
































Jan 01, 1970
د اپاچي سی تونل زیټا انجن د سرچینې کوډ تحلیل (درېمه برخه): د سرور اړخ کاري سپارل لخوا@williamguo
470 لوستل
د اپاچي سی تونل زیټا انجن د سرچینې کوډ تحلیل (درېمه برخه): د سرور اړخ کاري سپارل
لخوا William Guo115m2024/09/20
ډېر اوږد؛ لوستل
دا ځل، دا د سرور-سایډ ټاسک سپارلو پروسې په اړه دی.دا د لړۍ مقالو وروستۍ برخه ده چې د اپاچي سی تونل زیټا انجن تحلیل کولو لپاره د سرچینې کوډ؛ د بشپړ عکس ترلاسه کولو لپاره پخوانۍ لړۍ بیاکتنه وکړئ:
- د اپاچي سی تونل زیټا انجن د سرچینې کوډ تحلیل (1 برخه): د سرور پیل کول
- د اپاچي سی تونل زیټا انجن د سرچینې کوډ تحلیل (دوهمه برخه): د پیرودونکي اړخ کې د دندې سپارلو پروسه
- همغږي کوونکي خدمت : یوازې په ماسټر / سټینډ بای نوډونو کې فعال شوی، د کلستر حالت ته غوږ نیسي، او د ماسټر سټینډ بای ناکامۍ اداره کوي.
- SlotService : د کارګر نوډونو کې فعال شوی، په وخت سره د خپل وضعیت ماسټر ته راپور ورکوي.
- TaskExecutionService : د کارګر نوډونو کې فعال شوی، په دوره توګه IMAP ته د کاري میټریک تازه کوي.
کله چې د کلستر لخوا کومه دنده ترلاسه نه شي، دا برخې پرمخ ځي. په هرصورت، کله چې یو پیرودونکی د SeaTunnelSubmitJobCodec پیغام سرور ته واستوي، سرور دا څنګه اداره کوي؟
د پیغام استقبال
څرنګه چې مراجع او سرور په مختلفو ماشینونو کې دي، د میتود زنګونه نشي کارول کیدی؛ پرځای یې، د پیغام لیږد کارول کیږي. د پیغام په ترلاسه کولو سره، سرور دا څنګه پروسس کوي؟
لومړی، پیرودونکي د SeaTunnelSubmitJobCodec ډول پیغام لیږي:
// Client code ClientMessage request = SeaTunnelSubmitJobCodec.encodeRequest( jobImmutableInformation.getJobId(), seaTunnelHazelcastClient .getSerializationService() .toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint()); PassiveCompletableFuture<Void> submitJobFuture = seaTunnelHazelcastClient.requestOnMasterAndGetCompletableFuture(request); د SeaTunnelSubmitJobCodec ټولګي کې، دا د SeaTunnelMessageTaskFactoryProvider ټولګي سره تړاو لري، کوم چې د پیغام ډولونه MessageTask ټولګیو ته نقشه کوي. SeaTunnelSubmitJobCodec لپاره، دا د SubmitJobTask ټولګي ته نقشه ورکوي:
private final Int2ObjectHashMap<MessageTaskFactory> factories = new Int2ObjectHashMap<>(60); private void initFactories() { factories.put( SeaTunnelPrintMessageCodec.REQUEST_MESSAGE_TYPE, (clientMessage, connection) -> new PrintMessageTask(clientMessage, node, connection)); factories.put( SeaTunnelSubmitJobCodec.REQUEST_MESSAGE_TYPE, (clientMessage, connection) -> new SubmitJobTask(clientMessage, node, connection)); ..... }
کله چې د SubmitJobTask ټولګي معاینه کوي، دا د SubmitJobOperation ټولګي غوښتنه کوي:
@Override protected Operation prepareOperation() { return new SubmitJobOperation( parameters.jobId, parameters.jobImmutableInformation, parameters.isStartWithSavePoint); }
د SubmitJobOperation ټولګي کې، د دندې معلومات د دې submitJob میتود له لارې CoordinatorService برخې ته سپارل کیږي:
@Override protected PassiveCompletableFuture<?> doRun() throws Exception { SeaTunnelServer seaTunnelServer = getService(); return seaTunnelServer .getCoordinatorService() .submitJob(jobId, jobImmutableInformation, isStartWithSavePoint); } پدې مرحله کې ، د پیرودونکي پیغام په مؤثره توګه سرور ته د میتود غوښتنې لپاره سپارل کیږي. د عملیاتو نور ډولونه په ورته ډول تعقیب کیدی شي.همغږي کوونکي خدمت
بیا، راځئ وګورو چې CoordinatorService څنګه د دندې سپارلو اداره کوي:
public PassiveCompletableFuture<Void> submitJob( long jobId, Data jobImmutableInformation, boolean isStartWithSavePoint) { CompletableFuture<Void> jobSubmitFuture = new CompletableFuture<>(); // First, check if a job with the same ID already exists if (getJobMaster(jobId) != null) { logger.warning( String.format( "The job %s is currently running; no need to submit again.", jobId)); jobSubmitFuture.complete(null); return new PassiveCompletableFuture<>(jobSubmitFuture); } // Initialize JobMaster object JobMaster jobMaster = new JobMaster( jobImmutableInformation, this.nodeEngine, executorService, getResourceManager(), getJobHistoryService(), runningJobStateIMap, runningJobStateTimestampsIMap, ownedSlotProfilesIMap, runningJobInfoIMap, metricsImap, engineConfig, seaTunnelServer); executorService.submit( () -> { try { // Ensure no duplicate tasks with the same ID if (!isStartWithSavePoint && getJobHistoryService().getJobMetrics(jobId) != null) { throw new JobException( String.format( "The job id %s has already been submitted and is not starting with a savepoint.", jobId)); } // Add task info to IMAP runningJobInfoIMap.put( jobId, new JobInfo(System.currentTimeMillis(), jobImmutableInformation)); runningJobMasterMap.put(jobId, jobMaster); // Initialize JobMaster jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); // Task creation successful jobSubmitFuture.complete(null); } catch (Throwable e) { String errorMsg = ExceptionUtils.getMessage(e); logger.severe(String.format("submit job %s error %s ", jobId, errorMsg)); jobSubmitFuture.completeExceptionally(new JobException(errorMsg)); } if (!jobSubmitFuture.isCompletedExceptionally()) { // Start job execution try { jobMaster.run(); } finally { // Remove jobMaster from map if not cancelled if (!jobMaster.getJobMasterCompleteFuture().isCancelled()) { runningJobMasterMap.remove(jobId); } } } else { runningJobInfoIMap.remove(jobId); runningJobMasterMap.remove(jobId); } }); return new PassiveCompletableFuture<>(jobSubmitFuture); } په سرور کې، د انفرادي دندې اداره کولو لپاره JobMaster اعتراض رامینځته شوی. د JobMaster جوړولو په جریان کې، دا د getResourceManager() له لارې د سرچینې مدیر او getJobHistoryService() له لارې د دندې تاریخ معلومات ترلاسه کوي. jobHistoryService په پیل کې پیل کیږي، پداسې حال کې چې ResourceManager د لومړي دندې سپارلو کې په سستۍ سره ډک شوی:
/** Lazy load for resource manager */ public ResourceManager getResourceManager() { if (resourceManager == null) { synchronized (this) { if (resourceManager == null) { ResourceManager manager = new ResourceManagerFactory(nodeEngine, engineConfig) .getResourceManager(); manager.init(); resourceManager = manager; } } } return resourceManager; }د سرچینې مدیر
اوس مهال، SeaTunnel یوازې د استیناف ګمارنې ملاتړ کوي. کله چې ResourceManager پیل کول، دا ټول کلستر نوډونه راټولوي او د نوډ معلوماتو ترلاسه کولو لپاره SyncWorkerProfileOperation لیږي، د داخلي registerWorker حالت تازه کوي:
@Override public void init() { log.info("Init ResourceManager"); initWorker(); } private void initWorker() { log.info("initWorker... "); List<Address> aliveNode = nodeEngine.getClusterService().getMembers().stream() .map(Member::getAddress) .collect(Collectors.toList()); log.info("init live nodes: {}", aliveNode); List<CompletableFuture<Void>> futures = aliveNode.stream() .map( node -> sendToMember(new SyncWorkerProfileOperation(), node) .thenAccept( p -> { if (p != null) { registerWorker.put( node, (WorkerProfile) p); log.info( "received new worker register: " + ((WorkerProfile) p) .getAddress()); } })) .collect(Collectors.toList()); futures.forEach(CompletableFuture::join); log.info("registerWorker: {}", registerWorker); } مخکې، موږ ولیدل چې SlotService په دوره توګه د هر نوډ څخه ماسټر ته د زړه ضربان پیغامونه لیږي. د دې زړه وهلو په ترلاسه کولو سره، د ResourceManager په خپل داخلي حالت کې د نوډ حالت تازه کوي.
