






























































































Jan 01, 1970
4,748 讀數
什么是 GitOps 以及为什么它(几乎)没用:第 1 部分
太長; 讀書
本文讨论了 GitOps(基础设施配置管理中的一个概念)及其挑战。 GitOps 因其一致性、安全性和自动化优势而备受推崇。它利用 Git 存储库来管理基础设施和应用程序代码。本文介绍了 GitOps 原理、Flux 架构以及将 Helm 与 Flux 结合使用。它强调了 GitOps 在管理复杂依赖关系和维护单一事实来源方面的不足。下一部分将涵盖多环境、秘密、安全、回滚及其适用性等问题。
乘坐新航空公司。一名空姐进入客舱:“您乘坐的是我们的新航空公司。在飞机的机头,我们有一个电影院。在机尾,有一个老虎机大厅。在下层甲板上,有一个游泳池。在飞机上,我们有一个游泳池。”上层甲板——桑拿房。现在,先生们,系好安全带,带着所有这些不必要的东西,我们要尝试起飞。
嗨,我叫安德烈。我一生的大部分时间都在IT行业工作。我对基础设施配置管理工程的发展非常感兴趣。在过去的 8 年里,我一直参与DevOps 。
新的流行趋势之一是GitOps的概念,由 Weaveworks 首席执行官 Alexis Richardson 于 2017 年提出。 Weaveworks 是一家大型成人公司,2020 年筹集了超过 3600 万美元的投资来开发其 GitOps。
我的上一篇文章讨论了我们如何从 Elastic Stack 切换到 Grafana 的成本削减成功故事。现在,我将尝试谈谈在采用这个概念时可能会遇到的不明显的挑战。简而言之,GitOps 并不是“银弹”。您可能最终会通过许多复杂的解决方法进行重组。我自己也走过了这条路,并且想向您展示在阅读有关 GitOps 的其他文章时看不到的最令人沮丧的问题。
内容概述
- GitOps 是什么以及为什么你(不需要)需要它
- 雪花服务器问题
- GitOps - 解决您所有问题(或不是)的灵丹妙药
- 在 Helm 中使用 Flux 的逻辑
- 定制助焊剂资源
- GitOps 清单
- 违反单一事实来源概念
- 小结论
GitOps 是什么以及为什么你(不需要)需要它
让我们开始吧!
无状态和有状态
当今基础设施建设最有前景的概念是不可变的基础设施。其关键思想是将基础设施分为两个根本不同的部分:无状态和有状态。
基础设施的无状态部分是不可变的和幂等的。它不累积状态(不存储数据)或根据累积状态改变其操作。无状态部件的实例可能包含一些基本工件、脚本和程序集。通常,我从云/虚拟化环境中的基础映像创建它们。它们是脆弱且短暂的:我通过从新的基础映像重新创建实例来提供新版本的应用程序。
持久数据存储在Stateful部分。它可以通过具有专用服务器的经典方案或通过一些云机制(DBaaS、对象或块存储)来实现。
为了使这个“动物园”易于管理并正常工作,我们需要工程和 DevOps 团队之间的协作,以及完全自动化的交付管道。
持续集成部分
极限编程是敏捷开发方法之一。它的特点是有许多反馈循环,使您能够与客户的需求保持同步。
我们使用 CI/CD 系统实现交付管道的自动化。 CI(持续集成)一词由 Grady Booch 于 1994 年提出,1997 年 Kent Beck 和 Ron Jeffries 将其引入极限编程学科。在 CI 中,我们需要尽可能频繁地将更改集成到项目的主要工作分支中。
