











































visit
Why Implementing Microservices on AWS Is Indispensable to a Modern Architecture for Business Agility by@priya11
3,428 reads
Why Implementing Microservices on AWS Is Indispensable to a Modern Architecture for Business Agility
by Priya KumariJanuary 21st, 2022
Too Long; Didn't Read
AWS customers build microservices on 3 common patterns: API-driven, event-driven, & data streaming. The blog covers the common characterics of microservices.Companies Mentioned
Coins Mentioned
Microservices are an architectural and organizational approach to
Besides scaling up the development cycles, microservices also foster innovation and ownership and assist in improving the maintainability and scalability of software applications to help organizations scale their delivering software and services by means of an agile approach. Software is composed of small services that commute over well-defined application programming interfaces (APIs) that can be independently deployed. These services are often owned by small autonomous teams. The
When AWS customers build microservices three common patterns have been observed: API-driven, event-driven, and data streaming. The blog covers these three approaches and summarizes the common characteristics of microservices. I have also discussed, the main challenges of building microservices, and described how product teams can deploy AWS to overcome these challenges.
Characteristics of Microservices
a) Autonomous – Each of the component services in a microservices architecture can be developed, deployed, operated, and scaled without affecting the functioning of other services. Services aren’t required to share any of their code or implementation with other services. Any communication between individual components happens via well-defined APIs.
b) Specialized – Each service is designed for a set of capabilities and focuses on solving specific problems. If developers contribute more code to service over time and the service becomes complex, it can be broken into smaller services.
Monolithic versus Microservices Architecture
With monolithic architectures, all processes are tightly coupled and run as a single service. This means that if a process of the application experiences a spike in demand, the entire architecture can be scaled. Adding or improving a monolithic application feature becomes more complex as the code base grows. This complexity limits experimentation, making it difficult to implement new ideas. Monolithic architectures add risk for application availability because many dependent and tightly coupled processes increase the impact of a single process failure.
With a microservices architecture, an application is designed with independent components that run each application process as a service. These services communicate via a well-defined interface using lightweight APIs. Services might be built for business capabilities and each service performs a single function. This happens because these services are independently run, can be updated, deployed, and scaled to meet the demand for specific functions of an application.
Talking of the conventional monolithic applications, these usually have three different layers – a user interface (UI) layer, a business layer, and a persistence layer. A central idea of a microservices architecture is to split functionalities into cohesive verticals – not by technological layers, but by implementing a specific domain. The following figure depicts the architecture for a typical microservices application on AWS.
Benefits of Microservices
The following are some major benefits of working with a microservices architecture:
- Agility
Microservices foster an organization of small, independent teams that take ownership of their services. Teams act within a small and well-understood context and are empowered to work more independently and more quickly. This shortens development cycles. The companies can benefit significantly from the aggregate throughput of the organization.
- Flexible Scaling
Microservices allow each service to be independently scaled to meet the demands for the application feature it supports. This enables teams to right-size infrastructure needs, accurately measure the cost of a feature, and maintain availability if a service experiences a spike in demand.
- Easy Deployment
Microservices enable continuous integration and continuous delivery, simplifying the process of trying out new ideas to roll back if something doesn’t work. The low cost of failure enables experimentation and makes it easier to update code, and accelerates time-to-market for new features.
- Technological Freedom
Microservices architecture doesn't follow a "one size fits all" approach. Teams have the freedom to choose the best tool to solve their specific problems. As a consequence, teams building microservices can choose the best tool for each job.
- Reusable Code
Dividing software into small, well-defined modules enables teams to use functions for multiple purposes. A service written for a certain function can be used as a building block for another feature. This allows an application to bootstrap off itself, as developers can create new capabilities without writing code from the scratch.
- Resilience
Service independence optimizes the applications’ resistance to failure. In a monolithic architecture, if a single component fails, it can cause the entire application to fail. With microservices, applications handle total service failure by degrading functionality and not crashing the entire application.