@Override public void heartbeat(WorkerProfile workerProfile) { if (!registerWorker.containsKey(workerProfile.getAddress())) { log.info("received new worker register: " + workerProfile.getAddress()); sendToMember(new ResetResourceOperation(), workerProfile.getAddress()).join(); } else { log.debug("received worker heartbeat from: " + workerProfile.getAddress()); } registerWorker.put(workerProfile.getAddress(), workerProfile); }د دندې ماسټر
په CoordinatorService کې، د JobMaster مثال جوړیږي او د هغې init طریقه ویل کیږي. کله چې د init میتود بشپړ شي، نو دا په پام کې نیول کیږي چې د دندې رامینځته کول بریالي دي. بیا د run میتود په رسمي ډول د دندې اجرا کولو ته ویل کیږي.
راځئ چې د پیل کولو او init طریقه وګورو.
public JobMaster( @NonNull Data jobImmutableInformationData, @NonNull NodeEngine nodeEngine, @NonNull ExecutorService executorService, @NonNull ResourceManager resourceManager, @NonNull JobHistoryService jobHistoryService, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull IMap ownedSlotProfilesIMap, @NonNull IMap<Long, JobInfo> runningJobInfoIMap, @NonNull IMap<Long, HashMap<TaskLocation, SeaTunnelMetricsContext>> metricsImap, EngineConfig engineConfig, SeaTunnelServer seaTunnelServer) { this.jobImmutableInformationData = jobImmutableInformationData; this.nodeEngine = nodeEngine; this.executorService = executorService; flakeIdGenerator = this.nodeEngine .getHazelcastInstance() .getFlakeIdGenerator(Constant.SEATUNNEL_ID_GENERATOR_NAME); this.ownedSlotProfilesIMap = ownedSlotProfilesIMap; this.resourceManager = resourceManager; this.jobHistoryService = jobHistoryService; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.runningJobInfoIMap = runningJobInfoIMap; this.engineConfig = engineConfig; this.metricsImap = metricsImap; this.seaTunnelServer = seaTunnelServer; this.releasedSlotWhenTaskGroupFinished = new ConcurrentHashMap<>(); } د پیل کولو په جریان کې، یوازې ساده متغیر دندې پرته له کوم مهم عملیات ترسره کیږي. موږ اړتیا لرو چې د init میتود باندې تمرکز وکړو.
public synchronized void init(long initializationTimestamp, boolean restart) throws Exception { // The server receives a binary object from the client, // which is first converted to a JobImmutableInformation object, the same object sent by the client jobImmutableInformation = nodeEngine.getSerializationService().toObject(jobImmutableInformationData); // Get the checkpoint configuration, such as the interval, timeout, etc. jobCheckpointConfig = createJobCheckpointConfig( engineConfig.getCheckpointConfig(), jobImmutableInformation.getJobConfig()); LOGGER.info( String.format( "Init JobMaster for Job %s (%s) ", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId())); LOGGER.info( String.format( "Job %s (%s) needed jar urls %s", jobImmutableInformation.getJobConfig().getName(), jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls())); ClassLoader appClassLoader = Thread.currentThread().getContextClassLoader(); // Get the ClassLoader ClassLoader classLoader = seaTunnelServer .getClassLoaderService() .getClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); // Deserialize the logical DAG from the client-provided information logicalDag = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, jobImmutableInformation.getLogicalDag()); try { Thread.currentThread().setContextClassLoader(classLoader); // Execute save mode functionality, such as table creation and deletion if (!restart && !logicalDag.isStartWithSavePoint() && ReadonlyConfig.fromMap(logicalDag.getJobConfig().getEnvOptions()) .get(EnvCommonOptions.SAVEMODE_EXECUTE_LOCATION) .equals(SaveModeExecuteLocation.CLUSTER)) { logicalDag.getLogicalVertexMap().values().stream() .map(LogicalVertex::getAction) .filter(action -> action instanceof SinkAction) .map(sink -> ((SinkAction<?, ?, ?, ?>) sink).getSink()) .forEach(JobMaster::handleSaveMode); } // Parse the logical plan into a physical plan final Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> planTuple = PlanUtils.fromLogicalDAG( logicalDag, nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, engineConfig.getQueueType(), engineConfig); this.physicalPlan = planTuple.f0(); this.physicalPlan.setJobMaster(this); this.checkpointPlanMap = planTuple.f1(); } finally { // Reset the current thread's ClassLoader and release the created classLoader Thread.currentThread().setContextClassLoader(appClassLoader); seaTunnelServer .getClassLoaderService() .releaseClassLoader( jobImmutableInformation.getJobId(), jobImmutableInformation.getPluginJarsUrls()); } Exception initException = null; try { // Initialize the checkpoint manager this.initCheckPointManager(restart); } catch (Exception e) { initException = e; } // Add some callback functions for job state listening this.initStateFuture(); if (initException != null) { if (restart) { cancelJob(); } throw initException; } }
په نهایت کې، راځئ چې run طریقه وګورو:
public void run() { try { physicalPlan.startJob(); } catch (Throwable e) { LOGGER.severe( String.format( "Job %s (%s) run error with: %s", physicalPlan.getJobImmutableInformation().getJobConfig().getName(), physicalPlan.getJobImmutableInformation().getJobId(), ExceptionUtils.getMessage(e))); } finally { jobMasterCompleteFuture.join(); if (engineConfig.getConnectorJarStorageConfig().getEnable()) { List<ConnectorJarIdentifier> pluginJarIdentifiers = jobImmutableInformation.getPluginJarIdentifiers(); seaTunnelServer .getConnectorPackageService() .cleanUpWhenJobFinished( jobImmutableInformation.getJobId(), pluginJarIdentifiers); } } } دا طریقه نسبتا ساده ده، د پیدا شوي فزیکي پلان اجرا کولو لپاره physicalPlan.startJob() زنګ ووهئ.
د پورتني کوډ څخه، دا څرګنده ده چې وروسته له دې چې سرور د پیرودونکي د دندې سپارلو غوښتنه ترلاسه کړي، دا د JobMaster ټولګي پیل کوي، کوم چې د منطقي پلان څخه فزیکي پلان رامینځته کوي، او بیا فزیکي پالن اجرا کوي.
له منطقي پلان څخه فزیکي پلان ته تبادله
د فزیکي پلان تولید په JobMaster کې د لاندې میتود په زنګ وهلو سره ترسره کیږي:
final Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> planTuple = PlanUtils.fromLogicalDAG( logicalDag, nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, engineConfig.getQueueType(), engineConfig); د فزیکي پلان رامینځته کولو میتود کې ، منطقي پلان لومړی په اجرایوي پلان بدلیږي ، او بیا د اجرا کولو پلان په فزیکي پلان بدلیږي.
public static Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> fromLogicalDAG( @NonNull LogicalDag logicalDag, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType, @NonNull EngineConfig engineConfig) { return new PhysicalPlanGenerator( new ExecutionPlanGenerator( logicalDag, jobImmutableInformation, engineConfig) .generate(), nodeEngine, jobImmutableInformation, initializationTimestamp, executorService, flakeIdGenerator, runningJobStateIMap, runningJobStateTimestampsIMap, queueType) .generate(); }د اجرا کولو پلان جوړول
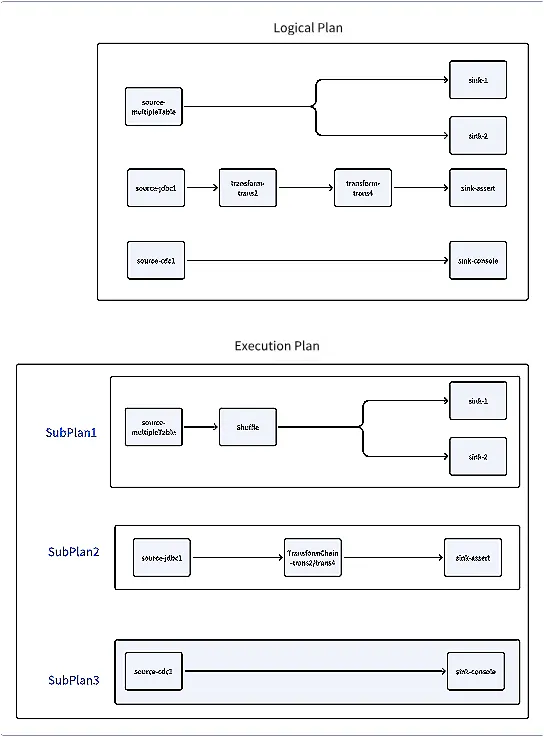
public ExecutionPlanGenerator( @NonNull LogicalDag logicalPlan, @NonNull JobImmutableInformation jobImmutableInformation, @NonNull EngineConfig engineConfig) { checkArgument( logicalPlan.getEdges().size() > 0, "ExecutionPlan Builder must have LogicalPlan."); this.logicalPlan = logicalPlan; this.jobImmutableInformation = jobImmutableInformation; this.engineConfig = engineConfig; } public ExecutionPlan generate() { log.debug("Generate execution plan using logical plan:"); Set<ExecutionEdge> executionEdges = generateExecutionEdges(logicalPlan.getEdges()); log.debug("Phase 1: generate execution edge list {}", executionEdges); executionEdges = generateShuffleEdges(executionEdges); log.debug("Phase 2: generate shuffle edge list {}", executionEdges); executionEdges = generateTransformChainEdges(executionEdges); log.debug("Phase 3: generate transform chain edge list {}", executionEdges); List<Pipeline> pipelines = generatePipelines(executionEdges); log.debug("Phase 4: generate pipeline list {}", pipelines); ExecutionPlan executionPlan = new ExecutionPlan(pipelines, jobImmutableInformation); log.debug("Phase 5 : generate execution plan {}", executionPlan); return executionPlan; } د ExecutionPlanGenerator ټولګي یو منطقي پلان اخلي او د یو لړ مرحلو له لارې د اجرا کولو پلان تولیدوي، پشمول د اعدام څنډې، شفل څنډې، د زنځیر کنډکونو بدلول، او په پای کې پایپ لاینونه.