首先,这需要对任务进行更细粒度的分解:小的变化更加原子化,并且更容易跟踪、理解和集成。其次,我们不能仅仅合并新编写的代码。在合并分支之前,我们必须确保之前有效的内容没有被破坏。为此,至少应该构建应用程序。用测试覆盖代码也是一个好主意。
这就是 CI 系统执行的任务,它在开发中已经走了很长一段路,并且在这条道路的中间某个地方,变成了 CI/CD 系统。
光盘部分
什么是CD? :
持续交付。此时,借助持续集成实践和 DevOps 文化,您可以使项目的主要分支始终做好部署到生产的准备。
持续部署。这是持续交付,进入主分支的所有内容都会转储到您的集群和生产中。
让我们更进一步。
雪花服务器问题
不幸的是,不可变的基础设施有几个问题。其中大部分继承自基础设施即代码(IaC)的概念。
首先,是配置漂移。这个术语诞生于 Puppet Labs(著名的 Puppet SCM 的作者),指出并非目标系统上的所有更改都是在系统配置管理 (SCM) 的帮助下进行的。有些是手动完成的,绕过它们。
在这种多次更改的过程中,会出现配置漂移——SCM 中描述的配置与真实情况之间的差异。
这导致了自动化恐惧螺旋式上升。
手动更改越多,运行 SCM 脚本就越有可能破坏未记录的更改。运行它越可怕,就越有可能进行新的手动编辑。
最终,这种恶性的正反馈导致了雪花服务器的形成,这些服务器变得如此不一致,以至于没有人了解里面的内容。手动编辑后,节点变得与降雪中的每片雪花一样独特。
这种转变使服务器处于不可变基础设施中的更高级别:现在我们可以讨论 GCP 项目/AWS VPC/Kubernetes-cluster-snowflakes。发生这种情况是因为更改的实施不受不可变基础设施的监管。此外,没有人知道如何正确地做到这一点。
GitOps - 解决您所有问题(或不是)的灵丹妙药
然后 Weaveworks 出现并说:“伙计们,我们有你们需要的东西 - GitOps”。为了推广 GitOps,他们请来了像 Kelsey Hightower 这样的重量级人物,他创建了。在他的公关期间,他大量广播了这样的信息:“做一个男人,b...!停止编写脚本并开始发布。”他还说了一些营销废话。
在我看来,最令人兴奋的好处是:
- 提高部署的一致性和标准化
- 提高安全保障
- 更轻松、更快速地从错误中恢复
- 更轻松地管理访问和机密
- 自记录部署
- 团队内的知识分配
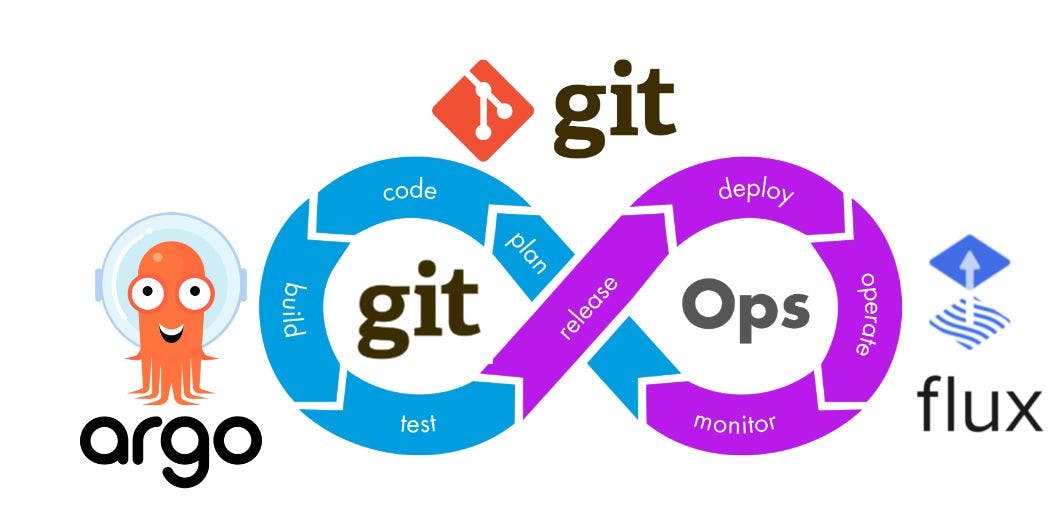
任何想要弄清楚 GitOps 是什么的人都会看到这张教科书幻灯片。
接下来,我们找到 GitOps 原则,它类似于稍微增强的 IaC 原则:
- GitOps 是声明式的
- GitOps 应用程序具有版本控制且不可变
- GitOps 应用程序会自动拉取
- GitOps 应用程序不断协调
然而,这是真空中的球形描述,因此我们继续我们的研究。我们找到了 GitOps.tech 网站,上面有一些重要的说明。
首先,我们了解到 GitOps 是 Git 中类似基础设施的代码,带有 CD 工具,可以自动将其应用到基础设施。
我们必须在 GitOps 中至少有 2 个存储库:
- 应用程序存储库。它描述了应用程序源代码和描述该应用程序部署的清单。
- 基础设施存储库。它描述了基础设施清单和部署环境。
此外,在 GitOps 意识形态中,面向拉的方法优于面向推的方法。这与 SCM 系统从重量级拉式怪物 Puppet 和 Chef 到轻量级推式 Ansible 和 Terraform 的演变有些相反。