An All-Inclusive Complete Platform for Microservices
AWS has integrated building blocks that support any application architecture, regardless of scale, load or complexity.
The Compute Processing Power of Microservices
Using Amazon ECS Coursera can now deploy software changes in minutes instead of hours in a resource-isolated environment. Localytics used AWS Lambda to build microservices that allowed their development teams to build custom analytics without central support.
- Containers: Amazon ECS
A highly scalable, high-performance container management service supports Docker contains and allows marketers to easily run applications on a managed cluster of Amazon EC2 instances.
- Serverless: AWS Lambda
AWS Lambda lets marketers run code without provisioning or managing servers. One just needs to load the code and Lambda manages everything that is required to run and scale your code with high availability.
Microservices architecture on AWS
While typical monolithic applications are built on different layers – a user interface (UI) layer, a business layer, and a persistence layer; the central theme of microservices architecture is to split the functionalities into cohesive verticals – not by employing technological layers but by implementing a specific domain.
A reference architecture for typical microservices application on AWS is represented by the diagram below:
Benefits of Microservices
The following are some major benefits of working with a microservices architecture:
- Agility
Microservices foster an organization of small, independent teams that take ownership of their services. Teams act within a small and well-understood context and are empowered to work more independently and more quickly. This shortens development cycles. The companies can benefit significantly from the aggregate throughput of the organization.
- Flexible Scaling
Microservices allow each service to be independently scaled to meet the demands for the application feature it supports. This enables teams to right-size infrastructure needs, accurately measure the cost of a feature, and maintain availability if a service experiences a spike in demand.
- Easy Deployment
Microservices enable continuous integration and continuous delivery, simplifying the process of trying out new ideas to roll back if something doesn’t work. The low cost of failure enables experimentation and makes it easier to update code, and accelerates time-to-market for new features.
- Technological Freedom
Microservices architecture doesn't follow a "one size fits all" approach. Teams have the freedom to choose the best tool to solve their specific problems. As a consequence, teams building microservices can choose the best tool for each job.
- Reusable Code
Dividing software into small, well-defined modules enables teams to use functions for multiple purposes. A service written for a certain function can be used as a building block for another feature. This allows an application to bootstrap off itself, as developers can create new capabilities without writing code from the scratch.
- Resilience
Service independence optimizes the applications’ resistance to failure. In a monolithic architecture, if a single component fails, it can cause the entire application to fail. With microservices, applications handle total service failure by degrading functionality and not crashing the entire application.
The Compute Processing Power of Microservices
AWS has integrated building blocks that support any application architecture, regardless of scale, load or complexity.
Using Amazon ECS Coursera can now deploy software changes in minutes instead of hours in a resource-isolated environment. Localytics used AWS Lambda to build microservices that allowed their development teams to build custom analytics without central support.
-
Containers: Amazon ECS
A highly scalable, high-performance container management service supports Docker contains and allows marketers to easily run applications on a managed cluster of Amazon EC2 instances.
-
Serverless: AWS Lambda
AWS Lambda lets marketers run code without provisioning or managing servers. One just needs to load the code and Lambda manages everything that is required to run and scale your code with high availability.
Microservices architecture on AWS
While typical monolithic applications are built on different layers – a user interface (UI) layer, a business layer, and a persistence layer; the central theme of microservices architecture is to split the functionalities into cohesive verticals – not by employing technological layers but by implementing a specific domain.
A reference architecture for typical microservices application on AWS is represented by the diagram below:
User Interface
Modern web applications often use JavaScript frameworks to implement a single-page application that communicates with a representational state transfer (REST) or RESTful API. Static web content can be served by the means of Amazon S3 (Simple Storage Service) and Amazon CloudFront.
Clients of a microservice witness a significant reduction in the latencies as microservice are served from the closest edge location and get responses either from a cache or a proxy server with optimized connections to the origin. However, microservices running close to each other don't benefit from content delivery networks. In some circumstances, this approach might actually add additional latency. The best practice under such a scenario would be to implement other caching mechanisms to reduce the chattiness and minimize the latencies.
