








































Jan 01, 1970
स्प्रिंग वेबफ्लक्स थ्रेडिंग मॉडल का परिचय द्वारा@vladimirf
16,457 रीडिंग
स्प्रिंग वेबफ्लक्स थ्रेडिंग मॉडल का परिचय
द्वारा Vladimir Filipchenko7m2023/04/30
बहुत लंबा; पढ़ने के लिए
Pring WebFlux एक प्रतिक्रियाशील, गैर-अवरुद्ध वेब ढांचा है जो जावा में प्रतिक्रियाशील प्रोग्रामिंग को लागू करने के लिए रिएक्टर लाइब्रेरी का उपयोग करता है। वेबफ्लक्स का थ्रेडिंग मॉडल कई सिंक्रोनस वेब फ्रेमवर्क में उपयोग किए जाने वाले पारंपरिक थ्रेड-प्रति-अनुरोध मॉडल से अलग है। वेबफ्लक्स एक गैर-अवरुद्ध, घटना-संचालित मॉडल का उपयोग करता है, जहां छोटी संख्या में धागे बड़ी संख्या में अनुरोधों को संभाल सकते हैं। पृष्ठभूमि में कार्यों को निष्पादित करते समय यह थ्रेड को अन्य अनुरोधों को संभालने के लिए आगे बढ़ने की अनुमति देता है। एक समानांतर अनुसूचक का उपयोग विभिन्न थ्रेड्स पर एक साथ कई कार्यों को निष्पादित करने की अनुमति देकर प्रदर्शन और मापनीयता में सुधार कर सकता है।स्प्रिंग वेबफ्लक्स जावा में आधुनिक, स्केलेबल वेब एप्लिकेशन बनाने के लिए एक प्रतिक्रियाशील, गैर-अवरुद्ध वेब ढांचा है। यह स्प्रिंग फ्रेमवर्क का एक हिस्सा है, और यह जावा में प्रतिक्रियाशील प्रोग्रामिंग को लागू करने के लिए रिएक्टर लाइब्रेरी का उपयोग करता है।
शब्द, "प्रतिक्रियाशील," उन प्रोग्रामिंग मॉडल को संदर्भित करता है जो परिवर्तन पर प्रतिक्रिया करने के लिए बनाए गए हैं - नेटवर्क घटक I / O घटनाओं पर प्रतिक्रिया करते हैं, यूआई नियंत्रक माउस घटनाओं पर प्रतिक्रिया करते हैं, और अन्य। इस अर्थ में, गैर-अवरुद्ध प्रतिक्रियात्मक है, क्योंकि अवरुद्ध होने के बजाय, अब हम सूचनाओं पर प्रतिक्रिया करने के तरीके में हैं क्योंकि संचालन पूरा हो गया है या डेटा उपलब्ध हो गया है।