如果 GitOps 主要是一个工具包故事,那么从 Weaveworks 本身获取基于 Flux 的概念并对其进行解构就有意义了。这个想法的作者一定已经做了一个参考实现。
Flux 现在已达到版本 2,其架构由在集群中工作的控制器组成:
- 源控制器
- 定制控制器
- 头盔控制器
- 通知控制器
- 图像自动化控制器
接下来,我们来讨论一下 Flux 和 Helm 的工作。
使用 Flux 与 Helm 的逻辑
我将进一步描述在 Flux 2 中使用 Helm 包管理器部署应用程序的示例。
为什么?根据,HELM 包管理器是最受欢迎的封装应用程序,份额超过 50%。
不幸的是,我无法找到更多最新数据,但我认为自那时以来没有发生太大变化。
那么,让我们来了解一下 Flux 2 如何与 Helm 配合使用的基本逻辑。我们有 2 个存储库:应用程序和基础设施。
我们从应用程序存储库制作 HELM Chart 和 docker 镜像,并将它们分别添加到 Helm Chart 存储库和 docker 注册表中。
接下来,我们有一个运行通量控制器的 Kubernetes 集群。
为了推出我们的应用程序,我们准备了一个描述自定义资源 (CR) HelmRelease 的 YAML,并将其添加到基础设施存储库中。
为了帮助 Flux 获取它,我们在 Kubernetes 集群中创建了一个 CR GitRepository。源控制器看到它,转到 git,然后下载它。
为了将此 YAML 部署到集群中,我们描述了一个自定义资源。
Kustomize 控制器看到它,转到源控制器,获取 YAML,并将其部署到集群。
Helm 控制器看到集群中出现了 CR HelmRelease,并转到 Source 控制器以获取所描述的 HELM 图表。
为了让源控制器向 HELM 控制器提供请求的图表,我们必须在 CR 集群中创建一个 HelmRepository。
Helm-controller 从 Source-controller 获取图表,创建版本并将其部署到集群。然后 Kubernetes 创建必要的 pod,进入 docker 注册表并下载相应的镜像。
因此,要推出应用程序的新版本,我们必须制作一个新映像、一个新的 HelmRelease 文件,可能还需要一个新的 HELM 图表。然后我们必须将它们放入适当的存储库中,并等待 Flux 控制器重复上述链中的工作。
并且,为了结束我们的工作,我们在某处放置了一个通知控制器,通知我们可能出了什么问题。
自定义通量资源
现在让我们讨论 Flux 操作的自定义资源。
第一个是 Git 存储库。在这里我们可以指定 Git 存储库的地址(第 14 行)及其查看的分支(第 10 行)。
因此,我们只下载一个分支,而不是整个存储库。但!由于我们是负责任的工程师并尝试遵守零信任概念,因此我们锁定对存储库的访问,使用 Kubernetes 集群中的密钥创建一个秘密并将其交给 Flux,以便它可以到达那里(第 12 行)。
接下来是定制化。在这里我想提请您注意这样一个事实:Flux 的 Kustomize 控制器和 Kubernetes 作者的 Kustomize 是两个不同的东西。我不知道为什么选择这样令人迷惑的命名,但重要的是不要混淆它们。
