


















visit
Replicate PostgreSQL Databases Using async Python and RabbitMQ for High Availability by@bechir
3,803 reads
Replicate PostgreSQL Databases Using async Python and RabbitMQ for High Availability
by bechirMay 5th, 2022
Too Long; Didn't Read
Triggers are useful for a wide range of cases, like verifying constraints or boosting performance. In our case, we will use triggers to notify our Python listener when data has been removed or added. We define a procedure called `notify_account_changes()` that will handle sending notifications about the changes in the database. We can have many listeners on a channel by executing `LISTEN channel_name. And to send notifications, we use the `NOTIFY` command or the built-in system function `pg_notify('channel_name', 'payload')Company Mentioned
The Importance of Replication
Databases are one of the pillars of any application. If a database server goes down, the whole system will no longer perform its basic services: authenticate users, publish our beloved Hackernoon posts, store comments for the crush’s selfies…
This is why designing the system for High Availability (the ability of a distributed system to operate continuously without failing for a designated period of time) is essential.
Introducing The Solution
First, we have to list out our constraints:- clients should connect to the database directly and have no interaction with our replication system.
- our whole system should be very fast and resource-efficient
How do we know what part of the database tables has been inserted, deleted, or modified?
TRIGGERS! THEY ARE AWESOME !!
Database triggers allow us to execute SQL functions whenever an event is received. An event can be any operation such as INSERT, UPDATE, DELETE or TRUNCATE. Triggers are useful for a wide range of cases, like verifying constraints or boosting performance. In our case, we will use triggers to notify our Python listener when data has been removed or added. We define a procedure called notify_account_changes() that will handle sending notifications about the changes in the database. This is how to define the trigger on the table "users":
CREATE TRIGGER users_changed
AFTER INSERT OR UPDATE
ON users
FOR EACH ROW
EXECUTE PROCEDURE notify_account_changes();
How the heck can we now notify programs outside our server about these changes?
from the PostgreSQL documentation ():
The
NOTIFYcommand sends a notification event together with an optional “payload” string to each client application that has previously executedLISTEN channelfor the specified channel name in the current database.
In other words, we can have many listeners on a channel by executing LISTEN channel_name. And to send notifications, we use the NOTIFY command or the built-in system function pg_notify('channel_name', 'payload'). The payload is a message that we want to send. In our case, the notification payload will include:
- TG_TABLE_NAME: name of the table that launched the trigger.
- TG_OP: the operation that launched the trigger (INSERT, DELETE…).
- NEW: which is a variable given by the TRIGGER so that we know what the new inserted or updated data.
- OLD: which is also a variable given by the TRIGGER so that we know the old values before updating or deleting the record.
Here’s the code for the notify_account_changes()
CREATE OR REPLACE FUNCTION notify_account_changes()
RETURNS trigger AS
$$
BEGIN
PERFORM pg_notify(
'users_changed',
json_build_object(
'table', TG_TABLE_NAME,
'operation', TG_OP,
'new_record', row_to_json(NEW),
'old_record', row_to_json(OLD)
)::text
);
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
Listening to the Notifications from Python
to connect to the PostgreSQL we are going to use the one and only “psycopg2” library. we can install it using:
pip install psycopg2
conn = psycopg2.connect(host="localhost", dbname="DBNAME", user="USERNAME", password="PASSWORD")
conn.set_isolation_level(psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)
cursor = conn.cursor()
cursor.execute("LISTEN users_changed;")
cursor.execute() enables us to execute SQL commands like SELECT or INSERT…
