











































visit
494 reads
The Complete Guide to Building Your Own Web Scraper With NodeJS
by Alex IftodeAugust 22nd, 2021
Too Long; Didn't Read
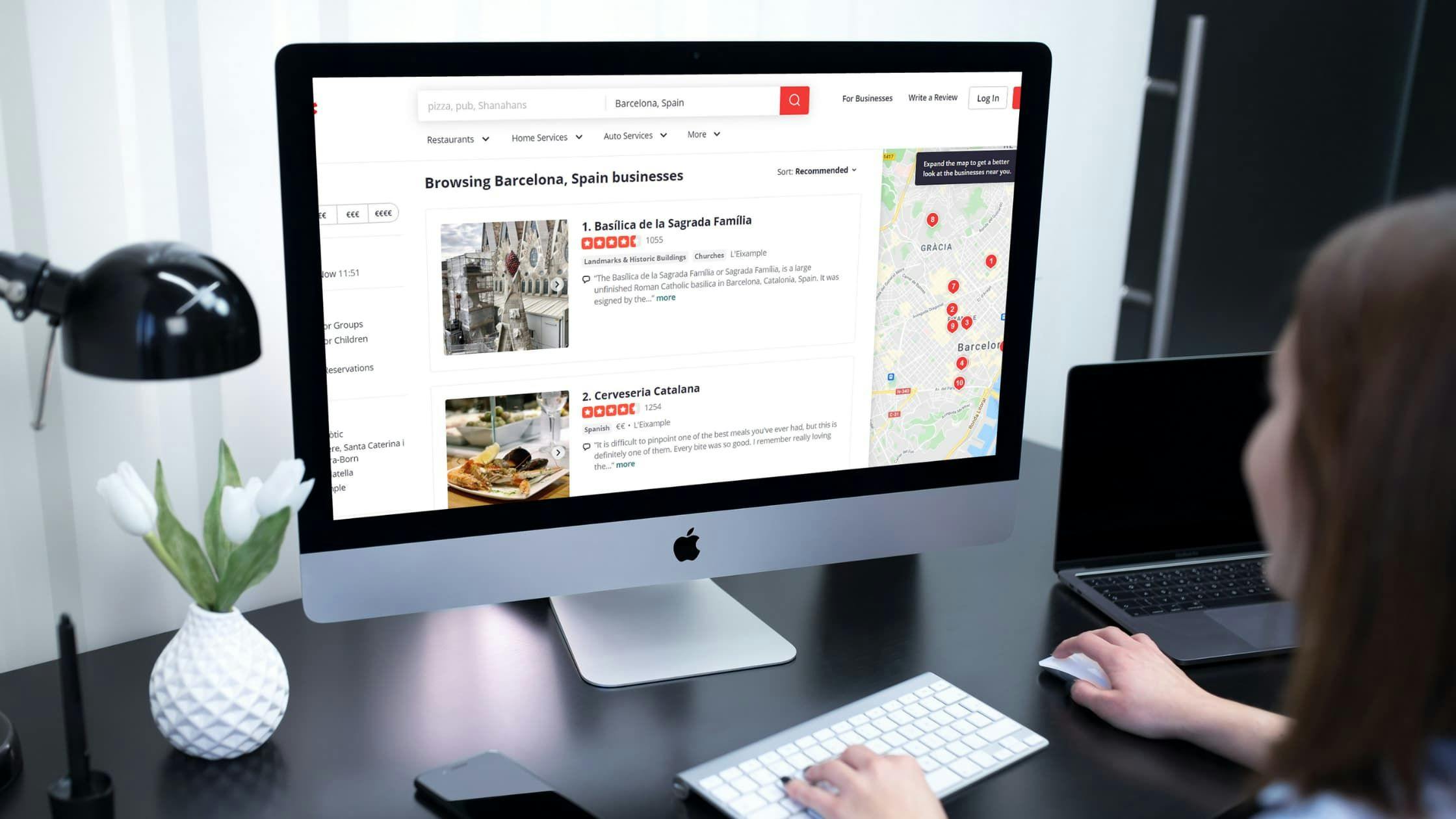
NodeJS is an easy way to create a web scraper in NodeJS. In this guide, we’ll be scraping Yelp, a well-known crowd-sourced website, to gather data on businesses from Barcelona, Spain. We will be using NodeJS as our programming language and WebStorm as our IDE, but you can choose whichever IDE you feel comfortable with. For the sake of simplicity, we will scrape only the first three pages of Yelp. To scrape more pages, we'll create a for loop and modify the ‘start’ parameter from the URL to generate a request for each page.Company Mentioned
As dear as the Internet is to me, I can’t help but feel annoyed whenever I’m researching something and end up with twenty open tabs in Chrome and have to hit copy and paste a million times.