د فزیکي پلان تولید
د PhysicalPlanGenerator ټولګي د اجرا کولو پلان په فزیکي پلان بدلوي:
public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.executionPlan = executionPlan; this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public PhysicalPlan generate() { List<PhysicalVertex> physicalVertices = generatePhysicalVertices(executionPlan); List<PhysicalEdge> physicalEdges = generatePhysicalEdges(executionPlan); PhysicalPlan physicalPlan = new PhysicalPlan(physicalVertices, physicalEdges); log.debug("Generate physical plan: {}", physicalPlan); return physicalPlan; }
public class ExecutionPlan { private final List<Pipeline> pipelines; private final JobImmutableInformation jobImmutableInformation; } public class Pipeline { /** The ID of the pipeline. */ private final Integer id; private final List<ExecutionEdge> edges; private final Map<Long, ExecutionVertex> vertexes; } public class ExecutionEdge { private ExecutionVertex leftVertex; private ExecutionVertex rightVertex; } public class ExecutionVertex { private Long vertexId; private Action action; private int parallelism; }
public class LogicalDag implements IdentifiedDataSerializable { @Getter private JobConfig jobConfig; private final Set<LogicalEdge> edges = new LinkedHashSet<>(); private final Map<Long, LogicalVertex> logicalVertexMap = new LinkedHashMap<>(); private IdGenerator idGenerator; private boolean isStartWithSavePoint = false; } public class LogicalEdge implements IdentifiedDataSerializable { private LogicalVertex inputVertex; private LogicalVertex targetVertex; private Long inputVertexId; private Long targetVertexId; } public class LogicalVertex implements IdentifiedDataSerializable { private Long vertexId; private Action action; private int parallelism; } داسې ښکاري چې هر پایپ لاین یو منطقي پلان سره ورته وي. ولې موږ د دې بدلون ګام ته اړتیا لرو؟ راځئ چې د منطقي پلان جوړولو پروسې ته نږدې کتنه وکړو.
- 1 ګام: منطقي پلان د اجرا کولو پلان ته بدلول
// Input is a set of logical plan edges, where each edge stores upstream and downstream nodes private Set<ExecutionEdge> generateExecutionEdges(Set<LogicalEdge> logicalEdges) { Set<ExecutionEdge> executionEdges = new LinkedHashSet<>(); Map<Long, ExecutionVertex> logicalVertexIdToExecutionVertexMap = new HashMap(); // Sort in order: first by input node, then by output node List<LogicalEdge> sortedLogicalEdges = new ArrayList<>(logicalEdges); Collections.sort( sortedLogicalEdges, (o1, o2) -> { if (o1.getInputVertexId() != o2.getInputVertexId()) { return o1.getInputVertexId() > o2.getInputVertexId() ? 1 : -1; } if (o1.getTargetVertexId() != o2.getTargetVertexId()) { return o1.getTargetVertexId() > o2.getTargetVertexId() ? 1 : -1; } return 0; }); // Loop to convert each logical plan edge to an execution plan edge for (LogicalEdge logicalEdge : sortedLogicalEdges) { LogicalVertex logicalInputVertex = logicalEdge.getInputVertex(); ExecutionVertex executionInputVertex = logicalVertexIdToExecutionVertexMap.computeIfAbsent( logicalInputVertex.getVertexId(), vertexId -> { long newId = idGenerator.getNextId(); // Recreate Action for each logical plan node Action newLogicalInputAction = recreateAction( logicalInputVertex.getAction(), newId, logicalInputVertex.getParallelism()); // Convert to execution plan node return new ExecutionVertex( newId, newLogicalInputAction, logicalInputVertex.getParallelism()); }); // Similarly, recreate execution plan nodes for target nodes LogicalVertex logicalTargetVertex = logicalEdge.getTargetVertex(); ExecutionVertex executionTargetVertex = logicalVertexIdToExecutionVertexMap.computeIfAbsent( logicalTargetVertex.getVertexId(), vertexId -> { long newId = idGenerator.getNextId(); Action newLogicalTargetAction = recreateAction( logicalTargetVertex.getAction(), newId, logicalTargetVertex.getParallelism()); return new ExecutionVertex( newId, newLogicalTargetAction, logicalTargetVertex.getParallelism()); }); // Generate execution plan edge ExecutionEdge executionEdge = new ExecutionEdge(executionInputVertex, executionTargetVertex); executionEdges.add(executionEdge); } return executionEdges; }- 2 ګام
private Set<ExecutionEdge> generateShuffleEdges(Set<ExecutionEdge> executionEdges) { // Map of upstream node ID to list of downstream nodes Map<Long, List<ExecutionVertex>> targetVerticesMap = new LinkedHashMap<>(); // Store only nodes of type Source Set<ExecutionVertex> sourceExecutionVertices = new HashSet<>(); executionEdges.forEach( edge -> { ExecutionVertex leftVertex = edge.getLeftVertex(); ExecutionVertex rightVertex = edge.getRightVertex(); if (leftVertex.getAction() instanceof SourceAction) { sourceExecutionVertices.add(leftVertex); } targetVerticesMap .computeIfAbsent(leftVertex.getVertexId(), id -> new ArrayList<>()) .add(rightVertex); }); if (sourceExecutionVertices.size() != 1) { return executionEdges; } ExecutionVertex sourceExecutionVertex = sourceExecutionVertices.stream().findFirst().get(); Action sourceAction = sourceExecutionVertex.getAction(); List<CatalogTable> producedCatalogTables = new ArrayList<>(); if (sourceAction instanceof SourceAction) { try { producedCatalogTables = ((SourceAction<?, ?, ?>) sourceAction) .getSource() .getProducedCatalogTables(); } catch (UnsupportedOperationException e) { } } else if (sourceAction instanceof TransformChainAction) { return executionEdges; } else { throw new SeaTunnelException( "source action must be SourceAction or TransformChainAction"); } // If the source produces a single table or // the source has only one downstream output, return directly if (producedCatalogTables.size() <= 1 || targetVerticesMap.get(sourceExecutionVertex.getVertexId()).size() <= 1) { return executionEdges; } List<ExecutionVertex> sinkVertices = targetVerticesMap.get(sourceExecutionVertex.getVertexId()); // Check if there are other types of actions, currently downstream nodes should ideally have two types: Transform and Sink; here we check if only Sink type is present Optional<ExecutionVertex> hasOtherAction = sinkVertices.stream() .filter(vertex -> !(vertex.getAction() instanceof SinkAction)) .findFirst(); checkArgument(!hasOtherAction.isPresent()); // After executing the above code, the current scenario is: // There is only one data source, this source produces multiple tables, and multiple sink nodes depend on these tables // This means the task has only two types of nodes: a source node that produces multiple tables and a group of sink nodes depending on this source // A new shuffle node will be created and added between the source and sinks // Modify the dependency relationship to source -> shuffle -> multiple sinks Set<ExecutionEdge> newExecutionEdges = new LinkedHashSet<>(); // Shuffle strategy will not be explored in detail here ShuffleStrategy shuffleStrategy = ShuffleMultipleRowStrategy.builder() .jobId(jobImmutableInformation.getJobId()) .inputPartitions(sourceAction.getParallelism()) .catalogTables(producedCatalogTables) .queueEmptyQueueTtl( (int) (engineConfig.getCheckpointConfig().getCheckpointInterval() * 3)) .build(); ShuffleConfig shuffleConfig = ShuffleConfig.builder().shuffleStrategy(shuffleStrategy).build(); long shuffleVertexId = idGenerator.getNextId(); String shuffleActionName = String.format("Shuffle [%s]", sourceAction.getName()); ShuffleAction shuffleAction = new ShuffleAction(shuffleVertexId, shuffleActionName, shuffleConfig); shuffleAction.setParallelism(sourceAction.getParallelism()); ExecutionVertex shuffleVertex = new ExecutionVertex(shuffleVertexId, shuffleAction, shuffleAction.getParallelism()); ExecutionEdge sourceToShuffleEdge = new ExecutionEdge(sourceExecutionVertex, shuffleVertex); newExecutionEdges.add(sourceToShuffleEdge); // Set the parallelism of multiple sink nodes to 1 for (ExecutionVertex sinkVertex : sinkVertices) { sinkVertex.setParallelism(1); sinkVertex.getAction().setParallelism(1); ExecutionEdge shuffleToSinkEdge = new ExecutionEdge(shuffleVertex, sinkVertex); newExecutionEdges.add(shuffleToSinkEdge); } return newExecutionEdges; } د شفل مرحله ځانګړي سناریوګانې په ګوته کوي چیرې چې سرچینه د ډیری میزونو لوستلو ملاتړ کوي ، او د دې سرچینې پورې اړوند ډیری سینک نوډونه شتون لري. په داسې حالتونو کې، د شفل نوډ په منځ کې اضافه کیږي.3 ګام
