




















visit
What the Heck Is Malloy? by@progrockrec
3,428 reads
What the Heck Is Malloy?
by Shawn GordonOctober 7th, 2022
Too Long; Didn't Read
Malloy is an experimental language for describing data relationships and transformations. It is both a semantic modeling language and a querying language that runs queries against a database. Malloy natively supports DuckDB, BigQuery and Postgres, and it can connect to DuckDB. There is a Visual Studio Code extension for Malloy, as well as npm modules for javascript and typescript, in addition to a Composer. The language is more evolved and open-source than Looker, which Google bought back in 2019.Companies Mentioned
I follow some very bright people on Linkedin and Twitter (about the only reason I’m on Twitter), and I learn about interesting tech and interesting use cases by random chance.
The latest is
“Malloy is an experimental language for describing data relationships and transformations. It is both a semantic modeling language and a querying language that runs queries against a relational database. Malloy currently connects to BigQuery and Postgres, and natively supports DuckDB. We've built a Visual Studio Code extension to facilitate building Malloy data models, querying and transforming data, and creating simple visualizations and dashboards.”
Malloy was developed by
"feels like JSON made a baby with SQL, in the worse possible way"
To be clear, I know about Looker, but I haven’t done any real work with it. So that brings us to Malloy.
What Is Malloy?
Lloyd describes Malloy on the
“an experimental language for describing data relationships and transformations. It is both a semantic modeling language and a querying language that runs queries against a relational database.” also stating: “SQL is complete but ugly…Everything is expressible, but nothing is reusable; simple ideas are complex to express; the language is verbose and lacks smart defaults. Malloy is immediately understandable by SQL users, and far easier to use and learn.”
Malloy natively supports
- Queries compile to SQL, optimized for your database.
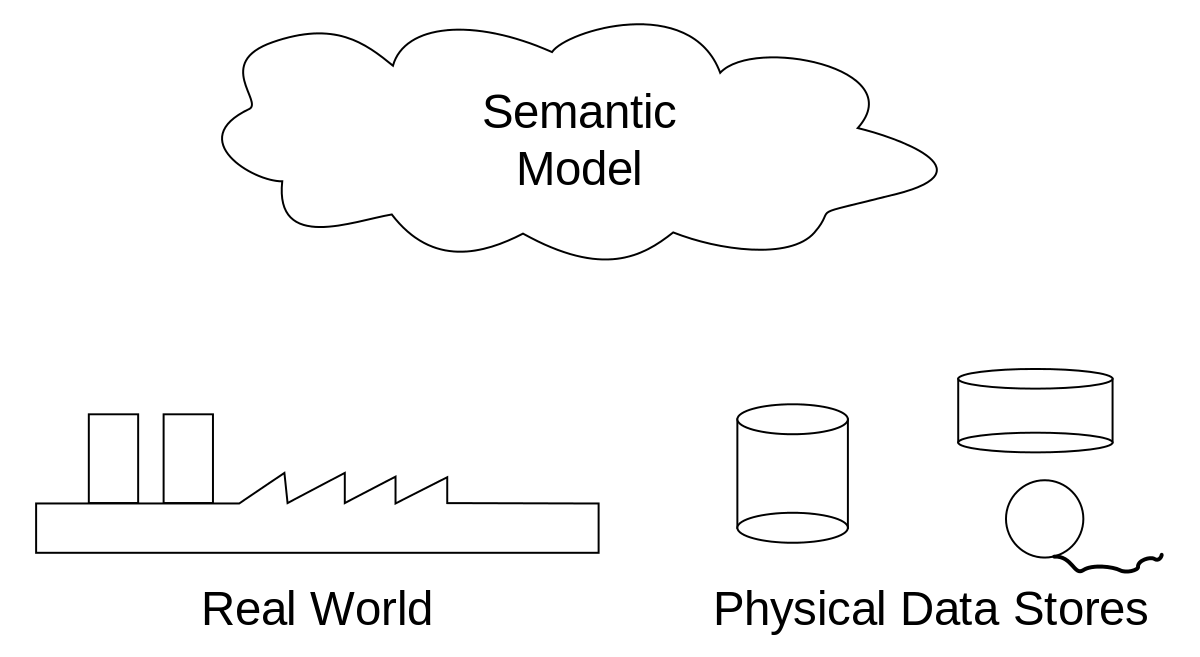
- Has both a semantic data model and a query language. The semantic model contains reusable calculations and definitions, making queries short and readable.
- Excels at reading and writing nested data sets.
- Things that are complicated in SQL are simple to express in Malloy. For example, level of detail calculations, percent of the total, aggregating against multiple tables across a join safely, date operations, reasonable ordering by default, and more.
query: table('malloy-data.faa.airports') -> {
group_by: fac_type
aggregate: airport_count is count()
where: state = 'CA'
order_by: airport_count desc
}
SELECT
base.fac_type as fac_type,
COUNT( 1) as airport_count
FROM `malloy-data.faa.airports` as base
WHERE base.state='CA'
GROUP BY 1
ORDER BY 2 desc
Note that you can display this as HTML, JSON, or SQL. The basic structure of a Malloy Query takes the form of:
query: <source> {
join_one: <source> with …
join_many: <source> on …
} -> {
group_by:
<field/dimension>
<field/dimension>
aggregate:
<aggregation/measure>
<aggregation/measure>
nest:
<named_query OR query_def>
<named_query OR query_def>
where: <filter_expression>, <filter_expression>, …
having: <aggregate_filter_expression>, <aggregate_filter_expression>
order_by: <field/dimension>, <aggregation/measure>, …
limit: <limit>
}
SELECT
<group_by>, <group_by>, …
<aggregate>, <aggregate>, …
<nest>, <nest>, … -- very much a simplification; read more in Nesting Queries doc.
FROM <source>
LEFT JOIN <source> ON …
LEFT JOIN <source> ON …
WHERE (<filter_expression>) AND (<filter_expression>) AND …
GROUP BY <group_by>, <group_by>, …
HAVING <aggregate_filter_expression> AND <aggregate_filter_expression> AND …
ORDER BY <group_by> | <aggregate>
LIMIT <limit>
If you don’t know Mimoune Djouallah, you should definitely follow him on
So, I’m going to summarize what Mimoune has going on here on his
In the left-hand pane, we have the schema information, which is pretty obvious. Then to the right of that on top is our Malloy Query, in which you can see the nested aggregations easily described in just a few lines.
That is the generated SQL from the Malloy Query, which was only 6 actual lines of code; it replaced 40 lines of SQL. You can see the embedded DuckDB connection that is accessing the various Parquet files that have the data for the query in the Semantic Model.
It’s totally worth clicking into the Fiddle and playing around a bit. There is another really fun Fiddle from Lloyd that connects to the IMDB dataset that is absolutely worth checking out
Summary
The main purpose of this article is to bring Malloy and some ideas to your mind; it’s not meant to be an exhaustive tutorial by any means. Yes, it’s another language, but it’s similar enough that it should be easy to pick up on.
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES


BigData Behind Blockchain Forensics #bitcoin
Mar 06, 2019




125 Stories To Learn How To Do X #how-to
May 06, 2023