So, instead of falling asleep while gathering data, I decided to make a coding exercise out of it. Specifically, I made a web scraper in NodeJS to do the work for me. Now, I’m going to teach you how to do the same!
Don’t worry if you’re not familiar with web scraping or just starting out with NodeJS. Extracting data with a bot is easier than it sounds, and you can use the code samples in this article to begin.
Picking a website to scrape
Since you need to tailor your web scraper to a particular website structure before actually getting the data, let’s establish what we’ll be scraping. In this guide, we’ll be scraping Yelp, a well-known crowd-sourced website, to gather data on businesses from Barcelona, Spain.
Yelp is a pretty popular site for scrapers since it hosts tonnes of data that could be useful for companies. Just think about how much information on your competitors you can gather from the website. Actually, you don’t even have to think about it. Just follow the guide, and you’ll see.
Gathering the tools
We will be using NodeJS as our programming language and WebStorm as our IDE, but you can choose whichever IDE you feel comfortable with. Now, let’s see what packages we need for the task at hand:
- : To emulate the subset of a web browser for us to scrape web pages.
- : To help us with HTTP requests.
- : To store the data we collect in a more structured format, such as CSV.
Importing the Tools
const {JSDOM} = require('jsdom');
const got = require('got');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
Initializing Storage
We need to store the data somewhere before structuring it later in a more efficient format. For this, we will need an empty list where the information of each business will be saved as an object.
let businesses = []
The URL, The Requests, and The Parsing
So, first and foremost, let’s get the URL. For our example, we’ll use , which leads us to a general business search in Barcelona.
You’ll notice that only ten businesses are displayed per page. To scrape more pages, we will create a for loop and modify the ‘start’ parameter from the URL to generate a request for each page and extract its contents.
const url = '//www.yelp.com/search?find_desc=&find_loc=Barcelona%2C%20Spain&start='
const numberOfPages = 3
for (let pageNumber = 0; pageNumber < numberOfPages; pageNumber++) {
const urlToScrape = url + pageNumber * 10
const res = await got(urlToScrape)
const {document} = new JSDOM(res.body).window
}
Quick explanation
- url: This is the main URL to which we add the number of businesses to be skipped to move between the pages.
- numberOfPages: For the sake of simplicity, we will scrape only the first three pages of Yelp.
- urlToScrape: JavaScript is smart enough to calculate the pageNumber, convert it to a string, and concatenate it with the main URL.
- res: Here is where the HTML result of our HTTP request will be stored.
- document: JSDOM comes to play and parses the HTML for us.
Finding the Right Content
We have successfully collected the contents of each web page, but how do we extract only certain information from it? We need to inspect the page using the Developer’s Inspect Tool from within our browser.
Notice how all the containers we need to extract data from are under the li tag within the main ul list tag. By checking deeper within the nested elements, we can observe that the first two div tags have different class attribute values than the rest and do not present helpful information.
So, we will focus on all the div elements whose class attribute has the value container__09f24__sxa9-.
const elements = document.querySelectorAll('li div.container__09f24__sxa9-')
Quick Explanation
- querySelectorAll is a Document method that returns a static NodeList of all the elements which match the specified group of selectors, in our case, all the div tags with the class attribute container__09f24__sxa9- nested in a li tag.