थ्रेडिंग मॉडल
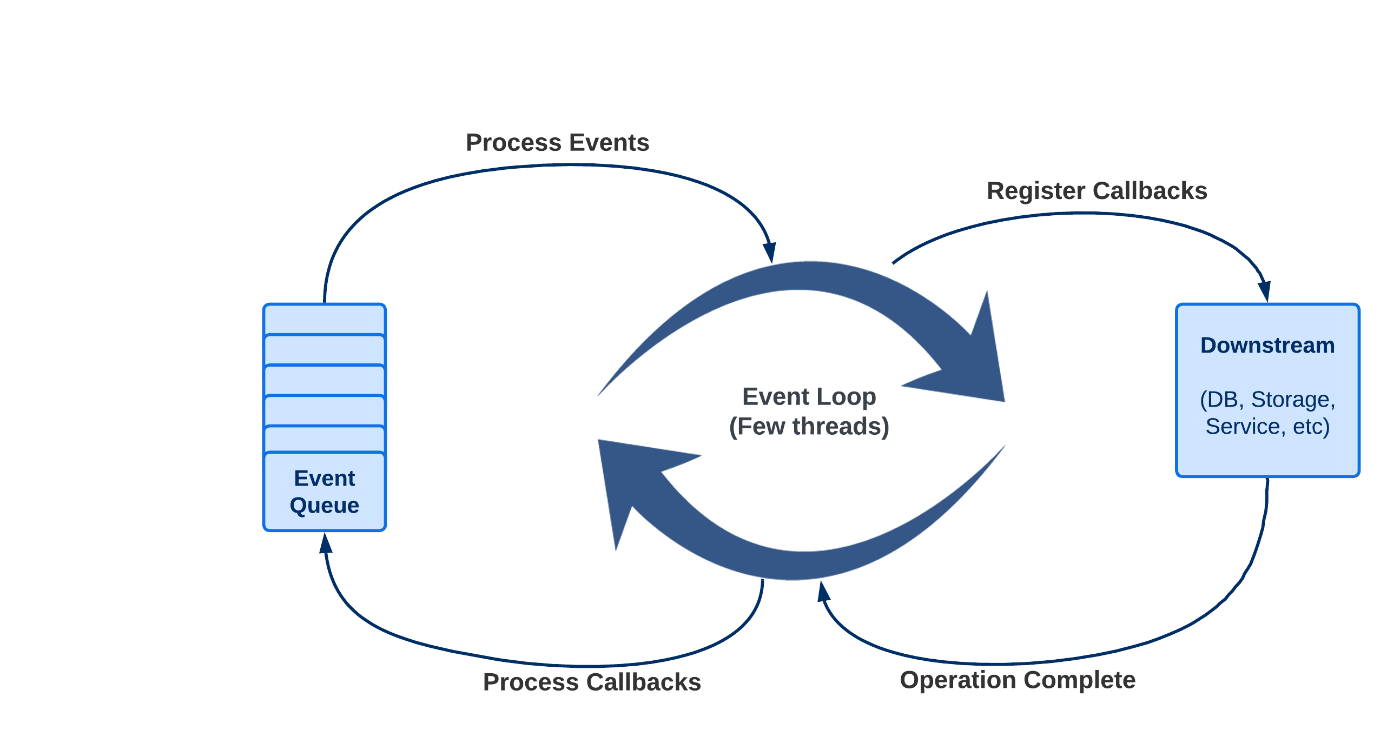
प्रतिक्रियाशील प्रोग्रामिंग की मुख्य विशेषताओं में से एक इसका थ्रेडिंग मॉडल है, जो कई सिंक्रोनस वेब फ्रेमवर्क में उपयोग किए जाने वाले पारंपरिक थ्रेड-प्रति-अनुरोध मॉडल से अलग है।
स्प्रिंग वेबफ्लक्स (और सामान्य रूप से नॉन-ब्लॉकिंग सर्वर) में, यह माना जाता है कि एप्लिकेशन ब्लॉक नहीं होते हैं। इसलिए, गैर-अवरुद्ध सर्वर अनुरोधों को संभालने के लिए एक छोटे, निश्चित आकार के थ्रेड पूल (इवेंट लूप वर्कर्स) का उपयोग करते हैं।
जबकि WebFlux अनुरोध प्रसंस्करण थोड़ा अलग है:
हुड के नीचे
आइए आगे बढ़ते हैं और देखते हैं कि चमकदार सिद्धांत के पीछे क्या है।हमें द्वारा उत्पन्न एक बहुत ही न्यूनतर ऐप की आवश्यकता है। कोड में उपलब्ध है।
थ्रेड से संबंधित सभी विषय अत्यधिक CPU-निर्भर होते हैं। आमतौर पर, अनुरोधों को संभालने वाले प्रसंस्करण थ्रेड्स की संख्या CPU कोर की संख्या से संबंधित होती है । शैक्षिक उद्देश्यों के लिए आप डॉकटर कंटेनर चलाते समय सीपीयू को सीमित करके पूल में थ्रेड्स की गिनती में आसानी से हेरफेर कर सकते हैं:
docker run --cpus=1 -d --rm --name webflux-threading -p 8081:8080 local/webflux-threading यदि आप अभी भी पूल में एक से अधिक थ्रेड देखते हैं - तो कोई बात नहीं। WebFlux द्वारा निर्धारित हो सकते हैं।
हमारा ऐप एक साधारण ज्योतिषी है। /karma समापन बिंदु पर कॉल करने पर आपको balanceAdjustment के साथ 5 रिकॉर्ड मिलेंगे। प्रत्येक समायोजन एक पूर्णांक संख्या है जो आपको दिए गए कर्म का प्रतिनिधित्व करता है। हां, हम बहुत उदार हैं क्योंकि ऐप केवल सकारात्मक संख्याएं उत्पन्न करता है। अब कोई दुर्भाग्य नहीं!