private Set<ExecutionEdge> generateTransformChainEdges(Set<ExecutionEdge> executionEdges) { // Uses three structures: stores all Source nodes and the input/output nodes for each // inputVerticesMap stores all upstream input nodes by downstream node id as the key // targetVerticesMap stores all downstream output nodes by upstream node id as the key Map<Long, List<ExecutionVertex>> inputVerticesMap = new HashMap<>(); Map<Long, List<ExecutionVertex>> targetVerticesMap = new HashMap<>(); Set<ExecutionVertex> sourceExecutionVertices = new HashSet<>(); executionEdges.forEach( edge -> { ExecutionVertex leftVertex = edge.getLeftVertex(); ExecutionVertex rightVertex = edge.getRightVertex(); if (leftVertex.getAction() instanceof SourceAction) { sourceExecutionVertices.add(leftVertex); } inputVerticesMap .computeIfAbsent(rightVertex.getVertexId(), id -> new ArrayList<>()) .add(leftVertex); targetVerticesMap .computeIfAbsent(leftVertex.getVertexId(), id -> new ArrayList<>()) .add(rightVertex); }); Map<Long, ExecutionVertex> transformChainVertexMap = new HashMap<>(); Map<Long, Long> chainedTransformVerticesMapping = new HashMap<>(); // Loop over each source, starting with all head nodes in the DAG for (ExecutionVertex sourceVertex : sourceExecutionVertices) { List<ExecutionVertex> vertices = new ArrayList<>(); vertices.add(sourceVertex); for (int index = 0; index < vertices.size(); index++) { ExecutionVertex vertex = vertices.get(index); fillChainedTransformExecutionVertex( vertex, chainedTransformVerticesMapping, transformChainVertexMap, executionEdges, Collections.unmodifiableMap(inputVerticesMap), Collections.unmodifiableMap(targetVerticesMap)); // If the current node has downstream nodes, add all downstream nodes to the list // The second loop will recalculate the newly added downstream nodes, which could be Transform nodes or Sink nodes if (targetVerticesMap.containsKey(vertex.getVertexId())) { vertices.addAll(targetVerticesMap.get(vertex.getVertexId())); } } } // After looping, chained Transform nodes will be chained, and the chainable edges will be removed from the execution plan // Therefore, the logical plan at this point cannot form the graph relationship and needs to be rebuilt Set<ExecutionEdge> transformChainEdges = new LinkedHashSet<>(); // Loop over existing relationships for (ExecutionEdge executionEdge : executionEdges) { ExecutionVertex leftVertex = executionEdge.getLeftVertex(); ExecutionVertex rightVertex = executionEdge.getRightVertex(); boolean needRebuild = false; // Check if the input or output nodes of the current edge are in the chain mapping // If so, the node has been chained, and we need to find the chained node in the mapping // and rebuild the DAG if (chainedTransformVerticesMapping.containsKey(leftVertex.getVertexId())) { needRebuild = true; leftVertex = transformChainVertexMap.get( chainedTransformVerticesMapping.get(leftVertex.getVertexId())); } if (chainedTransformVerticesMapping.containsKey(rightVertex.getVertexId())) { needRebuild = true; rightVertex = transformChainVertexMap.get( chainedTransformVerticesMapping.get(rightVertex.getVertexId())); } if (needRebuild) { executionEdge = new ExecutionEdge(leftVertex, rightVertex); } transformChainEdges.add(executionEdge); } return transformChainEdges; } private void fillChainedTransformExecutionVertex( ExecutionVertex currentVertex, Map<Long, Long> chainedTransformVerticesMapping, Map<Long, ExecutionVertex> transformChainVertexMap, Set<ExecutionEdge> executionEdges, Map<Long, List<ExecutionVertex>> inputVerticesMap, Map<Long, List<ExecutionVertex>> targetVerticesMap) { // Exit if the map already contains the current node if (chainedTransformVerticesMapping.containsKey(currentVertex.getVertexId())) { return; } List<ExecutionVertex> transformChainedVertices = new ArrayList<>(); collectChainedVertices( currentVertex, transformChainedVertices, executionEdges, inputVerticesMap, targetVerticesMap); // If the list is not empty, it means the Transform nodes in the list can be merged into one if (transformChainedVertices.size() > 0) { long newVertexId = idGenerator.getNextId(); List<SeaTunnelTransform> transforms = new ArrayList<>(transformChainedVertices.size()); List<String> names = new ArrayList<>(transformChainedVertices.size()); Set<URL> jars = new HashSet<>(); Set<ConnectorJarIdentifier> identifiers = new HashSet<>(); transformChainedVertices.stream() .peek( // Add all historical node IDs and new node IDs to the mapping vertex -> chainedTransformVerticesMapping.put( vertex.getVertexId(), newVertexId)) .map(ExecutionVertex::getAction) .map(action -> (TransformAction) action) .forEach( action -> { transforms.add(action.getTransform()); jars.addAll(action.getJarUrls()); identifiers.addAll(action.getConnectorJarIdentifiers()); names.add(action.getName()); }); String transformChainActionName = String.format("TransformChain[%s]", String.join("->", names)); // Merge multiple TransformActions into one TransformChainAction TransformChainAction transformChainAction = new TransformChainAction( newVertexId, transformChainActionName, jars, identifiers, transforms); transformChainAction.setParallelism(currentVertex.getAction().getParallelism()); ExecutionVertex executionVertex = new ExecutionVertex( newVertexId, transformChainAction, currentVertex.getParallelism()); // Store the modified node information in the state transformChainVertexMap.put(newVertexId, executionVertex); chainedTransformVerticesMapping.put( currentVertex.getVertexId(), executionVertex.getVertexId()); } } private void collectChainedVertices( ExecutionVertex currentVertex, List<ExecutionVertex> chainedVertices, Set<ExecutionEdge> executionEdges, Map<Long, List<ExecutionVertex>> inputVerticesMap, Map<Long, List<ExecutionVertex>> targetVerticesMap) { Action action = currentVertex.getAction(); // Only merge TransformAction if (action instanceof TransformAction) { if (chainedVertices.size() == 0) { // If the list of vertices to be merged is empty, add itself to the list // The condition for entering this branch is that the current node is a TransformAction and the list to be merged is empty // There may be several scenarios: the first Transform node enters, and this Transform node has no constraints chainedVertices.add(currentVertex); } else if (inputVerticesMap.get(currentVertex.getVertexId()).size() == 1) { // When this condition is entered, it means: // The list of vertices to be merged already has at least one TransformAction // The scenario at this point is that the upstream Transform node has only one downstream node, ie, the current node. This constraint is ensured by the following judgment // Chain the current TransformAction node with the previous TransformAction node // Delete this relationship from the execution plan executionEdges.remove( new ExecutionEdge( chainedVertices.get(chainedVertices.size() - 1), currentVertex)); // Add itself to the list of nodes to be merged chainedVertices.add(currentVertex); } else { return; } } else { return; } // It cannot chain to any target vertex if it has multiple target vertices. if (targetVerticesMap.get(currentVertex.getVertexId()).size() == 1) { // If the current node has only one downstream node, try chaining again // If the current node has multiple downstream nodes, it will not chain the downstream nodes, so it can be ensured that the above chaining is a one-to-one relationship // This call occurs when the Transform node has only one downstream node collectChainedVertices( targetVerticesMap.get(currentVertex.getVertexId()).get(0), chainedVertices, executionEdges, inputVerticesMap, targetVerticesMap); } }4 ګام
private List<Pipeline> generatePipelines(Set<ExecutionEdge> executionEdges) { // Stores each execution plan node Set<ExecutionVertex> executionVertices = new LinkedHashSet<>(); for (ExecutionEdge edge : executionEdges) { executionVertices.add(edge.getLeftVertex()); executionVertices.add(edge.getRightVertex()); } // Calls the Pipeline generator to convert the execution plan into Pipelines PipelineGenerator pipelineGenerator = new PipelineGenerator(executionVertices, new ArrayList<>(executionEdges)); List<Pipeline> pipelines = pipelineGenerator.generatePipelines(); Set<String> duplicatedActionNames = new HashSet<>(); Set<String> actionNames = new HashSet<>(); for (Pipeline pipeline : pipelines) { Integer pipelineId = pipeline.getId(); for (ExecutionVertex vertex : pipeline.getVertexes().values()) { // Get each execution node of the current Pipeline, reset the Action name, and add the pipeline name Action action = vertex.getAction(); String actionName = String.format("pipeline-%s [%s]", pipelineId, action.getName()); action.setName(actionName); if (actionNames.contains(actionName)) { duplicatedActionNames.add(actionName); } actionNames.add(action Name); } } if (duplicatedActionNames.size() > 0) { throw new RuntimeException( String.format( "Duplicated Action names found: %s", duplicatedActionNames)); } return pipelines; } public PipelineGenerator(Collection<ExecutionVertex> vertices, List<ExecutionEdge> edges) { this.vertices = vertices; this.edges = edges; } public List<Pipeline> generatePipelines() { List<ExecutionEdge> executionEdges = expandEdgeByParallelism(edges); // Split the execution plan into unrelated execution plans based on their relationships // Divide into several unrelated execution plans List<List<ExecutionEdge>> edgesList = splitUnrelatedEdges(executionEdges); edgesList = edgesList.stream() .flatMap(e -> this.splitUnionEdge(e).stream()) .collect(Collectors.toList()); // Just convert execution plan to pipeline at now. We should split it to multi pipeline with // cache in the future IdGenerator idGenerator = new IdGenerator(); // Convert execution plan graph to Pipeline return edgesList.stream() .map( e -> { Map<Long, ExecutionVertex> vertexes = new HashMap<>(); List<ExecutionEdge> pipelineEdges = e.stream() .map( edge -> { if (!vertexes.containsKey( edge.getLeftVertexId())) { vertexes.put( edge.getLeftVertexId(), edge.getLeftVertex()); } ExecutionVertex source = vertexes.get( edge.getLeftVertexId()); if (!vertexes.containsKey( edge.getRightVertexId())) { vertexes.put( edge.getRightVertexId(), edge.getRightVertex()); } ExecutionVertex destination = vertexes.get( edge.getRightVertexId()); return new ExecutionEdge( source, destination); }) .collect(Collectors.toList()); return new Pipeline( (int) idGenerator.getNextId(), pipelineEdges, vertexes); }) .collect(Collectors.toList()); }- 5 ګام
لنډیز:
د اجرا پلان په منطقي پلان کې لاندې دندې ترسره کوي:- کله چې یوه سرچینه ډیری جدولونه رامینځته کوي او ډیری سینک نوډونه پدې سرچینې پورې اړه لري ، نو په مینځ کې یو شفل نوډ اضافه کیږي.
