


















visit
1,240 reads
Weaviate Is A Search Engine For Vector Embeddings
by SeMI TechnologiesMay 11th, 2020
Too Long; Didn't Read
Weaviate is a vector search engine with a graph-like data model which also allows for higher-level Machine-Learning applications, such as classifications. Vector searches also work with music, images, video clips, voice recordings and many more. The most primitive approach is split this string at each space and look up the vector position for each word in the Contextionary. For example in the vector space, the term “Apple iPhone” is much closer to ‘smartphone” than it is to “hospital supplies”People Mentioned
Companies Mentioned
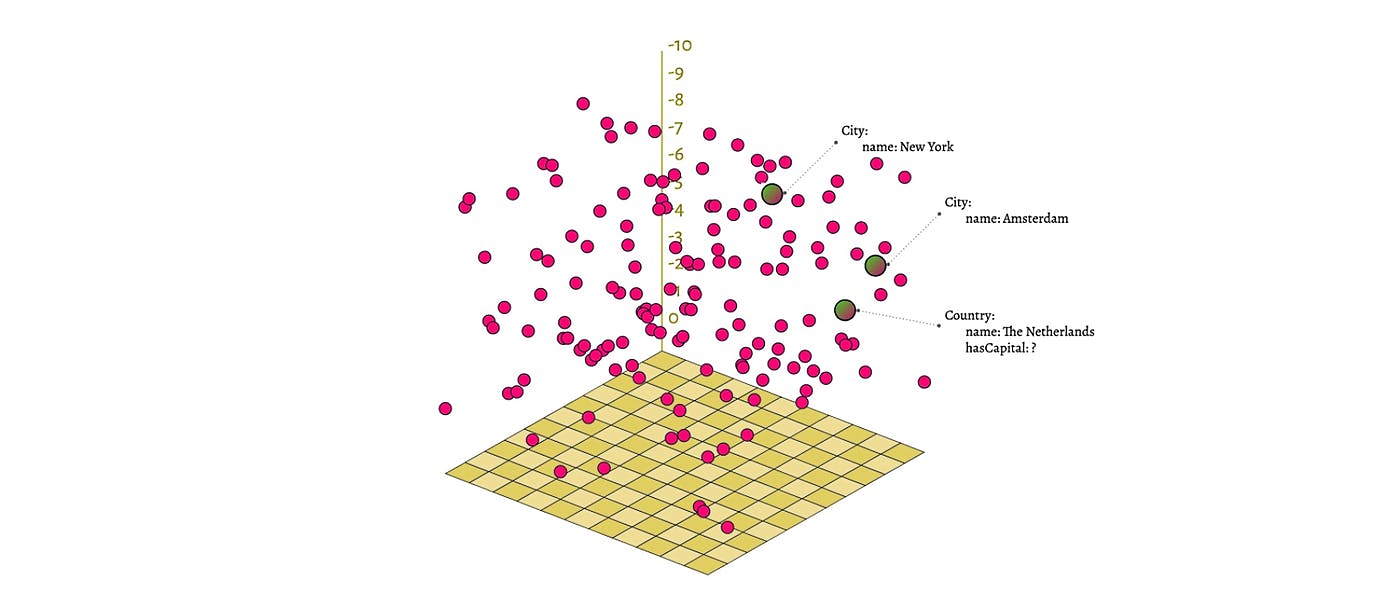
A vector search for the masses needs an intuitive interface
Vector-Searching enables a large spectrum of use cases which are impossible with traditional full-text search engines. A pure full-text search tries to match occurrences of terms in a set of documents. At the most, simple distances - such as Levenshtein distances between words - can be computed.
on the other hand - a vector search engine - ranks each object by how close it is to another. As a vector searches, Weaviate isn’t limited to text objects. Vector searches also work with music, images, video clips, voice recordings and many more. For simplicity in this article we’re looking at vectors representing text objects. For example in the vector space, the term “Apple iPhone” is much closer to “smartphone” than it is to “hospital supplies”.
One of the challenges around vector searching is that data is often not present in vectors, but rather in text form. is a vector search engine with a graph-like data model which also allows for higher-level Machine-Learning applications, such as classifications. At the same time, Weaviate’s interface is easy to use and does not require any specific Machine Learning experience from the user.
High abstraction of underlying ML system for ease of use
Weaviate’s user interface allows for insertion of “regular” text-based objects with a predefined schema. In addition to text properties, Weaviate also supports numerical fields, as well as special fields, such as phone numbers or geo coordinates. Additionally, because Weaviate has a graph-like data model, cross-references between data objects can be created.
However, the part where vectors are created from those ordinary data objects is under the hood. On each import Weaviate builds a vector representation of an object, so it can assign a position in the multidimensional space to the object. This way “the company Apple Inc.” will be stored in close proximity to “the iPhone”, without the user explicitly making this connection between the two data items.
Vector creation at real time thanks to the Contextionary
A common association with machine learning models is a long training time. A goal in developing Weaviate, however, has been that it should not feel any different from using a traditional search engine. As a consequence, a long training period to create vectors after data input was never a possibility for us. Imported data objects must become available and searchable in real time or near real time.
To achieve real-time vector creation, Weaviate makes use of a tool called the “Contextionary”. The Contextionary is a pre-trained vector-space which contains vectors for nearly all words used in a specific language. Thus, the Contextionary is language-specific, but we are also evaluating cross-language support for future releases.