def handle_notify():
conn.poll()
for notify in conn.notifies:
print(notify.payload)
conn.notifies.clear()
loop = uvloop.new_event_loop()
asyncio.set_event_loop(loop)
loop.add_reader(conn, handle_notify)
loop.run_forever()
Here we used asynchronous libraries, uvloop and asyncio. The line loop.add_reader(conn, handle_notify) enables us to invoke the handle_notify() function only when the conn file descriptor (which represents the connection to our database) has an incoming stream of data. After executing INSERT INTO users VALUES (2,'al');
{
"table" : "users",
"operation" : "INSERT",
"new_record" : {
"id":2,
"name":"al"
},
"old_record" : null
}
- PostgreSQL NOTIFY queues are not persistent. If we are not listening, notifications will be lost.
- Having many listeners’ connections can make the database server slower.
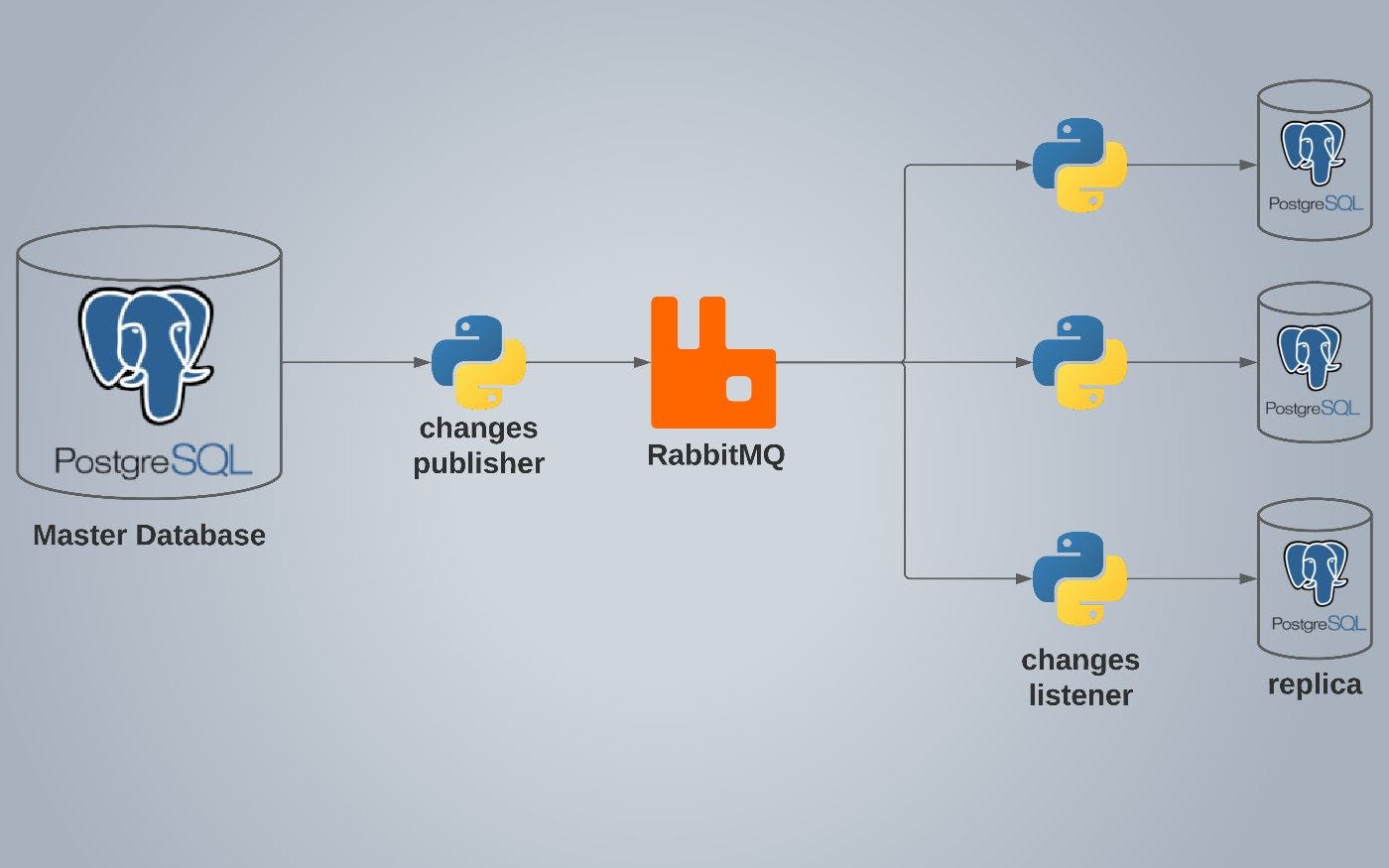
Introducing RabbitMQ
to solve these problems we introduce RabbitMQ.
RabbitMQ is a messaging broker - an intermediary for messaging. It gives your applications a common platform to send and receive messages, and your messages a safe place to live until received.
Each changes_listener python script will have its own queue. to send messages to all queues we will send it to a fanout exchange with the changes_publisherscript. the fanout exchange broadcasts every message to all connected queues.
To use RabbitMQ with python we will use the pika library
pip install pika
In changes_publisher.py we will connect to the RabbitMQ server. Then we will create an exchange named “replication”. For each notification received we will broadcast it to all RabbitMQ queues.
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='replication', exchange_type='fanout')
def handle_notify():
conn.poll()
for notify in conn.notifies:
channel.basic_publish(exchange='replication', routing_key='', body=notify.payload)
conn.notifies.clear()
And in our changes_listener.py
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='replication', exchange_type='fanout')
result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
channel.queue_bind(exchange='replication', queue=queue_name)
def callback(channel, method, properties, body):
op = json.loads(body.decode('utf-8'))
print(op)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
Executing this SQL query UPDATE users SET name='alfonso' WHERE id=2; will result in this output from the changes_listener.py:
{
'table': 'users',
'operation': 'UPDATE',
'new_record': {
'id': 2,
'name': 'alfonso'
},
'old_record': {
'id': 2,
'name': 'al'
}
}
Writing the changes to the replicas
Now that we have received the changes in our python script, all that is left to do is commit these changes. To do this, we will have to change our callback function to generate SQL commands from every received JSON message:def operation_handler(op):
def handle_insert():
table, data = op['table'], op['new_record']
sql = f"""INSERT INTO {table}
VALUES ('{data['id']}','{data['name']}');
"""
return sql
sql = None
if op['operation'] == 'INSERT':
sql = handle_insert()
# we can add other operation handlers here
return sql
def callback(channel, method, properties, body):
op = json.loads(body.decode('utf-8'))
sql = operation_handler(op)
cursor.execute(sql)
In the callback, when we receive the message, we convert it to a dictionary and pass it to operation_handler(op) . This function will look at the message and return the appropriate SQL using its values.
If we check the replica database after executing a simple SQL query INSERT INTO users VALUES (2,'al'); We find this:
Final Notes
Step by step, we have finished implementing our database replication system. We have gone from configuring triggers and notifications in the database to broadcasting the changes using RabbitMQ to finally writing the changes back into a PostgreSQL replica.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES


10 Lessons from 10 Years of AWS (part 1) #aws
Dec 02, 2017

10 Lessons from 10 Years of AWS (part 2) #aws
Jan 12, 2018

111 Stories To Learn About Architecture #architecture
Apr 06, 2023



