch and Keras. alwaysAI also offers a Model Training Toolkit which leverages transfer learning in order to modify an existing model instead of training a model from scratch. This article will go over some basic concepts of model training and then give an example of how to train a custom model. Leveraging transfer learning is the key to efficiently customizing a computer vision model. Transfer learning is essentially taking the knowledge gained from training on a dataset, such as the COCO dataset, and improving upon it or modifying it to your specific task/dataset. This saves the time of learning fundamentals like edge detection and feature primitives.The COCO dataset is a popular open source dataset that we use as the basis of our transfer learning. It is computer vision specific and due to its wide variety classes and large size is the dataset commonly used for open-source computer vision models. With alwaysAI you can get all of the power of the COCO dataset tuned to your specific task or application. alwaysAI provides access to pre-trained computer vision models as well as the ability to leverage transfer learning to train your own models. Using a pre-trained model can certainly expedite computer vision app development. However, pre-trained models can also impose limitations on what applications you can build. In order to build a unique, custom application, you are going to need to train your own model. Using transfer-learning enabled model re-training not only requires less training data but can also significantly cut down the time it takes to train a new model. There are three major components involved in training a model using the alwaysAI Model Training Toolkit:
- Data Collection: Our Image Capture application helps you with your data collection, so that you can collect videos and images directly from your edge device. See this repo for more on this.
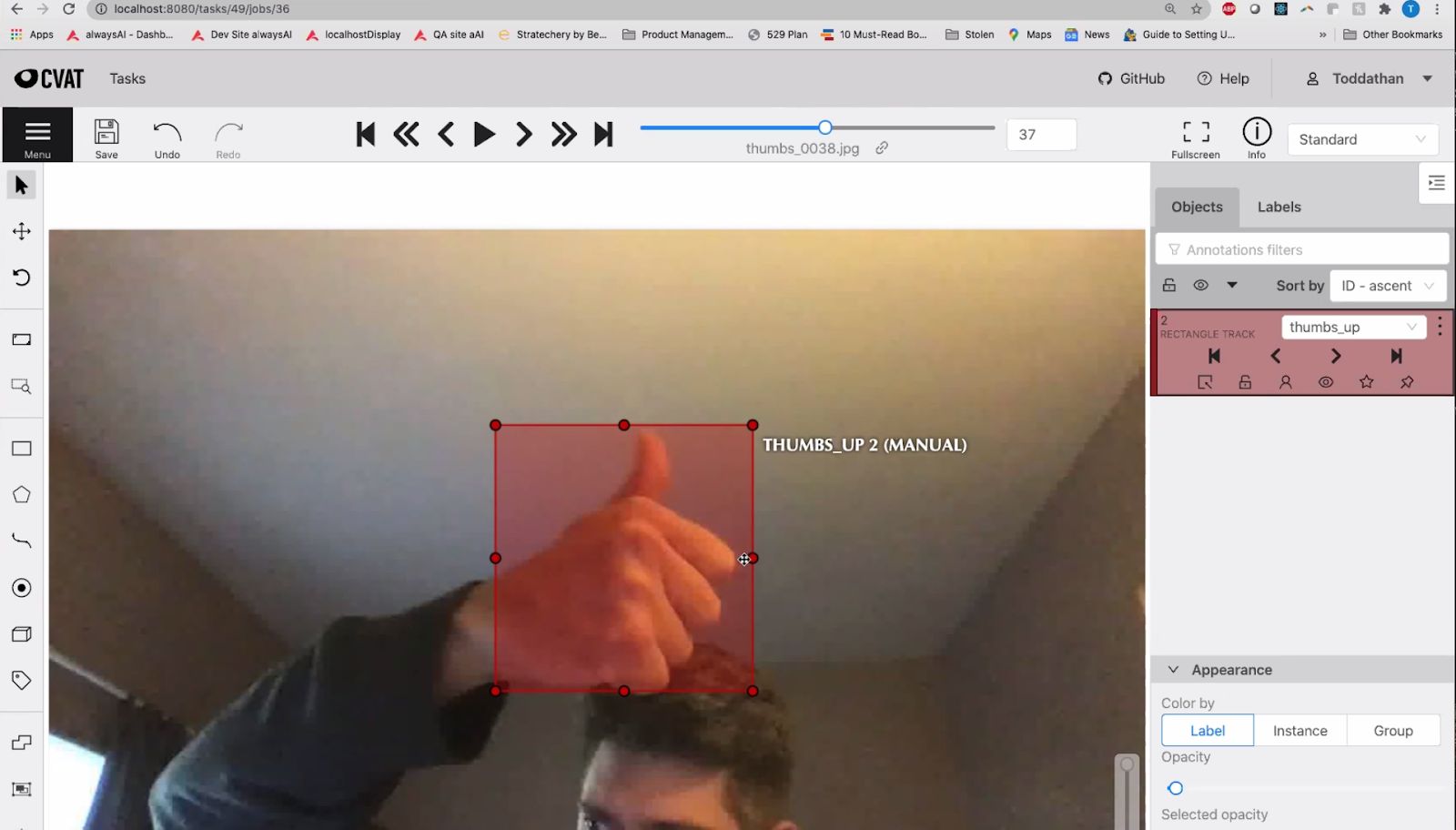
- Data Annotation: We have CVAT, a data annotation tool, built right into our Model Training Toolkit so that you can easily annotate your data.
- Transfer Learning: As mentioned earlier, train a custom MobileNet SSD model using transfer learning to take the knowledge of the COCO dataset and improve upon it or modify it to your unique dataset.
We then use the alwaysAI Python library to cut out the portion of the original image that contains the hand, and feed this new image into the gesture model. The result of this is that the input into the gesture model will always be the area that exactly surrounds the hand meaning we don’t have to vary the training data in terms of background, or sizes or distances of the hand! Therefore, we need a lot less training data, and less time training.As mentioned above, the first step in training your own model is data collection. Since we’re training specific gestures, we can just take videos of a single