- elements is the variable we will store all div containers matching the selectors mentioned above.
Extracting Each Item
By looking at the first displayed business, we can extract various information, such as:
- Title
- Rating
- Price range
- Number of reviews
- Tags
- Area
- Description
Comparing the two, we can see that the number of tags can differ (the first business has two tags and the second one has only one), and some information can be missing (such as the price range, which tells how expensive the place is).
When building a web scraper, always consider that you may not find all the information you want to gather within each section. Here, for example, the price range doesn’t show up for the first business container above.
Missing data can be harmful and stop the web scraping process, so handling such cases is crucial.
Another Loop
Now that we have an array with the div elements containing the information of each business, we must iterate through them and collect the data we mentioned earlier. To do that, we will use the forEach method and declare an empty object to be filled with all the juicy information in each loop.
elements.forEach((element) => {
let element_obj = {}
})
Quick Explanation
- forEach is a method used to iterate through an array.
- element is the name of the variable which enters the loop. Its name isn’t relevant. You can name it as you like, but keep it, so people know what you are coding about.
- element_obj is an empty object ready to be filled with all the juicy information of businesses.
Now that everything is ready, let’s start scraping! We still need to use the Inspect Tool, by the way!
Extracting The Title
Using the Developer’s Inspect Tool, we will click on the title of the first business and see in which tag the text is located.
Notice the text representing the title of the business element is nested in an anchor tag, <a>, which has the value of the class attribute equal to css-166la90. To see if this identification method is unique, so we don’t get information about something other than this business title, we can quickly search inside the inspect tool by pressing Ctrl+F and typing the class name, in this case, css-166la90.
const title = element.querySelector('a.css-166la90')
if (title && title.textContent)
element_obj.title = title.textContent
Quick Explanation
- title is the variable in which we will store the extracted information.
- querySelector is a method similar to querySelectorAll, just that it will return the first Node which matches the specified group of selectors.
- a.css-166la90 is the selector we are searching for: an anchor tag with the class css-166la90.
- textContent is the property that holds the information about the title.
- As we mentioned before, it is vital for the data to exist before adding it to our result, so checking if the element exists and if it has the textContent property is a must.
- If the statement is true, the title information is then added to the title property of the element object.
Extracting The Link
This task is relatively easy because the anchor tag we scraped for earlier also has a href attribute containing the link to the business page!
const link = title.getAttribute('href')
if (link)
element_obj.link = '//www.yelp.com' + link
Quick Explanation
- link is the variable in which we will store the extracted information.
- getAttribute is a method that extracts the value of a given attribute.
- href is the attribute where the redirection link of the business page is located.
- Just like in the previous extraction, we must first verify its existence, and if it does exist, we add it to the link property of the element object.
Extracting The Rating
Doing the same trick using the Inspect Tool, we can see that the data regarding the number of stars of said business is located in the aria-label attribute of a <div> tag.
By checking its class name, i-stars--regular-4-half__09f24__3Qo_8, we observe that it differs for each business regarding the number of stars, so using this within a query won’t cut it. Notice that there is yet another attribute called role, which has the value “img”. Using this to extract the information seems like a better solution. Let’s try it out!
const rating = element.querySelector('div[role="img"]')
if (rating) {
let stars = rating.getAttribute('aria-label')
if (stars) element_obj.rating = stars
}
Quick Explanation
- rating is the variable in which we will store the extracted information.
- querySelector will return the first node that matches the specified group of selectors, in this case, the <div> tag, which has an attribute called role having the value “img”.
- getAttribute is a method that extracts the value of a given attribute.
- stars is the variable that holds the information scraped from the aria-label attribute.
- Just like in the previous extraction, we must first verify its existence, and if it does, we add it to the rating property of the element object.
Extracting The Number of Reviews
This task is pretty simple, as we just need to follow the same steps. We discover that the number of reviews is in a <span> tag with the class name reviewCount__09f24__3GsGY.
const reviews = element.querySelector('span.reviewCount__09f24__3GsGY')
if (reviews && reviews.textContent)
element_obj.reviews = reviews.textContent
Quick Explanation
- reviews is the variable in which we will store the extracted information.