- د زنځیر ضم کولو لیږد نوډونو هڅه کول ، په یو نوډ کې د څو ټرانسفارم نوډونو سره یوځای کول.
- دندې تقسیم کړئ،
configuration file/LogicalDagپه څو غیر اړونده کارونو ویشل چېList<Pipeline>په توګه ښودل شوي.
د فزیکي پلان تولید
مخکې له دې چې د فزیکي پلان تولید ته پام وکړو، راځئ لومړی بیا کتنه وکړو چې کوم معلومات په تولید شوي فزیکي پلان کې شامل دي او د هغې داخلي برخې معاینه کړئ. public class PhysicalPlan { private final List<SubPlan> pipelineList; private final AtomicInteger finishedPipelineNum = new AtomicInteger(0); private final AtomicInteger canceledPipelineNum = new AtomicInteger(0); private final AtomicInteger failedPipelineNum = new AtomicInteger(0); private final JobImmutableInformation jobImmutableInformation; private final IMap<Object, Object> runningJobStateIMap; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private CompletableFuture<JobResult> jobEndFuture; private final AtomicReference<String> errorBySubPlan = new AtomicReference<>(); private final String jobFullName; private final long jobId; private JobMaster jobMaster; private boolean makeJobEndWhenPipelineEnded = true; private volatile boolean isRunning = false; }
په دې ټولګي کې، کلیدي ساحه ده pipelineList ، کوم چې د SubPlan مثالونو لیست دی:
public class SubPlan { private final int pipelineMaxRestoreNum; private final int pipelineRestoreIntervalSeconds; private final List<PhysicalVertex> physicalVertexList; private final List<PhysicalVertex> coordinatorVertexList; private final int pipelineId; private final AtomicInteger finishedTaskNum = new AtomicInteger(0); private final AtomicInteger canceledTaskNum = new AtomicInteger(0); private final AtomicInteger failedTaskNum = new AtomicInteger(0); private final String pipelineFullName; private final IMap<Object, Object> runningJobStateIMap; private final Map<String, String> tags; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private CompletableFuture<PipelineExecutionState> pipelineFuture; private final PipelineLocation pipelineLocation; private AtomicReference<String> errorByPhysicalVertex = new AtomicReference<>(); private final ExecutorService executorService; private JobMaster jobMaster; private PassiveCompletableFuture<Void> reSchedulerPipelineFuture; private Integer pipelineRestoreNum; private final Object restoreLock = new Object(); private volatile PipelineStatus currPipelineStatus; public volatile boolean isRunning = false; private Map<TaskGroupLocation, SlotProfile> slotProfiles; }
د SubPlan ټولګي PhysicalVertex مثالونو لیست ساتي، په فزیکي پلان نوډونو او همغږي کونکي نوډونو ویشل شوي:
public class PhysicalVertex { private final TaskGroupLocation taskGroupLocation; private final String taskFullName; private final TaskGroupDefaultImpl taskGroup; private final ExecutorService executorService; private final FlakeIdGenerator flakeIdGenerator; private final Set<URL> pluginJarsUrls; private final Set<ConnectorJarIdentifier> connectorJarIdentifiers; private final IMap<Object, Object> runningJobStateIMap; private CompletableFuture<TaskExecutionState> taskFuture; private final IMap<Object, Long[]> runningJobStateTimestampsIMap; private final NodeEngine nodeEngine; private JobMaster jobMaster; private volatile ExecutionState currExecutionState = ExecutionState.CREATED; public volatile boolean isRunning = false; private AtomicReference<String> errorByPhysicalVertex = new AtomicReference<>(); } public class TaskGroupDefaultImpl implements TaskGroup { private final TaskGroupLocation taskGroupLocation; private final String taskGroupName; // Stores the tasks that the physical node needs to execute // Each task could be for reading data, writing data, data splitting, checkpoint tasks, etc. private final Map<Long, Task> tasks; }
PhysicalPlanGenerator مسؤل دی چې د اجرا کولو پلان په SeaTunnelTask کې بدل کړي او د همغږۍ مختلف دندې اضافه کړي لکه د ډیټا ویشل ، د معلوماتو ژمنې ، او د پلي کولو پرمهال د پوستې دندې.
public PhysicalPlanGenerator( @NonNull ExecutionPlan executionPlan, @NonNull NodeEngine nodeEngine, @NonNull JobImmutableInformation jobImmutableInformation, long initializationTimestamp, @NonNull ExecutorService executorService, @NonNull FlakeIdGenerator flakeIdGenerator, @NonNull IMap runningJobStateIMap, @NonNull IMap runningJobStateTimestampsIMap, @NonNull QueueType queueType) { this.pipelines = executionPlan.getPipelines(); this.nodeEngine = nodeEngine; this.jobImmutableInformation = jobImmutableInformation; this.initializationTimestamp = initializationTimestamp; this.executorService = executorService; this.flakeIdGenerator = flakeIdGenerator; // the checkpoint of a pipeline this.pipelineTasks = new HashSet<>(); this.startingTasks = new HashSet<>(); this.subtaskActions = new HashMap<>(); this.runningJobStateIMap = runningJobStateIMap; this.runningJobStateTimestampsIMap = runningJobStateTimestampsIMap; this.queueType = queueType; } public Tuple2<PhysicalPlan, Map<Integer, CheckpointPlan>> generate() { // Get the node filter conditions from user configuration to select the nodes where tasks will run Map<String, String> tagFilter = (Map<String, String>) jobImmutableInformation .getJobConfig() .getEnvOptions() .get(EnvCommonOptions.NODE_TAG_FILTER.key()); // TODO Determine which tasks do not need to be restored according to state CopyOnWriteArrayList<PassiveCompletableFuture<PipelineStatus>> waitForCompleteBySubPlanList = new CopyOnWriteArrayList<>(); Map<Integer, CheckpointPlan> checkpointPlans = new HashMap<>(); final int totalPipelineNum = pipelines.size(); Stream<SubPlan> subPlanStream = pipelines.stream() .map( pipeline -> { // Clear the state each time this.pipelineTasks.clear(); this.startingTasks.clear(); this.subtaskActions.clear(); final int pipelineId = pipeline.getId(); // Get current task information final List<ExecutionEdge> edges = pipeline.getEdges(); // Get all SourceActions List<SourceAction<?, ?, ?>> sources = findSourceAction(edges); // Generate Source data slice tasks, ie, SourceSplitEnumeratorTask // This task calls the SourceSplitEnumerator class in the connector if supported List<PhysicalVertex> coordinatorVertexList = getEnumeratorTask( sources, pipelineId, totalPipelineNum); // Generate Sink commit tasks, ie, SinkAggregatedCommitterTask // This task calls the SinkAggregatedCommitter class in the connector if supported // These two tasks are executed as coordination tasks coordinatorVertexList.addAll( getCommitterTask(edges, pipelineId, totalPipelineNum)); List<PhysicalVertex> physicalVertexList = getSourceTask( edges, sources, pipelineId, totalPipelineNum); // physicalVertexList.addAll( getShuffleTask(edges, pipelineId, totalPipelineNum)); CompletableFuture<PipelineStatus> pipelineFuture = new CompletableFuture<>(); waitForCompleteBySubPlanList.add( new PassiveCompletableFuture<>(pipelineFuture)); // Add checkpoint tasks checkpointPlans.put( pipelineId, CheckpointPlan.builder() .pipelineId(pipelineId) .pipelineSubtasks(pipelineTasks) .startingSubtasks(startingTasks) .pipelineActions(pipeline.getActions()) .subtaskActions(subtaskActions) .build()); return new SubPlan( pipelineId, totalPipelineNum, initializationTimestamp, physicalVertexList, coordinatorVertexList, jobImmutableInformation, executorService, runningJobStateIMap, runningJobStateTimestampsIMap, tagFilter); }); PhysicalPlan physicalPlan = new PhysicalPlan( subPlanStream.collect(Collectors.toList()), executorService, jobImmutableInformation, initializationTimestamp, runningJobStateIMap, runningJobStateTimestampsIMap); return Tuple2.tuple2(physicalPlan, checkpointPlans); } د فزیکي پلان رامینځته کولو پروسه کې د اجرا کولو پلان په SeaTunnelTask کې بدلول او د همغږۍ مختلف دندې شاملول شامل دي ، لکه د ډیټا ویشلو دندې ، د معلوماتو ژمنې دندې ، او د پوستې دندې.