डिफ़ॉल्ट प्रसंस्करण
आइए एक बहुत ही बुनियादी उदाहरण से शुरू करें। अगली नियंत्रक विधि 5 कर्म तत्वों से युक्त फ्लक्स लौटाती है।
@GetMapping("/karma") public Flux<Karma> karma() { return prepareKarma() .map(Karma::new) .log(); } private Flux<Integer> prepareKarma() { Random random = new Random(); return Flux.fromStream( Stream.generate(() -> random.nextInt(10)) .limit(5)); }
log विधि यहाँ एक महत्वपूर्ण बात है। यह सभी रिएक्टिव स्ट्रीम सिग्नलों का अवलोकन करता है और उन्हें INFO स्तर के तहत लॉग में ट्रेस करता है।
कर्ल localhost:8081/karma निम्नलिखित है:
जैसा कि हम देख सकते हैं, IO थ्रेड पूल पर प्रोसेसिंग हो रही है। थ्रेड नाम ctor-http-nio-2 reactor-http-nio-2 के लिए खड़ा है। कार्यों को तुरंत उस थ्रेड पर निष्पादित किया गया जिसने उन्हें सबमिट किया था। रिएक्टर उन्हें किसी अन्य पूल पर शेड्यूल करने के लिए कोई निर्देश नहीं देखा।
देरी और समानांतर प्रसंस्करण
अगला ऑपरेशन 100ms (उर्फ डेटाबेस एमुलेशन) से निकलने वाले प्रत्येक तत्व में देरी करने वाला है
@GetMapping("/delayedKarma") public Flux<Karma> delayedKarma() { return karma() .delayElements(Duration.ofMillis(100)); }
हमें यहां log विधि जोड़ने की आवश्यकता नहीं है क्योंकि यह पहले से ही मूल karma() कॉल में घोषित किया गया था।
इस बार आईओ थ्रेड reactor-http-nio-4 पर केवल पहला तत्व प्राप्त हुआ था। शेष 4 प्रसंस्करण parallel थ्रेड पूल को समर्पित थे।
delayElements का जावाडोक इसकी पुष्टि करता है:
सिग्नल विलंबित होते हैं और समांतर डिफ़ॉल्ट शेड्यूलर पर जारी रहते हैं
आप कॉल श्रृंखला में कहीं भी .subscribeOn(Schedulers.parallel()) निर्दिष्ट करके बिना किसी देरी के समान प्रभाव प्राप्त कर सकते हैं।
parallel अनुसूचक का उपयोग विभिन्न थ्रेड्स पर एक साथ कई कार्यों को निष्पादित करने की अनुमति देकर प्रदर्शन और मापनीयता में सुधार कर सकता है, जो CPU संसाधनों का बेहतर उपयोग कर सकता है और बड़ी संख्या में समवर्ती अनुरोधों को संभाल सकता है।
हालाँकि, यह कोड जटिलता और मेमोरी उपयोग को भी बढ़ा सकता है, और संभावित रूप से वर्कर थ्रेड्स की अधिकतम संख्या पार हो जाने पर थ्रेड पूल थकावट का कारण बन सकता है। इसलिए, parallel थ्रेड पूल का उपयोग करने का निर्णय आवेदन की विशिष्ट आवश्यकताओं और व्यापार-नापसंद पर आधारित होना चाहिए।
सबचैन
आइए अब एक और जटिल उदाहरण देखें। कोड अभी भी बहुत सरल और सीधा है, लेकिन आउटपुट अधिक दिलचस्प है।
हम एक flatMap उपयोग करने जा रहे हैं और एक ज्योतिषी को अधिक निष्पक्ष बना रहे हैं। कर्मा के प्रत्येक उदाहरण के लिए यह मूल समायोजन को 10 से गुणा करेगा और विपरीत समायोजन उत्पन्न करेगा, प्रभावी रूप से एक संतुलित लेनदेन का निर्माण करेगा जो मूल के लिए क्षतिपूर्ति करता है।
@GetMapping("/fairKarma") public Flux<Karma> fairKarma() { return delayedKarma() .flatMap(this::makeFair); } private Flux<Karma> makeFair(Karma original) { return Flux.just(new Karma(original.balanceAdjustment() * 10), new Karma(original.balanceAdjustment() * -10)) .subscribeOn(Schedulers.boundedElastic()) .log(); }
जैसा कि आप देखते हैं, makeFair's फ्लक्स को एक boundedElastic थ्रेड पूल की सदस्यता लेनी चाहिए। आइए देखें कि हमारे पास पहले दो कर्मों के लॉग में क्या है:
रिएक्टर IO थ्रेड पर
balanceAdjustment=9के साथ पहले तत्व की सदस्यता लेता है
फिर
boundedElasticपूलboundedElastic-1थ्रेड पर90और-90समायोजन उत्सर्जित करके कर्म निष्पक्षता पर काम करता है
पहले वाले के बाद के तत्वों को समानांतर थ्रेड पूल पर सब्सक्राइब किया गया है (क्योंकि हमारे पास अभी भी श्रृंखला में
delayedElementsहैं)
boundedElastic शेड्यूलर क्या है ?