Microservices
APIs constitute the front door of microservices, which implies that APIs serve as the entry point for applications logic behind a set of programmatic inferences, typically a ____ful web services API. This API accepts and processes calls from clients and might even implement functionality such as traffic management, request filtering, routing, caching, authentication, and authorization.
Implementation of Microservices
AWS has integrated building blocks to support the development of microservices. Two popular approaches are using AWS Lambda and Docker containers with AWS Fargate.
With AWS Lambda, you upload your code and allow Lambda to take care of everything needed to run and scale the implementation to meet your actual demand curve with high availability. No infrastructure administration is required. Lambda supports an array of programming languages and can be invoked from other AWS services or be called directly from any mobile or web application.
One of the biggest advantages of using AWS Lambda is that marketers can move quickly and can focus on their business logic because security and scaling are taken care of by AWS. The opinionated approach of Lambda drives a scalable platform.
Container-based deployment is a common approach to reduce operational efforts for deployment. The container technologies like Docker have proliferated in popularity in the last few years and offer several key benefits such as:
-
Portability
-
Productivity
-
Efficiency
The learning curve with containers can be steep and one has to think about security fixes for their Docker images and monitoring. Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS) eliminate the need to install, operate, and scale your cluster management infrastructure.
By deploying API calls, users can launch or stop the Docker-enabled applications, query the complete state of their cluster, and access many familiar features like security groups, Load Balancing, Amazon Elastic Block Store (Amazon EBS) volumes, and AWS Identity and Access Management (IAM) roles.
Continuous integration and continuous delivery (CI/CD) are best practices and a vital part of a DevOps initiative that enables rapid software changes while maintaining system stability and security.
Private Links
AWS PrivateLink is a highly available and scalable technology allowing users to privately connect their virtual private cloud (VPC) to supported AWS services, services hosted by other AWS accounts (VPC endpoint services), and supplemented by AWS Marketplace partner services.
Private links are a great way to improve the isolation and security of microservices architecture. A microservice, for instance, can be deployed in a totally separate VPC, fronted by a load balancer, and exposed to other microservices through an AWS PrivaeLink endpoint. With such a setup, using AWS PrivateLink, the network traffic to and from the microservice never traverses the public internet. Additionally, AWS PrivateLink allows users to connect microservices across different accounts and Amazon VPCs, with no need for firewall rules, path definitions, or route tables, simplifying network management. Using PrivateLink, software as a service (SaaS) providers, and ISVs can deploy their microservices-based solutions in complete operational isolation and with secure access as well.
Data Store to Persist the Data Needed By Microservices
The in-memory caches such as Memcached or Redis are the popular stores for session data. AWS offers both technologies as part of the managed Amazon ElastiCache service.
Putting a cache between application servers and a database is a common mechanism for reducing the read load on the database, which, in turn, may enable resources to be used to support more writes. Caches also improve latency.
Relational databases are very useful to store structural data and business objects. AWS offers six database engines (Microsoft SQL Server, Oracle, MySQL, MariaDB, PostgreSQL, and Amazon Aurora) as managed services through Amazon Relational Database Service (Amazon RDS).
Relational databases, nonetheless aren't meant for endless scale, which makes it difficult and time-intensive to apply techniques to support a high number of queries.
NoSQL databases have been designed to favor scalability, performance, and availability over the consistency of relational databases. One important element of NoSQL databases is that they typically don't enforce a strict schema. Data is distributed over partitions that can be horizontally scaled and are retrieved using partition keys.
As individual microservices are designed to perform one task well they have typically a simplified data model that might be more suitable for NoSQL persistence. NoSQL databases typically have different access patterns than relational databases; for instance, it’s not possible to join tables. One can use Amazon DynamoDB to create a database table that can store and retrieve any amount of data and serve any level of request traffic. DynamoDB delivers single-digit millisecond performance, however, certain use cases require response times in microseconds. Amazon DynamoDB Accelerator (DAX) provides caching capabilities for accessing data.