په SeaTunnelTask کې، دندې په SourceFlowLifeCycle , SinkFlowLifeCycle , TransformFlowLifeCycle , ShuffleSinkFlowLifeCycle , ShuffleSourceFlowLifeCycle کې بدلیږي .
د مثال په توګه، د SourceFlowLifeCycle او SinkFlowLifeCycle ټولګي په لاندې ډول دي:
- سرچینه فلو لائف سائیکل
@Override public void init() throws Exception { this.splitSerializer = sourceAction.getSource().getSplitSerializer(); this.reader = sourceAction .getSource() .createReader( new SourceReaderContext( indexID, sourceAction.getSource().getBoundedness(), this, metricsContext, eventListener)); this.enumeratorTaskAddress = getEnumeratorTaskAddress(); } @Override public void open() throws Exception { reader.open(); register(); } public void collect() throws Exception { if (!prepareClose) { if (schemaChanging()) { log.debug("schema is changing, stop reader collect records"); Thread.sleep(200); return; } reader.pollNext(collector); if (collector.isEmptyThisPollNext()) { Thread.sleep(100); } else { collector.resetEmptyThisPollNext(); /** * The current thread obtain a checkpoint lock in the method {@link * SourceReader#pollNext( Collector)}. When trigger the checkpoint or savepoint, * other threads try to obtain the lock in the method {@link * SourceFlowLifeCycle#triggerBarrier(Barrier)}. When high CPU load, checkpoint * process may be blocked as long time. So we need sleep to free the CPU. */ Thread.sleep(0L); } if (collector.captureSchemaChangeBeforeCheckpointSignal()) { if (schemaChangePhase.get() != null) { throw new IllegalStateException( "previous schema changes in progress, schemaChangePhase: " + schemaChangePhase.get()); } schemaChangePhase.set(SchemaChangePhase.createBeforePhase()); runningTask.triggerSchemaChangeBeforeCheckpoint().get(); log.info("triggered schema-change-before checkpoint, stopping collect data"); } else if (collector.captureSchemaChangeAfterCheckpointSignal()) { if (schemaChangePhase.get() != null) { throw new IllegalStateException( "previous schema changes in progress, schemaChangePhase: " + schemaChangePhase.get()); } schemaChangePhase.set(SchemaChangePhase.createAfterPhase()); runningTask.triggerSchemaChangeAfterCheckpoint().get(); log.info("triggered schema-change-after checkpoint, stopping collect data"); } } else { Thread.sleep(100); } } په SourceFlowLifeCycle کې، د معلوماتو لوستل د collect میتود کې ترسره کیږي. یوځل چې ډاټا لوستل شي، دا د SeaTunnelSourceCollector کې ځای پرځای کیږي. کله چې ډاټا ترلاسه شي، راټولونکی میټریک تازه کوي او ډاټا د زیرمې برخو ته لیږي.
@Override public void collect(T row) { try { if (row instanceof SeaTunnelRow) { String tableId = ((SeaTunnelRow) row).getTableId(); int size; if (rowType instanceof SeaTunnelRowType) { size = ((SeaTunnelRow) row).getBytesSize((SeaTunnelRowType) rowType); } else if (rowType instanceof MultipleRowType) { size = ((SeaTunnelRow) row).getBytesSize(rowTypeMap.get(tableId)); } else { throw new SeaTunnelEngineException( "Unsupported row type: " + rowType.getClass().getName()); } sourceReceivedBytes.inc(size); sourceReceivedBytesPerSeconds.markEvent(size); flowControlGate.audit((SeaTunnelRow) row); if (StringUtils.isNotEmpty(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sourceTableCounter = sourceReceivedCountPerTable.get(tableName); if (Objects.nonNull(sourceTableCounter)) { sourceTableCounter.inc(); } else { Counter counter = metricsContext.counter(SOURCE_RECEIVED_COUNT + "#" + tableName); counter.inc(); sourceReceivedCountPerTable.put(tableName, counter); } } } sendRecordToNext(new Record<>(row)); emptyThisPollNext = false; sourceReceivedCount.inc(); sourceReceivedQPS.markEvent(); } catch (IOException e) { throw new RuntimeException(e); } } public void sendRecordToNext(Record<?> record) throws IOException { synchronized (checkpointLock) { for (OneInputFlowLifeCycle<Record<?>> output : outputs) { output.received(record); } } }- SinkFlowLifeCycle
@Override public void received(Record<?> record) { try { if (record.getData() instanceof Barrier) { long startTime = System.currentTimeMillis(); Barrier barrier = (Barrier) record.getData(); if (barrier.prepareClose(this.taskLocation)) { prepareClose = true; } if (barrier.snapshot()) { try { lastCommitInfo = writer.prepareCommit(); } catch (Exception e) { writer.abortPrepare(); throw e; } List<StateT> states = writer.snapshotState(barrier.getId()); if (!writerStateSerializer.isPresent()) { runningTask.addState( barrier, ActionStateKey.of(sinkAction), Collections.emptyList()); } else { runningTask.addState( barrier, ActionStateKey.of(sinkAction), serializeStates(writerStateSerializer.get(), states)); } if (containAggCommitter) { CommitInfoT commitInfoT = null; if (lastCommitInfo.isPresent()) { commitInfoT = lastCommitInfo.get(); } runningTask .getExecutionContext() .sendToMember( new SinkPrepareCommitOperation<CommitInfoT>( barrier, committerTaskLocation, commitInfoSerializer.isPresent() ? commitInfoSerializer .get() .serialize(commitInfoT) : null), committerTaskAddress) .join(); } } else { if (containAggCommitter) { runningTask .getExecutionContext() .sendToMember( new BarrierFlowOperation(barrier, committerTaskLocation), committerTaskAddress) .join(); } } runningTask.ack(barrier); log.debug( "trigger barrier [{}] finished, cost {}ms. taskLocation [{}]", barrier.getId(), System.currentTimeMillis() - startTime, taskLocation); } else if (record.getData() instanceof SchemaChangeEvent) { if (prepareClose) { return; } SchemaChangeEvent event = (SchemaChangeEvent) record.getData(); writer.applySchemaChange(event); } else { if (prepareClose) { return; } writer.write((T) record.getData()); sinkWriteCount.inc(); sinkWriteQPS.markEvent(); if (record.getData() instanceof SeaTunnelRow) { long size = ((SeaTunnelRow) record.getData()).getBytesSize(); sinkWriteBytes.inc(size); sinkWriteBytesPerSeconds.markEvent(size); String tableId = ((SeaTunnelRow) record.getData()).getTableId(); if (StringUtils.isNotBlank(tableId)) { String tableName = getFullName(TablePath.of(tableId)); Counter sinkTableCounter = sinkWriteCountPerTable.get(tableName); if (Objects.nonNull(sinkTableCounter)) { sinkTableCounter.inc(); } else { Counter counter = metricsContext.counter(SINK_WRITE_COUNT + "#" + tableName); counter.inc(); sinkWriteCountPerTable.put(tableName, counter); } } } } } catch (Exception e) { throw new RuntimeException(e); } }د دندې اجرا کول
په CoordinatorService کې، فزیکي پلان د init میتود له لارې رامینځته کیږي، او بیا د run طریقه ویل کیږي چې واقعیا کار پیل کړي.