- querySelector returns the first Node which matches the specified group of selectors.
- textContent is the property that holds the information about the tag.
Extracting The Tags
To extract the tags, we must again use the inspect tool to find the information within the HTML.
Notice that the text we are looking for is within a <p> tag, which is located inside a <button>. The <button> tag is then nested in an anchor tag <a> which is also nested inside a <span> tag having the class value css-epvm6.
const tags = element.querySelectorAll('span.css-epvm6 a button p')
if (tags.length > 0) {
element_obj.tags = ''
tags.forEach((tag => {
if (tag.textContent)
element_obj.tags += tag.textContent + ';'
}))
}
Quick Explanation
- tags is the variable in which we will store the extracted information.
- querySelectorAll returns a static NodeList of all the elements which match the specified group of selectors.
- textContent is the property that holds the information about the tag.
- We iterate through all the tags and add them to the element object tags property separated by “;”. We don’t append them as a separate array because it will be more complicated to format the data into a CSV later on.
Extracting The Price Range
The Inspect Tool tells us that this information can be located under a <span> tag having the class name priceRange__09f24__2GspP.
We also talked about the fact that the price range could be missing. In this case, we must add a default value, let’s say “-”.
const priceRange = element.querySelector('span.priceRange__09f24__2GspP')
if (priceRange && priceRange.textContent)
element_obj.priceRange = priceRange.textContent
else element_obj.priceRange = '-'
Quick Explanation
- priceRange is the variable in which we will store the extracted information.
- querySelector returns the first Node which matches the specified group of selectors.
- textContent is the property that holds the information about the price range.
- If by any chance the price range information cannot be found within the HTML, the element object priceRange property will be set to -.
Extracting The Area
With all this Inspecting, I think we got the hang of it! Now, by searching for the area, we notice that the information we need is located under a <span> tag with the class name css-e81eai and the problem is that other elements use the same class as well. To solve this, we will need the help of the parent nodes as well.
Taking a step back, we can see that the <span> tag is nested inside a <p> tag with the class name css-1j7sdmt. Let’s use this group of selectors to extract our data!
const area = element.querySelector('p.css-1j7sdmt span.css-e81eai')
if (area && area.textContent)
element_obj.area = area.textContent
Quick Explanation
- area is the variable in which we will store the extracted information.
- querySelector returns the first Node which matches the specified group of selectors.
- textContent is the property which holds the information about the area.
- If it exists, we add it to the area property of the element object.
Extracting The Description
History repeats itself because as we inspect to find the description’s location, we come across a tag with the same name class as before, css-e81eai. Using the parent node in our group of selectors will do the trick yet again!
Looking at the HTML, our data is located in the <p> tag having the class css-e81eai which is also nested in a <div> tag having the class snippetTag__09f24__2G8wN.
const description = element.querySelector('div.snippetTag__09f24__2G8wN p.css-e81eai')
if (description && description.textContent)
element_obj.description = description.textContent
Quick Explanation
- description is the variable in which we will store the extracted information.
- querySelector returns the first Node which matches the specified group of selectors.
- textContent is the property which holds the information about the description.
- If it exists, we add it to the area property of the element object.
Adding The Object To Business Array
We successfully extracted all the data we needed from each business and added them to our element object. It’s time to push the object into our businesses array, but only if it’s not empty. Having empty spaces hanging around is a bad practice, so make sure to always tidy your results!
if (Object.values(element_obj).length > 0)
businesses.push(element_obj)
The Journey So Far
Now, if we wrap everything up in an async function, our code should look like this!