DynamoDB also offers an automatic scaling feature to dynamically adjust throughput capacity in response to actual traffic.
Reducing Operational Complexity
The typical microservices application on AWS are already managed; however, Amazon Elastic Compute Cloud (Amazon EC2) instances need to be managed. The operational efforts required to run, maintain, and monitor microservices can be further reduced by using a fully serverless architecture.
API Implementation
Architecting, deploying, monitoring, continuously improving, and maintaining an API can be a time-consuming task. Oftentimes, different API versions need to be run to assure backward compatibility of all clients. The different stages of the deployment cycle (for instance, development, testing, and production) further multiply the operational efforts.
Authorization is a critical feature for all APIs but is usually complex to build and involves repetitive work.
The following diagram highlights how API Gateway handles API calls and interacts with other components. Responses from websites, other backend services, and mobile devices are routed to the closest CloudFront Point of Presence to minimize latency and provide an optimum user experience.
Serverless microservices to Eliminate Operational Complexity
Lambda is tightly integrated with API Gateway. The ability to make synchronous calls from API Gateway to Lambda enables the creation of fully serverless applications and provides a platform where complete service is built out of managed services, which eliminates the architectural burden to design for scale and high availability, and eliminates the operational efforts of running & monitoring microservice’s underlying infrastructure.

A similar architecture with Docker containers is used with Fargate, so it’s essential to take care of the underlying infrastructure. Besides, DynamoDB, Amazon Aurora Serverless is used, which is an on-demand, auto-scaling configuration from Aurora (MySQL –compatible edition) where the database will automatically start up, shut down and scale capacity up or down based on the needs of your application.
Disaster Recovery
Typical microservices applications are implemented using the Twelve-Factor Application patterns. The process section states that “Twelve-factor processes are stateless and share-nothing. Any data that needs to persist must be stored in a stateful backing service, typically a database.”
For a typical microservices architecture, this means that the main factor for disaster recovery should be the downstream services that maintain the state of the application. These can be file systems, databases, or queues, for example. When creating a disaster recovery strategy, organizations most commonly plan for the recovery time objective and recovery point objective.
The recovery time objective is the maximum acceptable delay between the interruption of service and restoration of services. This objective determines what is considered an acceptable time window when service is unavailable and is defined by the organization.
The recovery point objective is the maximum acceptable amount of time since the last data recovery point. This objective determines what is considered an acceptable loss of data between the last recovery point and the interruption of service and is determined by the organization.
High Availability
This section stresses the high availability of different compute options.
Amazon EKS runs Kubernetes control and data plane instances across multiple Availability Zones to ensure high availability. Amazon EKS automatically detects and replaces unhealthy control plane instances, and provides automated version upgrades and patching for them. This control plane exists of at least two API server nodes and three etcd notes that run across three Availability Zones within a region. Amazon EKS uses the architecture of AWS Regions to maintain high availability.
Amazon ECR hosts images in a highly available and high-performance architecture, enabling users to reliably deploy images for container applications across Availability Zones. Amazon ECR works in conjunction with Amazon EKS, Amazon ECS, and Amazon Lambda, simplifying development and production workflow.
Deploying Lambda Based Applications
Users can put to use AWS CloudFormation to define, deploy and configure serverless applications. AWS SAM is natively supported by CloudFormation and defines simplified syntax for expressing serverless resources. To deploy your application one needs to specify the resources needed as a part of his application, along with their associated permissions policies in a CloudFormation template. Once the deployment artifacts are packaged, one can deploy the template. Based on AWS SAM, SAM Local is an AWS Command Line Interface tool that provides an environment for users to develop, test, and analyze their serverless applications locally before uploading them to Lambda runtime. One can stimulate the AWS runtime environment by using SAM Local to create a testing environment.