यह एक थ्रेड पूल है जो वर्कलोड के आधार पर वर्कर थ्रेड्स की संख्या को गतिशील रूप से समायोजित करता है। यह I/O-बाध्य कार्यों के लिए अनुकूलित है, जैसे डेटाबेस क्वेरीज़ और नेटवर्क अनुरोध, और बहुत अधिक थ्रेड्स या संसाधनों को बर्बाद किए बिना बड़ी संख्या में अल्पकालिक कार्यों को संभालने के लिए डिज़ाइन किया गया है।
डिफ़ॉल्ट रूप से, boundedElastic थ्रेड पूल में उपलब्ध प्रोसेसर की संख्या का अधिकतम आकार 10 से गुणा होता , लेकिन यदि आवश्यक हो तो आप इसे एक अलग अधिकतम आकार का उपयोग करने के लिए कॉन्फ़िगर कर सकते हैं।
boundedElastic जैसे अतुल्यकालिक थ्रेड पूल का उपयोग करके, आप थ्रेड्स को अलग करने के लिए कार्यों को ऑफ़लोड कर सकते हैं और अन्य अनुरोधों को संभालने के लिए मुख्य थ्रेड को मुक्त कर सकते हैं। थ्रेड पूल की बंधी हुई प्रकृति थ्रेड भुखमरी और अत्यधिक संसाधन उपयोग को रोक सकती है, जबकि पूल की लोच इसे कार्यभार के आधार पर गतिशील रूप से वर्कर थ्रेड्स की संख्या को समायोजित करने की अनुमति देती है।
अन्य प्रकार के थ्रेड पूल
आउट-ऑफ़-द-बॉक्स वर्ग द्वारा दो और प्रकार के पूल प्रदान किए जाते हैं, जैसे:
single: यह एक एकल-थ्रेडेड, क्रमबद्ध निष्पादन संदर्भ है जिसे तुल्यकालिक निष्पादन के लिए डिज़ाइन किया गया है। यह तब उपयोगी होता है जब आपको यह सुनिश्चित करने की आवश्यकता होती है कि किसी कार्य को क्रम में निष्पादित किया जाता है और कोई भी दो कार्य समवर्ती रूप से निष्पादित नहीं किए जाते हैं।
immediate: यह शेड्यूलर का एक तुच्छ, नो-ऑप कार्यान्वयन है जो कॉलिंग थ्रेड पर बिना किसी थ्रेड स्विचिंग के कार्यों को तुरंत निष्पादित करता है।
निष्कर्ष
स्प्रिंग वेबफ्लक्स में थ्रेडिंग मॉडल को गैर-अवरुद्ध और अतुल्यकालिक होने के लिए डिज़ाइन किया गया है, जो न्यूनतम संसाधन उपयोग के साथ बड़ी संख्या में अनुरोधों को कुशल तरीके से संभालने की अनुमति देता है। प्रति कनेक्शन समर्पित थ्रेड्स पर भरोसा करने के बजाय, आने वाले अनुरोधों को संभालने और विभिन्न थ्रेड पूल से वर्कर थ्रेड्स को काम वितरित करने के लिए WebFlux इवेंट लूप थ्रेड्स की एक छोटी संख्या का उपयोग करता है।
L O A D I N G
. . . comments & more!
. . . comments & more!