const {JSDOM} = require('jsdom');
const got = require('got');
const createCsvWriter = require('csv-writer').createObjectCsvWriter;
(async () => {
let businesses = []
const url = '//www.yelp.com/search?find_desc=&find_loc=Barcelona%2C%20Spain&start='
const numberOfPages = 3
for (let pageNumber = 0; pageNumber < numberOfPages; pageNumber++) {
const urlToScrape = url + pageNumber * 10
const res = await got(urlToScrape)
const {document} = new JSDOM(res.body).window
const elements = document.querySelectorAll('li div.container__09f24__sxa9-')
elements.forEach((element) => {
let element_obj = {}
const title = element.querySelector('a.css-166la90')
if (title && title.textContent)
element_obj.title = title.textContent
const link = title.getAttribute('href')
if (link)
element_obj.link = '//www.yelp.com' + link
const rating = element.querySelector('div[role="img"]')
if (rating) {
let stars = rating.getAttribute('aria-label')
if (stars) element_obj.rating = stars
}
const reviews = element.querySelector('span.reviewCount__09f24__3GsGY')
if (reviews && reviews.textContent)
element_obj.reviews = reviews.textContent
const tags = element.querySelectorAll('span.css-epvm6 a button p')
if (tags.length > 0) {
element_obj.tags = ''
tags.forEach((tag => {
if (tag.textContent)
element_obj.tags += tag.textContent + ';'
}))
}
const priceRange = element.querySelector('span.priceRange__09f24__2GspP')
if (priceRange && priceRange.textContent)
element_obj.priceRange = priceRange.textContent
else element_obj.priceRange = '-'
const area = element.querySelector('p.css-1j7sdmt span.css-e81eai')
if (area && area.textContent)
element_obj.area = area.textContent
const description = element.querySelector('.snippetTag__09f24__2G8wN p.css-e81eai')
if (description && description.textContent)
element_obj.description = description.textContent
if (Object.values(element_obj).length)
businesses.push(element_obj)
})
}
})();
Printing It
Using a simple console.log will print out our results in the terminal. Let’s see if the scraper did its job correctly.
Cleaning The Data
It’s essential to ensure that the data you are scraping arrives correctly and eliminate the unnecessary information efficiently. This can speed up the data analysis process and make the information more readable. A good example of this is how we structured our tags to be separated by “;”.
Another example would be that the rating property should only tell us about the number of stars. We can easily remove the “star rating” text from the result by using the replace method and a regular expression.
By adding a simple line of code, our rating extraction code segment should look like this:
const rating = element.querySelector('div[role="img"]')
if (rating) {
let stars = rating.getAttribute('aria-label')
stars = stars.replace(/[^\d+.]/g,'')
if (stars) element_obj.rating = stars
}
Saving The Data Into a CSV
If you want to save your data for later use, storing it in CSV format is a good approach. Outside of our first loop, we will add this code segment to create our CSV file containing all the information we extracted from Yelp.
const csvWriter = createCsvWriter({
path: 'businesses.csv',
header: [
{id: 'title', title: 'Title'},
{id: 'rating', title: 'Rating'},
{id: 'reviews', title: 'Number of Reviews'},
{id: 'tags', title: 'Tags'},
{id: 'priceRange', title: 'Price Range'},
{id: 'area', title: 'Area'},
{id: 'description', title: 'Description'}
]
})
csvWriter.writeRecords(businesses).then(() => console.log('Success!!'))
Quick Explanation
- createCsvWriter (createObjectCsvWriter) is a constructor from the csv-writer package that will create a CSV writer for us to use. To initialize it, we need to give it a place to stay, which is the created file’s location and a table template.
- The path property will specify the location and name of the file.
- The header property holds an array of objects. These objects represent the table’s columns: the id represents the property it links to from our array of business objects, while the title property refers to the title of each table's column.
- The writeRecords method takes the array of businesses we created while scraping and creates the CSV file.
- Just so we know when the mission is complete, let’s add a “Success!!” message at the end.
The CSV
After successfully creating and populating the CSV file, it should look something like this:
Ta-da! That’s all there is to it. Once you understand the concepts, it’s easy to adapt the code to just about any website.
More Learning Materials
If you’d rather build the scraper in a different programming language, that’s fine. There are plenty to choose from and some really good guides out there:
Also, if you just want fast data without writing too much code, you still have options. Here’s an article on that you might like!
L O A D I N G
. . . comments & more!
. . . comments & more!