Distributed Systems Components
Apart from solving the challenges pertaining to individual microservices, AWS can also mitigate cross-service challenges such as service discovery, data consistency, asynchronous communication, and distributed monitoring and auditing.
Service Discovery
Enabling services to discover and interact with each other is one of the primary challenges with microservice architectures. The distributed characteristics of microservice architectures not only make it tougher for services to communicate but also present other challenges such as checking the health of those systems and announcing when new applications become available. One must also decide how and where the meta-information is to be stored such as configuration data that can be used by applications. Several techniques for performing service discovery on AWS for micro-services based architecture have been illustrated as under:
- DNS-based Service Discovery
Amazon ECS now includes integrated service discovery that enables your containerized services to discover and connect.
Amazon ECS now includes integrated service discovery that enables your containerized services to discover and connect. Amazon ECS creates and manages a registry of service names using the Route 53 Auto Naming API. Names are mapped automatically to a set of DNS records so that one can refer to a service by name in his code and write DNS queries to have the name resolve to the service's endpoint at runtime. One can specifically health check conditions in a service's task definition and Amazon ECS ensures that health service endpoints are returned by a service lookup.
Additionally, one can also use unified service discovery for services managed by Kubernetes. To enable this integration, AWS contributed to the External DNS project, a Kubernetes incubator project.
Another option is to use the capabilities of AWS Cloud Map that extends the capabilities of the Auto Naming APIs by enabling the service registry for resources such as Internet Protocols (IPs), Uniform Resource Locators (URLs), and Amazon Resource Names (ARNs). This API-based service discovery mechanism with a faster change propagation has the ability to use attributes to narrow down the set of discovered resources. The existing Route 53 Auto Naming resources are automatically upgraded to AWS Cloud Map.
- Third-Party Software
A different approach to implementing service discovery is using third-party software such as HashiCorp Consul, etcd, or Netflix Eureka. All three examples are distributed reliable key-value stores. For HashiCorp Consul, there’s an AWS Quick Start that sets up a flexible, scalable AWS Cloud environment and launches HashiCorp Consul automatically into a configuration of your choice.
- Service Meshes
Within an advanced microservices architecture, the actual application can be composed of hundreds or even thousands of services. Often the most complex part of an application is not the actual services by themselves but the communication between those services. Service meshes form an additional layer for handling inter-service communication, which is responsible for monitoring and controlling traffic in microservices architectures. This enables tasks, like service discovery, to be completely handled by this layer.
Typically a service mesh is split into a data plane and a control plane. The data plane is composed of a set of intelligent proxies that can be deployed with the application code as a special sidecar proxy to intercept all network communication between microservices. The control plane is responsible for communication with the proxies.
Service meshes are transparent, which implies that application developers aren’t aware of this additional layer and are not likely to make changes to the existing application code. AWS App Mesh is a service mesh that provides application-level networking to enable your services to communicate with each other across multiple types of commute infrastructure. App Mesh standardizes how the services of the user communicate with each other providing the users with complete visibility and ensuring high availability for their applications.
Users can put to use App Mesh with their existing or new microservices running on Amazon EC2, Fargate, Amazon ECS, Amazon EKS, and self-managed Kubernetes on AWS.
App Mesh can monitor and control communications for microservices running across clusters, orchestration systems, or VPCs as a single application without any code changes.
Distributed Data Management
Monolithic applications are typically backed by a large relational database, which defines a single data model common to all application components. Within a microservices approach, a central database would prevent the goal of building decentralized and independent components.
Building a centralized store of critical reference data curated by core data management tools and procedures provides a means for microservices to synchronize their critical data and possibly roll back the state. Using AWS Lambda with scheduled Amazon CloudWatch Events allows users to build a simple cleanup and deduplication mechanism.
When it comes to microservices architecture, event sourcing enables decoupling different parts of an application by using a publish and subscribe pattern, and it feeds the same event data into different data models for separate microservices.