When a text object is imported, the Contextionary acts as a lookup tool to find the new and unique vector position of an object. For example let’s vectorize the following text object in real-time: “I am looking to buy a new smartphone, maybe an iPhone or an Android device”. The most primitive approach is split this string at each space and look up the vector position for each word in the Contextionary. The individual vectors can then be combined to form a new vector:
// takes an array of vectors and outputs a single mean vector
function meanVector(inputVectors) {
// sum up each dimension in a single “sum” vector
sums = new Array(dimensions(inputVectors))
for i = 0; i < dimensions(inputVectors); i ++ {
for j = 0; j < inputVectors.length(); j ++ {
sums[i] += inputVectors[j][i]
}
}
// divide sum by amount of vectors to get mean value
// for each dimension
return sums.map(sum => sum/inputVectors.length())
}
inputParts = input.splitOnNonAlphaNumericCharacters()
vectors = inputParts.map(word => getVectorForWord(word))
combinedVector = meanVector(vectors)However, if each term was weighed equally this vector position would skew a lot into the “noise center”. The noise center is where stop and filler words, such as “I”, “am”, “looking”, etc. reside in the vector space. A traditional search engine would apply methods such as to determine how meaningful a word is - the Contextionary allows for something similar.
When vectorizing we’re not only interested in how unique individual terms are in relation to other documents, but also in relation to the pre-trained language model. Our goal is to place the above text snippet close to areas such as “technology”, “phone”, etc - even if no data objects in this category exist yet. So, to work out which terms are relevant we don’t just look at their relevance in relation to other objects, but also to the vector space itself. In more simpler terms this means that very common words in the training set for the Contextionary, such as “I, “am”, “looking”, etc. will always be assigned a lower weight in classification. Rarer terms, such as “smartphone” will receive a higher weight.
As a result, each term influences the final position to a different degree, instead of just building the mean position we build the weighted mean. The two most influential terms in the above snippet are “iPhone” and “Android”, but the word “buy” also conveyed some meaning - i.e. the intention to purchase something. Therefore the final position of this dataobject will be close in the vector space to concepts such as “smartphone” and “technology”, but also moved slightly towards “buying” or “shopping”. Since the vector-space is a multi-dimensional space it is possible to move along multiple axes at the same time.
Imagine a very simplified vector space that has only two dimensions: The x-axis represents “smartphone” on one end and “groceries” on the other. The y-axis represents “shopping” on one one and “dining” on the other. It is thus possible to move the object close to “shopping” on the y-axis without altering the position on the x-axis which should clearly be in the corner which represents “smartphone”. The Contextionary space can have upwards of 300 or 600 dimensions, thus allowing for a lot of context to be added to a single term.
By using the Contextionary as a look-up tool to vectorize a previously unseen data object, Weaviate is able to determine a meaningful vector position in real-time without retraining the underlying machine-learning model.
Where does the vector come from at query time?
An intuitive interface for importing is only half the battle, at query time we also need a vector position to compare to the targets. Luckily the mechanism that we have used to vectorize an object at import time can be used to vectorize the search query in the same manner. Let’s assume the user searches for “smartphone” in expectation to find the data object we imported previously. Note that the term “smartphone” was never present in the original object, so a pure full-text search would fail at this point and not deliver any results.
In Weaviate, however, we can vectorize the search term by looking up the individual words in the Contextionary. Once we have obtained a meaningful vector position of the query, we can do a simple distance comparison, such as cosine similarity, between the source and target objects. If there is no data object, which is even closer to the term “smartphone” than the one we imported previously, our example object will be returned at position one.
Extending the Contextionary
The Contextionary is trained on common knowledge sources, such as Wikipedia, Wiktionary, as well as website texts available through the . This provides it with a large set of words which are sufficient to cover most cases.
However, you might be using very industry-specific terms to convey the most important meaning in a text corpus. Then the Contextionary has simply never learned these in the pre-training phase. To overcome this, the Contextionary can be extended - in real time without retraining - in a similar fashion to how new data objects are vectorized. As an example let’s look at a new fictional smartphone, the “classicphone” produced by “ACME Inc.” which the Contextionary is not yet aware of. Rather than waiting for a new release after the existence of the “classicphone” has become common knowledge, we can extend the current Contextionary with this industry-specific term. To do so, we can describe it with words that are already present in the Contextionary. This process is similar to how a person would explain a previously unknown concept to another person - using words they already know. So for example an explanation of the “classicphone” could be “A smartphone by ACME inc with a large library of classical music tracks”. Similarly, we can use this explanation to extend the Contextionary:
curl $WEAVIATE_ORIGIN/v1/c11y/extensions \
-H 'Content-Type: application/json' -d '{
"concept": "classicphone",
"definition": "smartphone by ACME Inc. with classical music",
"weight": 1
}'From now on, each data object containing the term “classicphone” will be moved towards this newly created concept during its vectorization phase.
HNSW for ultra-large scale vector searches
At SeMI, we are convinced that vector-searches will play an even bigger role in the future. We are currently looking into the latest findings of academia, such as - commonly referred to as HNSW graphs - and Random Projection Forests to equip Weaviate for ultra-large scale vector search cases. In the meantime, check out Weaviate on and our .
By - Co-Founder & CTO at
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES




$JTC Network To List On BitMart Exchange #web3
Jan 09, 2024



