

















visit
Why Can’t AI Count Letters??? by@dhanushnehru
234 reads
Why Can’t AI Count Letters???
by Dhanush NehruOctober 10th, 2024
Too Long; Didn't Read
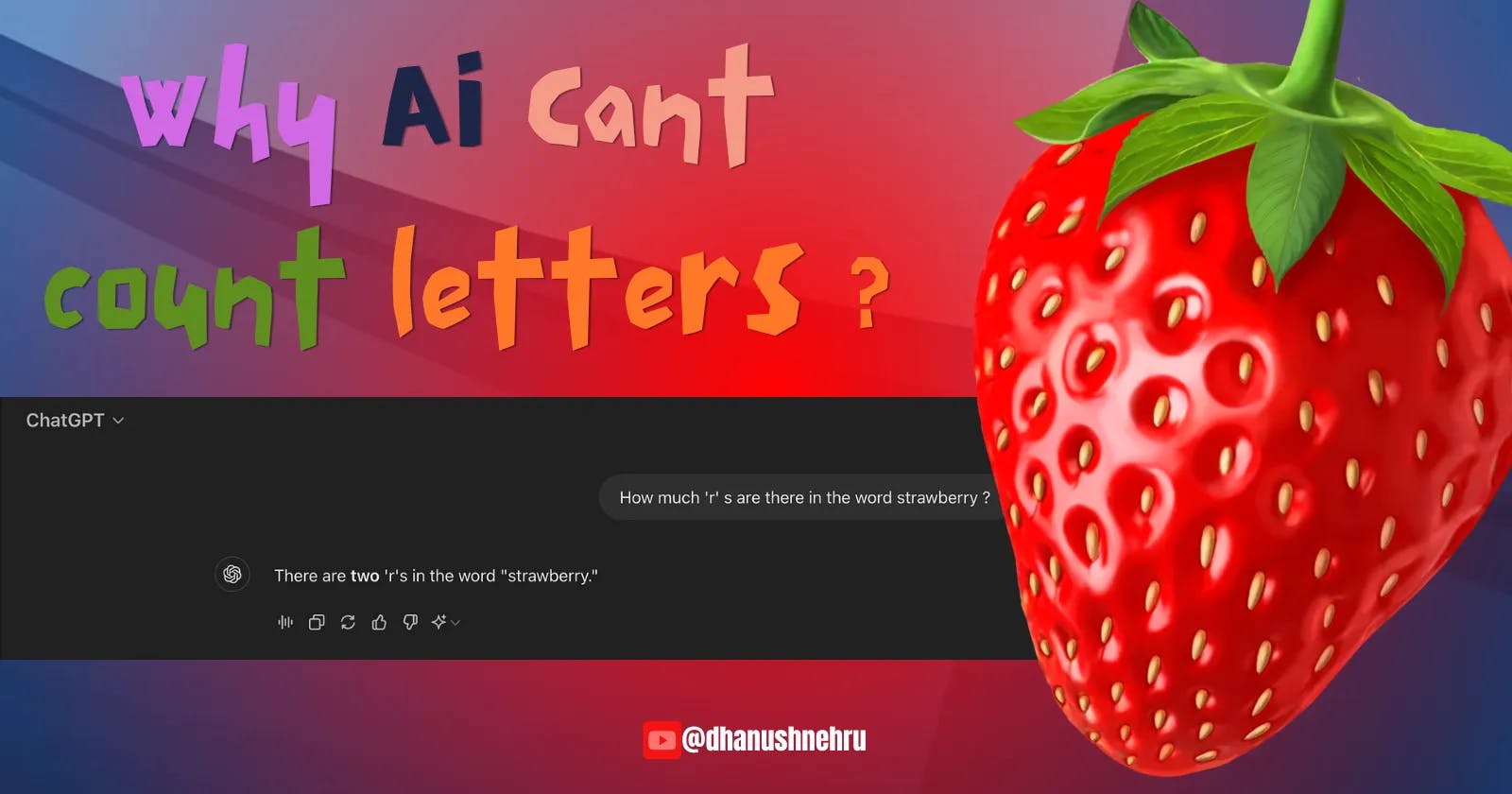
The most annoying weirdness that has recently circulated on social media is this enormous language model’s inability to correctly count the number of letters in a word. A common example is the word “strawberry,” in which artificial intelligence frequently fails to correctly count the number of times the letter “r” appears. But why is it doing this?Large language models, particularly OpenAI’s ChatGPT, transformed how we interacted with robots that understood and produced human-like words. However, each of these models had their own eccentric personality. The most annoying weirdness that has recently circulated on social media is this enormous language model’s inability to correctly count the number of letters in a word.
The Tokenization Process
One of the primary reasons AI struggles with tasks such as letter counting is due to the way it processes language. Language models like GPT-3 and GPT-4 do not treat words as a collection of individual letters. Instead, they divide the text into smaller components called “tokens.” Tokens can be as short as one character or as lengthy as a full word, depending on the model’s design and the specific word involved.
Prediction Mechanism of Language Models
Language models anticipate the next word or token in a sequence based on the context provided by the preceding words or tokens. This is especially useful for creating a language that is both coherent and aware of its surroundings. However, it is not particularly useful for tasks that require exact counting or reasoning about individual characters.
The limitation of Models in Pure Language
It’s also crucial to remember that language models, which are the basis for the majority of chatbots, are not suitable for explicit arithmetic or counting. To put it another way, pure language models are essentially sophisticated dictionaries or predictive text algorithms that do tasks that are probabilistic weighted depending on the patterns they identify, but they are not very good at activities like counting that call for rigorous logical reasoning.
Changes and Enhancements
Despite these drawbacks, AI performance on these tasks could yet be improved. You can make them better by asking the AI to perform the counting using various programming languages, including Python.
You could, for instance, attempt to direct the AI to construct a Python function that counts the “r”s in the word “strawberry,” and it most likely would succeed.
Language Models Nature and “Collective Stupidity” 😅
The difficulty of counting letters in words, such as “strawberry,” is indicative of a broader and more widespread problem in this context: the “collective stupidity” of these trained models. These models may generate text at a highly sophisticated level because of their training on big datasets, yet occasionally, they will make incredibly silly mistakes that a small child might easily avoid.
Conclusion: The Development of Knowledge About AI
The fact that AI is unable to count the “r”s in a “strawberry” is not a minor error, but rather an indication of the language models’ fundamental architecture and design philosophies. These models are incredibly effective at producing text that seems human, comprehending context, and simulating dialogue, but they are not designed for tasks that call for precise character-level detail.
Thanks for reading, please give a like as a sort of encouragement and also share this post on socials to show your extended support.
Follow for more ⏬
L O A D I N G
. . . comments & more!
. . . comments & more!