Kustomization 是一种将 YAML(任何)从 Git 存储库部署到集群的方法。这里我们必须指定我们放置它的源(第 12 行 - 上面描述的 CR GitRepository 的名称),我们从中获取 YAML 的目录(第 8 行),并且我们可以指定存放它们的目标命名空间(第 13 行)。
接下来是 Helm 版本。
在这里我们可以指定名称和图表版本(第 10,11 行)。您可以在此处指定变量值,以便 Helm 可以自定义不同环境的发布(第 15-19 行)。这是一项极其重要且必要的功能,因为您的环境可能存在很大差异。您还可以指定 Helm 图表的来源(第 12、13、14 行)。在本例中,它是 Helm 存储库。
但!由于我们仍然是负责任的工程师,因此我们还可以密切访问 Helm 存储库,并为 Flux 提供到达那里的秘密(第 7、8 行)。
GitOps 清单
那么,让我们做一个小清单来记录我们刚刚检查过的内容。要开始进行 GitOps,我们必须突然编写一堆脚本(我们确实记得不可变基础设施都是关于完全自动化的交付管道)。所以首先,我们必须创建:
- 用于构建镜像并将其推送到 Docker 注册表的脚本
- 基础设施 Git 存储库
- CI 系统访问基础设施 GIT 存储库的帐户
- 用于生成并推送 HelmRelease 文件的脚本
- 头盔存储库
- CI 系统访问 Helm 存储库的帐户
- 用于构建和发布 Helm 图表的脚本`
- 基础设施存储库的 Flux 帐户
- Helm 图表存储库的 Flux 帐户
太棒了,现在您已经有了 GitOps 的清单。继续前行。
违反单一事实来源概念
让我们看看 Helm 版本总体上会带来什么。很明显,在这种特殊情况下,Git 不可能是唯一的事实来源。我们至少有 2 个资源,2 个 git 之外的工件,这个 Helm 版本依赖于它们:
- Helm 图表(第 8-14 行)
- Docker 镜像(第 19 行)
我们可以使事情变得更加复杂,并指定 Helm 图表版本的范围。
在这种情况下,Flux 将监视并设置在此范围内出现的新 Helm 图表。此外,我们拥有的源控制器可以使用 YAML 作为源,包括 S3 捆绑包。
从那里,我们可以保留 YAML 和 Helm 图表。
此外,我们还有镜像自动化控制器,可以关注 Docker 注册表中的新镜像并编辑基础设施存储库。
但我们不需要 HELM Chart 存储库操作或 Docker 注册表操作。我们希望尽可能成为 GitOps。因此,我们查看文档并更正从 GIT 存储库部署 Helm 图表的流程(我们选择应用程序存储库来存储它)。
这迫使我们为应用程序存储库创建另一个 CR GitRepository,一个供 Flux 访问它的帐户,并使用密钥创建一个秘密。
同时,我们并没有以任何方式解决对Docker镜像的复杂依赖问题。
小结论
我想今天就够了。在第二部分中,我将告诉你这个善良有什么问题。我将讨论:
- 多环境问题
- 值来自
- 秘密问题
- CI Ops 与 GitOps
- 安全
- 回滚过程
- 多集群问题
- 谁真正需要 GitOps?
我希望这篇文章对您有用!
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
標籤
相關故事
数字游民请注意:您需要了解泰国新推出的 DTV 签证
#digital-nomads

加密货币增长:创建有效的用户角色 #crypto-user-experience
Jan 01, 1970

我的三年自由职业之旅:我如何完成 1200 个项目并赚大钱 #freelancing
Jan 01, 1970