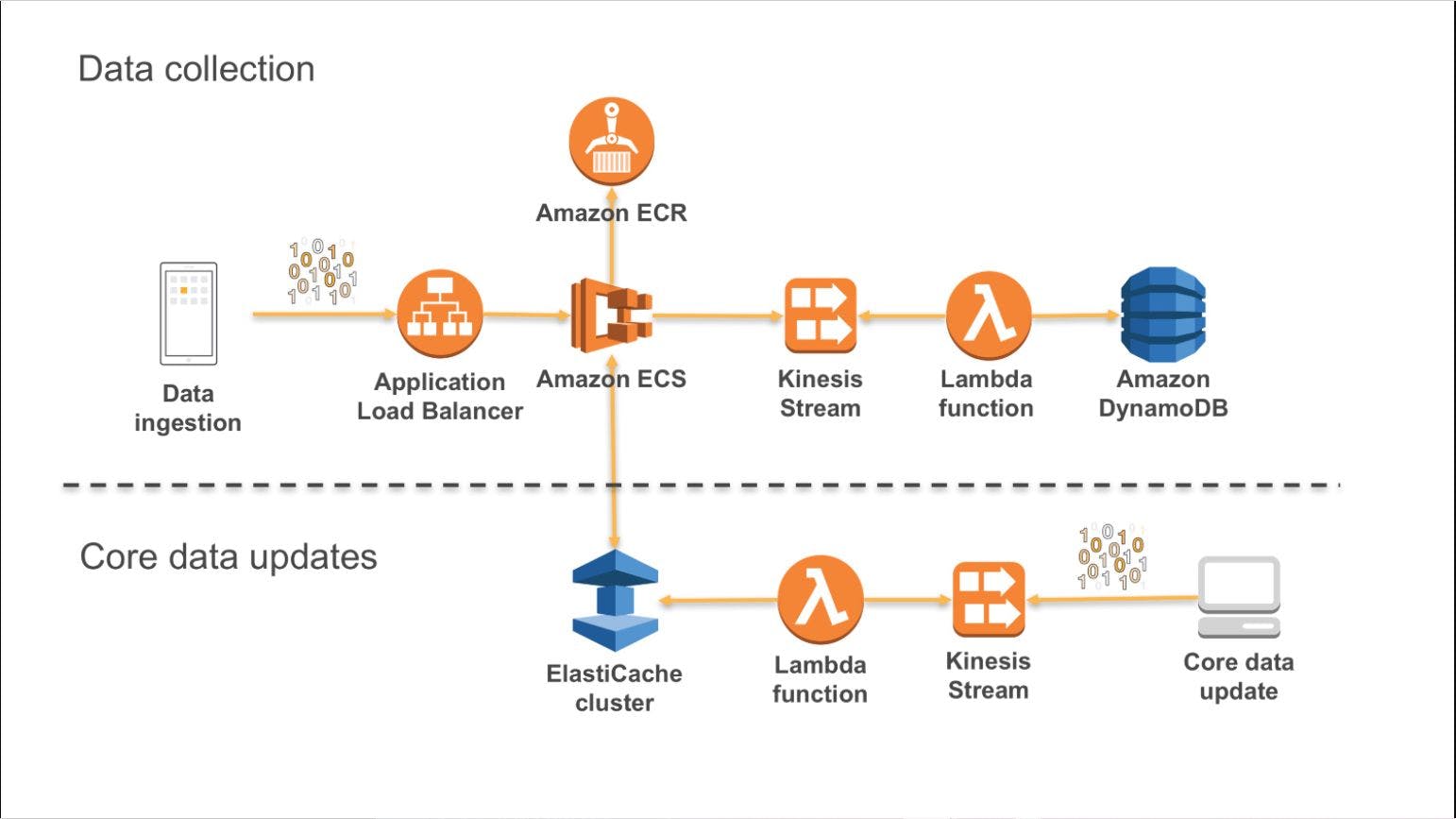
The diagram below shows how the event sourcing pattern can be implemented on AWS.
