visit
Implementing Automatic Filtering with PyTorch and Transformers
by The FeedbackLoop: #1 in PM EducationJanuary 17th, 2024
Too Long; Didn't Read
Dive into the world of automatic content filtering implemented with PyTorch and Transformers. Utilizing the allmpnet-base-v2 Sentence-Transformer, powered by a Tesla V100-SXM3 GPU, this 12-layer Transformer model calculates cosine similarity, achieving efficiency in content evaluation with an average runtime of 76 minutes per dataset.Authors:
(1) Dominic Petrak, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany;
(2) Nafise Sadat Moosavi, Department of Computer Science, The University of Sheffield, United Kingdom;
(3) Ye Tian, Wluper, London, United Kingdom;
(4) Nikolai Rozanov, Wluper, London, United Kingdom;
(5) Iryna Gurevych, UKP Lab, Department of Computer Science, Technical University of Darmstadt, Germany.
Table of Links
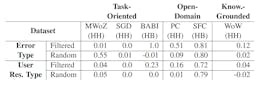
Manual Error Type Analysis and Taxonomies
Automatic Filtering for Potentially Relevant Dialogs
Conclusion, Limitation, Acknowledgments, and References
A Integrated Error Taxonomy – Details
B Error-Indicating Sentences And Phrases
C Automatic Filtering – Implementation
D Automatic Filtering – Sentence-Level Analysis
E Task-Oriented Dialogs – Examples
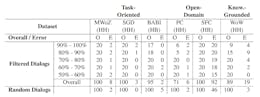
F Effectiveness Of Automatic Filtering – A Detailed Analysis
G Inter-Annotator Agreement – Detailed Analysis
I Hyperparameters and Baseline Experiments
J Human-Human Dialogs – Examples
C Automatic Filtering – Implementation
To implement the automatic filtering (Section 5) we use PyTorch (Paszke et al., 2019), the Transformers library (Wolf et al., 2020), and the pretrained allmpnet-base-v2 Sentence-Transformer[10]. It is based on MPNet (Song et al., 2020) and finetuned on a large corpus of sentence pairs from multiple tasks and domains, e.g., Yahoo Answers (Zhang et al., 2015) and Reddit Comments (Henderson et al., 2019), using a contrastive objective. It is a 12- layer Transformer model with a vocabulary size of 30,527 words that calculates the cosine similarity between two sentences in a 768-dimensional dense vector space.
Our compute infrastructure consists of one Tesla V100-SXM3 GPU (with 32 GB memory) and it took an average of 76 mins to run automatic filtering on one dataset.
[10] Model page in the HuggingFace Model Hub, last accessed
This paper is under CC BY-NC-SA 4.0 DEED license.
L O A D I N G
. . . comments & more!
. . . comments & more!