CoordinatorService { jobMaster.init( runningJobInfoIMap.get(jobId).getInitializationTimestamp(), false); ... jobMaster.run(); } JobMaster { public void run() { ... physicalPlan.startJob(); ... } }
په JobMaster کې، کله چې دنده پیل کړئ، دا د PhysicalPlan د startJob میتود ته وایي.
public void startJob() { isRunning = true; log.info("{} state process is start", getJobFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process is stopped", jobFullName)); return; } switch (getJobStatus()) { case CREATED: updateJobState(JobStatus.SCHEDULED); break; case SCHEDULED: getPipelineList() .forEach( subPlan -> { if (PipelineStatus.CREATED.equals( subPlan.getCurrPipelineStatus())) { subPlan.startSubPlanStateProcess(); } }); updateJobState(JobStatus.RUNNING); break; case RUNNING: case DOING_SAVEPOINT: break; case FAILING: case CANCELING: jobMaster.neverNeedRestore(); getPipelineList().forEach(SubPlan::cancelPipeline); break; case FAILED: case CANCELED: case SAVEPOINT_DONE: case FINISHED: stopJobStateProcess(); jobEndFuture.complete(new JobResult(getJobStatus(), errorBySubPlan.get())); return; default: throw new IllegalArgumentException("Unknown Job State: " + getJobStatus()); } } په PhysicalPlan کې، د یوې دندې پیل کول د دندې وضعیت SCHEDULED ته تازه کوي او بیا د SubPlan د پیل میتود ته زنګ وهي.
public void startSubPlanStateProcess() { isRunning = true; log.info("{} state process is start", getPipelineFullName()); stateProcess(); } private synchronized void stateProcess() { if (!isRunning) { log.warn(String.format("%s state process not start", pipelineFullName)); return; } PipelineStatus state = getCurrPipelineStatus(); switch (state) { case CREATED: updatePipelineState(PipelineStatus.SCHEDULED); break; case SCHEDULED: try { ResourceUtils.applyResourceForPipeline(jobMaster.getResourceManager(), this); log.debug( "slotProfiles: {}, PipelineLocation: {}", slotProfiles, this.getPipelineLocation()); updatePipelineState(PipelineStatus.DEPLOYING); } catch (Exception e) { makePipelineFailing(e); } break; case DEPLOYING: coordinatorVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); physicalVertexList.forEach( task -> { if (task.getExecutionState().equals(ExecutionState.CREATED)) { task.startPhysicalVertex(); task.makeTaskGroupDeploy(); } }); updatePipelineState(PipelineStatus.RUNNING); break; case RUNNING: break; case FAILING: case CANCELING: coordinatorVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); physicalVertexList.forEach( task -> { task.startPhysicalVertex(); task.cancel(); }); break; case FAILED: case CANCELED: if (checkNeedRestore(state) && prepareRestorePipeline()) { jobMaster.releasePipelineResource(this); restorePipeline(); return; } subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState(pipelineId, state, errorByPhysicalVertex.get())); return; case FINISHED: subPlanDone(state); stopSubPlanStateProcess(); pipelineFuture.complete( new PipelineExecutionState( pipelineId, getPipelineState(), errorByPhysicalVertex.get())); return; default: throw new IllegalArgumentException("Unknown Pipeline State: " + getPipelineState()); } } په SubPlan کې، سرچینې د ټولو دندو لپاره کارول کیږي. د سرچینې غوښتنلیک د ResourceManager له لارې ترسره کیږي. د سرچینې غوښتنلیک په جریان کې، نوډونه د کارونکي لخوا ټاکل شوي ټاګونو پراساس غوره کیږي ترڅو ډاډ ترلاسه شي چې دندې په ځانګړي نوډونو کې پرمخ ځي، د سرچینې انزوا ترلاسه کول.
public static void applyResourceForPipeline( @NonNull ResourceManager resourceManager, @NonNull SubPlan subPlan) { Map<TaskGroupLocation, CompletableFuture<SlotProfile>> futures = new HashMap<>(); Map<TaskGroupLocation, SlotProfile> slotProfiles = new HashMap<>(); // TODO If there is no enough resources for tasks, we need add some wait profile subPlan.getCoordinatorVertexList() .forEach( coordinator -> futures.put( coordinator.getTaskGroupLocation(), applyResourceForTask( resourceManager, coordinator, subPlan.getTags()))); subPlan.getPhysicalVertexList() .forEach( task -> futures.put( task.getTaskGroupLocation(), applyResourceForTask( resourceManager, task, subPlan.getTags()))); futures.forEach( (key, value) -> { try { slotProfiles.put(key, value == null ? null : value.join()); } catch (CompletionException e) { // do nothing } }); // set it first, avoid can't get it when get resource not enough exception and need release // applied resource subPlan.getJobMaster().setOwnedSlotProfiles(subPlan.getPipelineLocation(), slotProfiles); if (futures.size() != slotProfiles.size()) { throw new NoEnoughResourceException(); } } public static CompletableFuture<SlotProfile> applyResourceForTask( ResourceManager resourceManager, PhysicalVertex task, Map<String, String> tags) { // TODO custom resource size return resourceManager.applyResource( task.getTaskGroupLocation().getJobId(), new ResourceProfile(), tags); } public CompletableFuture<List<SlotProfile>> applyResources( long jobId, List<ResourceProfile> resourceProfile, Map<String, String> tagFilter) throws NoEnoughResourceException { waitingWorkerRegister(); ConcurrentMap<Address, WorkerProfile> matchedWorker = filterWorkerByTag(tagFilter); if (matchedWorker.isEmpty()) { log.error("No matched worker with tag filter {}.", tagFilter); throw new NoEnoughResourceException(); } return new ResourceRequestHandler(jobId, resourceProfile, matchedWorker, this) .request(tagFilter); } کله چې ټول موجود نوډونه ترلاسه شي، نوډونه بدلیږي او یو نوډ د اړتیا وړ سرچینو څخه لوی سرچینې سره په تصادفي ډول غوره کیږي. نوډ بیا اړیکه نیول کیږي، او یو RequestSlotOperation ورته لیږل کیږي.
public Optional<WorkerProfile> preCheckWorkerResource(ResourceProfile r) { // Shuffle the order to ensure random selection of workers List<WorkerProfile> workerProfiles = Arrays.asList(registerWorker.values().toArray(new WorkerProfile[0])); Collections.shuffle(workerProfiles); // Check if there are still unassigned slots Optional<WorkerProfile> workerProfile = workerProfiles.stream() .filter( worker -> Arrays.stream(worker.getUnassignedSlots()) .anyMatch( slot -> slot.getResourceProfile() .enoughThan(r))) .findAny(); if (!workerProfile.isPresent()) { // Check if there are still unassigned resources workerProfile = workerProfiles.stream() .filter(WorkerProfile::isDynamicSlot) .filter(worker -> worker.getUnassignedResource().enoughThan(r)) .findAny(); } return workerProfile; } private CompletableFuture<SlotAndWorkerProfile> singleResourceRequestToMember( int i, ResourceProfile r, WorkerProfile workerProfile) { CompletableFuture<SlotAndWorkerProfile> future = resourceManager.sendToMember( new RequestSlotOperation(jobId, r), workerProfile.getAddress()); return future.whenComplete( withTryCatch( LOGGER, (slotAndWorkerProfile, error) -> { if (error != null) { throw new RuntimeException(error); } else { resourceManager.heartbeat(slotAndWorkerProfile.getWorkerProfile()); addSlotToCacheMap(i, slotAndWorkerProfile.getSlotProfile()); } })); } کله چې د نوډ SlotService د requestSlot غوښتنه ترلاسه کړي، دا خپل معلومات تازه کوي او ماسټر نوډ ته یې بیرته راولي. که د سرچینې غوښتنه تمه شوې پایلې پوره نه کړي، نو NoEnoughResourceException اچول کیږي، چې د دندې ناکامي په ګوته کوي. کله چې د منابعو تخصیص بریالی شي، د دندې ګمارل د task.makeTaskGroupDeploy() سره پیل کیږي، کوم چې دنده د worker نوډ ته د اجرا کولو لپاره لیږي.
TaskDeployState deployState = deploy(jobMaster.getOwnedSlotProfiles(taskGroupLocation)); public TaskDeployState deploy(@NonNull SlotProfile slotProfile) { try { if (slotProfile.getWorker().equals(nodeEngine.getThisAddress())) { return deployOnLocal(slotProfile); } else { return deployOnRemote(slotProfile); } } catch (Throwable th) { return TaskDeployState.failed(th); } } private TaskDeployState deployOnRemote(@Non Null SlotProfile slotProfile) { return deployInternal( taskGroupImmutableInformation -> { try { return (TaskDeployState) NodeEngineUtil.sendOperationToMemberNode( nodeEngine, new DeployTaskOperation( slotProfile, nodeEngine .getSerializationService() .toData( taskGroupImmutableInformation)), slotProfile.getWorker()) .get(); } catch (Exception e) { if (getExecutionState().isEndState()) { log.warn(ExceptionUtils.getMessage(e)); log.warn( String.format( "%s deploy error, but the state is already in end state %s, skip this error", getTaskFullName(), currExecutionState)); return TaskDeployState.success(); } else { return TaskDeployState.failed(e); } } }); }د دندې ګمارل
کله چې د دندې ځای په ځای کول، د دندې معلومات د سرچینې تخصیص په وخت کې ترلاسه شوي نوډ ته لیږل کیږي: public TaskDeployState deployTask(@NonNull Data taskImmutableInformation) { TaskGroupImmutableInformation taskImmutableInfo = nodeEngine.getSerializationService().toObject(taskImmutableInformation); return deployTask(taskImmutableInfo); } public TaskDeployState deployTask(@NonNull TaskGroupImmutableInformation taskImmutableInfo) { logger.info( String.format( "received deploying task executionId [%s]", taskImmutableInfo.getExecutionId())); TaskGroup taskGroup = null; try { Set<ConnectorJarIdentifier> connectorJarIdentifiers = taskImmutableInfo.getConnectorJarIdentifiers(); Set<URL> jars = new HashSet<>(); ClassLoader classLoader; if (!CollectionUtils.isEmpty(connectorJarIdentifiers)) { // Prioritize obtaining the jar package file required for the current task execution // from the local, if it does not exist locally, it will be downloaded from the // master node. jars = serverConnectorPackageClient.getConnectorJarFromLocal( connectorJarIdentifiers); } else if (!CollectionUtils.isEmpty(taskImmutableInfo.getJars())) { jars = taskImmutableInfo.getJars(); } classLoader = classLoaderService.getClassLoader( taskImmutableInfo.getJobId(), Lists.newArrayList(jars)); if (jars.isEmpty()) { taskGroup = nodeEngine.getSerializationService().toObject(taskImmutableInfo.getGroup()); } else { taskGroup = CustomClassLoadedObject.deserializeWithCustomClassLoader( nodeEngine.getSerializationService(), classLoader, taskImmutableInfo.getGroup()); } logger.info( String.format( "deploying task %s, executionId [%s]", taskGroup.getTaskGroupLocation(), taskImmutableInfo.getExecutionId())); synchronized (this) { if (executionContexts.containsKey(taskGroup.getTaskGroupLocation())) { throw new RuntimeException( String.format( "TaskGroupLocation: %s already exists", taskGroup.getTaskGroupLocation())); } deployLocalTask(taskGroup, classLoader, jars); return TaskDeployState.success(); } } catch (Throwable t) { logger.severe( String.format( "TaskGroupID : %s deploy error with Exception: %s", taskGroup != null && taskGroup.getTaskGroupLocation() != null ? taskGroup.getTaskGroupLocation().toString() : "taskGroupLocation is null", ExceptionUtils.getMessage(t))); return TaskDeployState.failed(t); } } کله چې د کارګر نوډ وظیفه ترلاسه کوي، دا د TaskExecutionService deployTask میتود ته زنګ وهي ترڅو دنده په پیل کې رامینځته شوي تار پول ته وسپاري.
