

















visit
Routing Analysis Reveals Expert Selection Patterns in Mixtral by@textmodels
Routing Analysis Reveals Expert Selection Patterns in Mixtral
by Writings, Papers and Blogs on Text ModelsOctober 18th, 2024
Too Long; Didn't Read
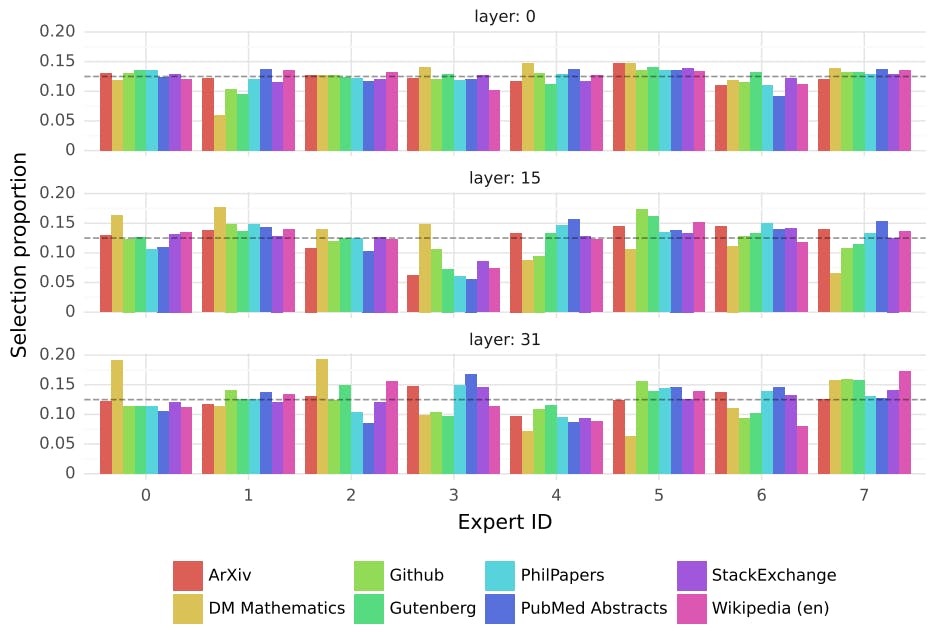
The routing analysis of Mixtral shows no clear expert specialization across different domains, such as mathematics and biology, despite some differences observed in mathematics due to the dataset's synthetic nature. However, structured syntactic behavior is evident, with positional locality affecting expert assignments. This locality may impact model optimization for training and inference, suggesting potential strategies for caching and load balancing.Table of Links
2 Architectural details and 2.1 Sparse Mixture of Experts
3.1 Multilingual benchmarks, 3.2 Long range performance, and 3.3 Bias Benchmarks
6 Conclusion, Acknowledgements, and References
5 Routing analysis
In this section, we perform a small analysis on the expert selection by the router. In particular, we are interested to see if during training some experts specialized to some specific domains (e.g. mathematics, biology, philosophy, etc.).
This paper is under CC 4.0 license.
Authors:
(1) Albert Q. Jiang; (2) Alexandre Sablayrolles; (3) Antoine Roux; (4) Arthur Mensch; (5) Blanche Savary; (6) Chris Bamford; (7) Devendra Singh Chaplot; (8) Diego de las Casas; (9) Emma Bou Hanna; (10) Florian Bressand; (11) Gianna Lengyel; (12) Guillaume Bour; (13) Guillaume Lample; (14) Lélio Renard Lavaud; (15) Lucile Saulnier; (16) Marie-Anne Lachaux; (17) Pierre Stock; (18) Sandeep Subramanian; (19) Sophia Yang; (20) Szymon Antoniak; (21) Teven Le Scao; (22) Théophile Gervet; (23) Thibaut Lavril; (24) Thomas Wang; (25) Timothée Lacroix; (26) William El Sayed.
L O A D I N G
. . . comments & more!
. . . comments & more!