Amazon Kinesis Data Streams serves as the main component of the central event store, which captures application changes as events and persists them on Amazon S3.
Amazon Kinesis Data Streams serves as the main component of the central event store, which captures application changes as events and persists them on Amazon S3.
Configuration Management
Within a typical microservices architecture, with dozens of different services, each service needs access to several downstream services and infrastructure components that expose data to service. Examples include message queues, databases, and other microservices. One of the prime challenges remains to configure each service consistently to provide information about the connection to downstream services and infrastructure. The configuration additionally also should have information about the environment in which the service is operating, and restarting the application to use new configuration data shouldn’t be necessary.
Asynchronous Communication and Lightweight Messaging
Communication in traditional monolithic applications is straightforward – a part of the application uses method calls or an internal event distribution mechanism to communicate with the other parts. If the same application is implemented using decoupled microservices, the communication between different parts of the application must be implemented using network communication.
REST-based Communication
The HTTP/S protocol is the most popular way to implement synchronous communication between microservices. In most cases, RESTful APIs use HTTP as a transport layer. The REST architectural style relies on stateless communication, uniform interfaces, and standard methods.
With API Gateway, one can create an API that acts as a “front door” for applications to access data, business logic, or functionality from your backend services. API developers can create APIs that access AWS or other web services, as well as data stored in the AWS Cloud. An API object defined with the API Gateway service is a group of resources and methods.
Asynchronous Messaging and Event Passing
Message passing is an additional pattern used to implement communication between microservices. Services communicate by exchanging messages in a queue. A major benefit of this communication style is that it's not necessary to have a service discovery and services are loosely coupled.
Synchronous services are tightly coupled, which implies a problem in a synchronous downstream dependency and has an immediate impact on the upstream callers. Retries from upstream callers can quickly fan out and amplify problems.
Depending on specific requirements, like protocols, AWS offers different services that assist in implementing this pattern. One possible implementation uses a combination of Amazon Simple Queue Service (Amazon SQS) and Amazon Simple Notification Service (Amazon SNS).
Both services work together in conjunction. Amazon SNS enables applications to send messages to multiple subscribers through a push mechanism. By using Amazon SNS & Amazon SQS together, a single message can be delivered to multiple customers.

Orchestration and State Management
The distributed character of microservices makes it challenging to orchestrate workflows when multiple microservices are involved. However, the orchestration services shouldn’t be added directly to the services as it introduces tighter coupling and makes it tougher to quickly replace the individual services.
**
**
One can use AWS Step Functions to build applications from individual components that each perform a discrete function.
**
**
Step Functions is a part of the AWS serverless platform that supports the orchestration of Lambda functions as well as applications based on computing resources such as Amazon EC2, Amazon EKS, and Amazon ECS, and additional services like Amazon SageMaker and AWS Glue.
**
**
To build workflows, Step Functions uses the Amazon States Language. Workflows can contain sequential or parallel steps as well as branching steps.
Distributed Monitoring
A microservices architecture consists of many different distributed parts that have to be monitored. One can use Amazon CloudWatch to collect and track metrics, centralize and monitor log files, set alarms, and automatically react to changes in your AWS environment. CloudWatch can monitor AWS resources such as Amazon EC2 instances, DynamoDB tables, and Amazon RDS DB instances, as well as custom metrics generated by your applications and services, and any log files your applications generate.
Monitoring
One can use CloudWatch to gain system-wide visibility into resource utilization, application performance, and operational health. CloudWatch provides a reliable, scalable, and flexible monitoring solution that one can start using within minutes. One is no longer required to set up, manage, and scale his monitoring systems and infrastructure. In a microservices architecture, the capability of monitoring custom metrics uses CloudWatch as an additional benefit because developers can decide the metrics that should be collected for each service. Additionally, dynamic scaling can be implemented based on custom metrics. **
**
Besides Amazon Cloudwatch, one can also use CloudWatch Container Insights to collect, aggregate, and summarize metrics and logs from containerized applications and microservices.
