visit
Hyperparameters and Baseline Experiments in Dialog Systems by@feedbackloop
Hyperparameters and Baseline Experiments in Dialog Systems
by The FeedbackLoop: #1 in PM EducationJanuary 17th, 2024
Too Long; Didn't Read
Baseline experiments in dialog systems unfold with key hyperparameter settings. Models trained for five epochs, extended to ten for erroneous dialogs, featured a batch size of 32, learning rate of 5e − 5, and AdamW optimizer. LLAMA adopted unique finetuning parameters. Results, reflected in Table 17, elucidate the interplay of data quality, system errors, and model performance through F1-Score and BLEU metrics.Authors:
(1) Dominic Petrak, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany; (2) Nafise Sadat Moosavi, Department of Computer Science, The University of Sheffield, United Kingdom; (3) Ye Tian, Wluper, London, United Kingdom; (4) Nikolai Rozanov, Wluper, London, United Kingdom; (5) Iryna Gurevych, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany.Table of Links
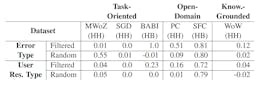
Manual Error Type Analysis and Taxonomies
Automatic Filtering for Potentially Relevant Dialogs
Conclusion, Limitation, Acknowledgments, and References
A Integrated Error Taxonomy – Details
B Error-Indicating Sentences And Phrases
C Automatic Filtering – Implementation
D Automatic Filtering – Sentence-Level Analysis
E Task-Oriented Dialogs – Examples
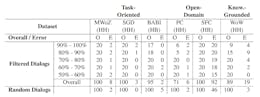
F Effectiveness Of Automatic Filtering – A Detailed Analysis
G Inter-Annotator Agreement – Detailed Analysis
I Hyperparameters and Baseline Experiments
J Human-Human Dialogs – Examples
I Hyperparameters and Baseline Experiments
Hyperparameters All baseline models were trained for five epochs. For the experiment using erroneous dialogs, we trained the models for ten epochs. We used a batch size of 32 and a learning rate of 5e − 5 with no warmup steps. As optimizer, we used the implementation of AdamW 11 (Loshchilov and Hutter, 2019) in Pytorch. Except for LLAMA (Touvron et al., 2023), we fully-finetuned all models. For LLAMA, we only finetuned the LoRA (Hu et al., 2022) weights, using a rank of 8, an alpha of 16, and a dropout rate of 0.05.
Results Table 17 shows the results of our baseline experiments using word-overlapping F1-Score and BLEU (Papineni et al., 2002).
This paper is under CC BY-NC-SA 4.0 DEED license.
L O A D I N G
. . . comments & more!
. . . comments & more!