gesture moving around in the video to get different lighting and some variation in sizes. By having each video contain just one gesture, we’ll make the annotation step, which we’ll cover next, much easier.The second step to training your own model is data annotation. alwaysAI makes this easy by integrating the Computer Vision Annotation Tool directly into the alwaysAI software. Using the tracking feature in CVAT along with the ‘fast-forward’ annotation, we can have CVAT interpolate some of the bounding boxes so we can easily annotate an entire video containing a single gesture in 20 or so minutes.
Once we have the data collection and annotation complete, we can train our model! With alwaysAI, you can train using the command line interface, or a Jupyter Notebook. The latter option is helpful if you want to see a plot of your training and testing validation.Finally, once our model is trained, we can prototype our application. Just using the gesture model alone only works when the hand is very close to the screen.
To make the model work when the hand is farther away, we could collect images in which the hand is farther away from the camera, and then annotate this data, include it in training, and the model will be more robust. However, another option, which is a bit quicker, is to use our gesture model with input that is generated from first using our hand model. By using the hand model first, we can detect hands that are farther away and then use this portion of the image as input for the gesture model. Now we can detect gestures from far away!
Another issue we discover when we test out our gesture model in the prototype is that we don’t pick up gestures when the hand is rotated (e.g. sideways). We could do another iteration of data collection, annotation, training in this case as well, using training data where hands displaying different gestures are in different positions. While this is doable, it might be better to test our hypothesis that this is the issue first. We can use alwaysAI’s API to rotate the image of the hand that is generated by the hand model’s bounding box and then feed that into the gesture model.Now we have a working model that detects unique gestures!This tutorial was covered in one of our previous Hacky Hours focusing on Data Collection and Annotation. You can watch the recording here:If you would like to learn more about the alwaysAI Model Training Toolkit in action and expand on this application, please join our next free Hacky Hour. It takes place on Thursday, November 5 and will be more focused on transfer learning. This virtual workshop will cover building out our prototype application to interact with external devices, and turn gestures into actionable responses in our computer vision application. You can sign up for our free Hacky Hours
L O A D I N G
. . . comments & more!
. . . comments & more!