Centralizing Logs
For troubleshooting and identifying issues, troubleshooting is critical. With the help of microservices, teams can ship many more releases than ever before and encourage engineering teams to run experiments on new features in production. Understanding customer impact is crucial to gradually improve an application.
Most AWS services centralize their log files by default. The primary destinations for log files on AWS are Amazon S3 and Amazon CloudWatch logs.
Distributed Tracing
In many cases, a set of microservices works together to handle a request. AWS X-Ray can help in such a situation. **
**
X-Ray works with Amazon EC2, Amazon ECS, AWS Lambda, and AWS Elastic Beanstalk.
The central idea of AWS X-Ray is the use of correlation IDs, which happen to be the unique identifiers attached to all requests and messages related to a specific event chain.
Options for log analysis on AWS
Searching, analyzing, and visualizing log data is an important aspect of understanding distributed systems. Amazon CloudWatch Logs Insights enables users to explore, analyze and visualize their logs instantly. This facilitates quick troubleshooting of operational problems. Another option for analyzing log files is to use Amazon OpenSearch Service together with Kibana.
Another option for analyzing log files is to use Amazon Redshift with Amazon QuickSight
Alternatively, when logs are stored in Amazon S3 buckets, the log data can be loaded in different AWS data services, such as Redshift or Amazon EMR To analyze the data stored in the log stream and find anomalies.

Chattiness
By breaking monolithic applications into small microservices, the communication overhead increases as the microservices have to talk to one another. In many implementations, REST over HTTP is used as it is a lightweight communication protocol. However, high message volumes can cause issues. However, if for any reason users consolidate an increased number of services just to reduce chattiness, they should review their problem domains and their domain model.
Caching
Caches are a great way to reduce the latency and chattiness of microservices architectures. Several caching layers are possible, depending on the actual use case and bottlenecks. Many microservice applications running on AWS use ElastiCache to reduce the volume of calls to other microservices by caching results locally. API Gateway provides a built-in caching layer to reduce the load on the backend servers. Additionally, caching is also useful to reduce the load from the data persistence layer. The challenge for any caching mechanism is to find the right balance between a good cache hit rate and the timeless consistency of data.
Auditing
Another challenge to address in a microservices architecture is ensuring visibility of user actions on each service and being able to get a good overall view across all services at an organizational level.
Changes need to be tracked at the level of individual services as well as across services running on the wider system. Typically changes occur frequently in microservices architectures that make auditing changes even more important.
Events & Real-Time Actions
The integration of Amazon CloudWatch Events with CloudTrail allows users to define custom events based on a fixed schedule.
When an event is announced and matches a defined rule, a pre-defined group of people in an organization can be immediately notified, so that they might take appropriate action. If the required action can be automated, the rule can automatically trigger a built-in workflow or invoke a Lambda function to resolve the issue.
Resource inventory and change management
To maintain control over fast-changing infrastructure configurations in an agile development environment, having a more automated, managed approach to auditing and controlling your architecture is essential.
Although CloudTrail and CloudWatch Events are important building blocks to track and respond to infrastructure changes across microservices, AWS Config rules enable a company to define security policies with specific rules to automatically detect, track and alert you to policy violations.
The next example demonstrates how it is possible to detect, inform and automatically react to non-compliant configuration changes within your microservices architecture. A member of the development team has made a change to the API Gateway for a microservice to allow the endpoint to accept inbound HTTP traffic, rather than only allowing HTTP requests.
Conclusion
Microservices architecture is a distributed design approach intended to overcome the limitations of traditional monolithic architectures. Microservices help scale applications and organizations while improving cycle times. However, many challenges might add additional architectural complexity and operational burden.
AWS offers a large portfolio of managed services that can help protect teams build microservices architectures and minimize architectural and operational complexity. This blog discusses the relevant AWS services and how to implement typical patterns such as service discovery or event sourcing natively with AWS services.
L O A D I N G
. . . comments & more!
. . . comments & more!







