visit
Automatic Filtering: Sentence-Level Analysis
by The FeedbackLoop: #1 in PM EducationJanuary 17th, 2024
Too Long; Didn't Read
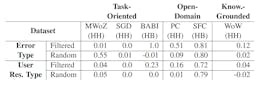
Explore the precision of automatic filtering through sentence-level analysis. Figure 2 visually represents similarity ranges between user responses and error-indicating sentences, highlighting the dominance of SFC in phrase identification. Discover the nuances of clusters in lower similarity ranges from various datasets.Authors:
(1) Dominic Petrak, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany;
(2) Nafise Sadat Moosavi, Department of Computer Science, The University of Sheffield, United Kingdom;
(3) Ye Tian, Wluper, London, United Kingdom;
(4) Nikolai Rozanov, Wluper, London, United Kingdom;
(5) Iryna Gurevych, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany.
Table of Links
Manual Error Type Analysis and Taxonomies
Automatic Filtering for Potentially Relevant Dialogs
Conclusion, Limitation, Acknowledgments, and References
A Integrated Error Taxonomy – Details
B Error-Indicating Sentences And Phrases
C Automatic Filtering – Implementation
D Automatic Filtering – Sentence-Level Analysis
E Task-Oriented Dialogs – Examples
F Effectiveness Of Automatic Filtering – A Detailed Analysis
G Inter-Annotator Agreement – Detailed Analysis
I Hyperparameters and Baseline Experiments
J Human-Human Dialogs – Examples
For context:
D Automatic Filtering – Sentence-Level Analysis
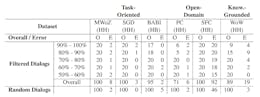
As described in Section 5, we filter on sentencelevel for similar user responses. Figure 2 illustrates the ranges of similarity between the sentences extracted from the user utterances and the errorindicating sentences, i.e., 50%−60%, 60%−70%, 70% − 80%,80% − 90%, 90% − 100%. It reflects the share in identified phrases from each of the datasets (see Table 3). Most of the phrases were identified in SFC (Hancock et al., 2019). Only a small amount of phrases came from the other datasets which might be the reason for the clusters in the lower ranges.
This paper is under CC BY-NC-SA 4.0 DEED license.
L O A D I N G
. . . comments & more!
. . . comments & more!