private final class BlockingWorker implements Runnable { private final TaskTracker tracker; private final CountDownLatch startedLatch; private BlockingWorker(TaskTracker tracker, CountDownLatch startedLatch) { this.tracker = tracker; this.startedLatch = startedLatch; } @Override public void run() { TaskExecutionService.TaskGroupExecutionTracker taskGroupExecutionTracker = tracker.taskGroupExecutionTracker; ClassLoader classLoader = executionContexts .get(taskGroupExecutionTracker.taskGroup.getTaskGroupLocation()) .getClassLoader(); ClassLoader oldClassLoader = Thread.currentThread().getContextClassLoader(); Thread.currentThread().setContextClassLoader(classLoader); final Task t = tracker.task; ProgressState result = null; try { startedLatch.countDown(); t.init(); do { result = t.call(); } while (!result.isDone() && isRunning && !taskGroupExecutionTracker.executionCompletedExceptionally()); ... } } د Task.call میتود غوښتنه شوې، او پدې توګه د معلوماتو همغږي کولو دندې واقعیا اجرا کیږي.
ClassLoader
په SeaTunnel کې، ډیفالټ ClassLoader د فرعي ټولګیو لومړیتوب ورکولو لپاره تعدیل شوی ترڅو د نورو برخو ټولګیو سره د شخړو مخه ونیسي: @Override public synchronized ClassLoader getClassLoader(long jobId, Collection<URL> jars) { log.debug("Get classloader for job {} with jars {}", jobId, jars); if (cacheMode) { // with cache mode, all jobs share the same classloader if the jars are the same jobId = 1L; } if (!classLoaderCache.containsKey(jobId)) { classLoaderCache.put(jobId, new ConcurrentHashMap<>()); classLoaderReferenceCount.put(jobId, new ConcurrentHashMap<>()); } Map<String, ClassLoader> classLoaderMap = classLoaderCache.get(jobId); String key = covertJarsToKey(jars); if (classLoaderMap.containsKey(key)) { classLoaderReferenceCount.get(jobId).get(key).incrementAndGet(); return classLoaderMap.get(key); } else { ClassLoader classLoader = new SeaTunnelChildFirstClassLoader(jars); log.info("Create classloader for job {} with jars {}", jobId, jars); classLoaderMap.put(key, classLoader); classLoaderReferenceCount.get(jobId).put(key, new AtomicInteger(1)); return classLoader; } }د REST API کاري سپارل
SeaTunnel د REST API له لارې د دندې سپارلو ملاتړ هم کوي. د دې خصوصیت د فعالولو لپاره، د hazelcast.yaml فایل ته لاندې تشکیلات اضافه کړئ:
network: rest-api: enabled: true endpoint-groups: CLUSTER_WRITE: enabled: true DATA: enabled: true د دې ترتیب اضافه کولو وروسته، د هیزلکاسټ نوډ به د HTTP غوښتنې ترلاسه کولو توان ولري.
public void handle(HttpPostCommand httpPostCommand) { String uri = httpPostCommand.getURI(); try { if (uri.startsWith(SUBMIT_JOB_URL)) { handleSubmitJob(httpPostCommand, uri); } else if (uri.startsWith(STOP_JOB_URL)) { handleStopJob(httpPostCommand, uri); } else if (uri.startsWith(ENCRYPT_CONFIG)) { handleEncrypt(httpPostCommand); } else { original.handle(httpPostCommand); } } catch (IllegalArgumentException e) { prepareResponse(SC_400, httpPostCommand, exceptionResponse(e)); } catch (Throwable e) { logger.warning("An error occurred while handling request " + httpPostCommand, e); prepareResponse(SC_500, httpPostCommand, exceptionResponse(e)); } this.textCommandService.sendResponse(httpPostCommand); } د دندې سپارلو غوښتنې اداره کولو طریقه د لارې لخوا ټاکل کیږي: private void handleSubmitJob(HttpPostCommand httpPostCommand, String uri) throws IllegalArgumentException { Map<String, String> requestParams = new HashMap<>(); RestUtil.buildRequestParams(requestParams, uri); Config config = RestUtil.buildConfig(requestHandle(httpPostCommand), false); ReadonlyConfig envOptions = ReadonlyConfig.fromConfig(config.getConfig("env")); String jobName = envOptions.get(EnvCommonOptions.JOB_NAME); JobConfig jobConfig = new JobConfig(); jobConfig.setName( StringUtils.isEmpty(requestParams.get(RestConstant.JOB_NAME)) ? jobName : requestParams.get(RestConstant.JOB_NAME)); boolean startWithSavePoint = Boolean.parseBoolean(requestParams.get(RestConstant.IS_START_WITH_SAVE_POINT)); String jobIdStr = requestParams.get(RestConstant.JOB_ID); Long finalJobId = StringUtils.isNotBlank(jobIdStr) ? Long.parseLong(jobIdStr) : null; SeaTunnelServer seaTunnelServer = getSeaTunnelServer(); RestJobExecutionEnvironment restJobExecutionEnvironment = new RestJobExecutionEnvironment( seaTunnelServer, jobConfig, config, textCommandService.getNode(), startWithSavePoint, finalJobId); JobImmutableInformation jobImmutableInformation = restJobExecutionEnvironment.build(); long jobId = jobImmutableInformation.getJobId(); if (!seaTunnelServer.isMasterNode()) { NodeEngineUtil.sendOperationToMasterNode( getNode().nodeEngine, new SubmitJobOperation( jobId, getNode().nodeEngine.toData(jobImmutableInformation), jobImmutableInformation.isStartWithSavePoint())) .join(); } else { submitJob(seaTunnelServer, jobImmutableInformation, jobConfig); } this.prepareResponse( httpPostCommand, new JsonObject() .add(RestConstant.JOB_ID, String.valueOf(jobId)) .add(RestConstant.JOB_NAME, jobConfig.getName())); } دلته منطق د مراجعینو اړخ ته ورته دی. له هغه ځایه چې هیڅ ځایی حالت شتون نلري ، نو سیمه ایز خدمت رامینځته کولو ته اړتیا نلري.
د پیرودونکي اړخ کې ، د ClientJobExecutionEnvironment ټولګي د منطقي پلان پارس کولو لپاره کارول کیږي ، او په ورته ډول ، د RestJobExecutionEnvironment ټولګي ورته دندې ترسره کوي.
که اوسنی نوډ ماسټر نوډ وي، نو دا به په مستقیم ډول د submitJob میتود ته زنګ ووهي، کوم چې د راتلونکی پروسس لپاره د coordinatorService.submitJob میتود غوښتنه کوي:
private void submitJob( SeaTunnelServer seaTunnelServer, JobImmutableInformation jobImmutableInformation, JobConfig jobConfig) { CoordinatorService coordinatorService = seaTunnelServer.getCoordinatorService(); Data data = textCommandService .getNode() .nodeEngine .getSerializationService() .toData(jobImmutableInformation); PassiveCompletableFuture<Void> voidPassiveCompletableFuture = coordinatorService.submitJob( Long.parseLong(jobConfig.getJobContext().getJobId()), data, jobImmutableInformation.isStartWithSavePoint()); voidPassiveCompletableFuture.join(); } د سپارلو دواړه میتودونه د سپارلو اړخ کې منطقي پلان پارس کول او بیا ماسټر نوډ ته د معلوماتو لیږل شامل دي. ماسټر نوډ بیا د فزیکي پلان تحلیل، تخصیص، او نور عملیات ترسره کوي.L O A D I N G
. . . comments & more!
. . . comments & more!



