visit
Distributed Tracing: Past, Present and Future by@zerok
557 reads
Distributed Tracing: Past, Present and Future
by ZeroKJuly 8th, 2023
Too Long; Didn't Read
In this article, we will explore "Distributed Tracing" which is a technology that allows us to track a single request as it traverses several different components/microservices of a distributed environment.Distributed Tracing is a divisive topic. Once the , the technology was expected to revolutionize observability.
In this article, let's explore Distributed Tracing in depth
- What is special about Distributed Tracing and why do we need it?
- What are the problems with distributed tracing today?
- What are upcoming developments and how do they address existing challenges?
Introduction - How Distributed Tracing Works
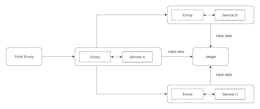
For the uninitiated, Distributed Tracing is a technology that allows us to track a single request as it traverses several different components/microservices of a distributed environment. Each network call made in the request's path is captured and represented as a span.
Why we need Distributed Tracing in the first place
Distributed tracing is unique because it focuses on a request as the unit for observability. In a monitoring/ metrics platform, a component (e.g., a service, host) is the fundamental unit that is being observed. One can ask these platforms questions about the behavior of this unit as a whole, over time. For example, what is this service's health/ throughput /error rate in a specific timeframe?
With logs, the fundamental unit being observed is an event - e.g., whenever an event occurs during code execution, print some information. These "events" are subjectively defined by developers while writing code. The challenge with logs is that they are all disjointed, with each component printing its own form of log messages in isolation, with no easy way to connect them together to make sense.
The basic case for distributed tracing lies in the argument that this orientation around requests is the closest to the end user's experience. And as a result, it is also the most intuitive for how we'd like to examine and troubleshoot distributed architectures.
The evolution of Distributed Tracing
Distributed Tracing has risen in importance due to the widespread adoption of distributed software architectures in the last decade.
The modern microservices-based architecture is an evolution from the late 90s internet growth story, when it became common to use request-response systems.
"With the late 90s and explosive growth of the internet, came the huge proliferation of request-response systems, such as two-tier websites, with a web server frontend and a database backend... Requests were a new dimension for reasoning about systems, orthogonal to any one machine or process in aggregate."
- Distributed Tracing in Practice, O'Reilly Media
-
Google's Dapper paper released in 2010 was the beginning of distributed tracing
-
In the next few years, two more companies open-sourced their own distributed tracing systems (Twitter open-sourced Zipkin in 2012 and Uber open-sourced Jaeger in 2017). Zipkin and Jaeger continue to be among the most popular distributed tracing tools even today
-
Since 2016, there has been a significant effort to standardize distributed tracing across components through the OpenTracing project. OpenTracing eventually became in 2019. OpenTelemetry is widely popular and has thousands of contributors globally
- Now Distributed Tracing is widely regarded as the third "pillar" of observability alongside metrics and logs. Most major monitoring and observability players provide distributed tracing tools as part of their products.
State of Distributed Tracing: Theory vs Reality
However, despite the promise, excitement, and community effort, the adoption of distributed tracing today is around ~25%. It is not uncommon to find companies on microservices architectures who are making do with logs and metrics, even though they clearly need distributed tracing.
Challenges with Distributed Tracing today
There are several problems with distributed tracing today that companies have to overcome to get value - all of which don't get discussed as widely in the mainstream narrative.1. Implementation is hard!
To implement distributed tracing in a service today, we need to make a code change and a release. While making code changes is a common-enough ask for observability, the challenge specifically with distributed tracing is this - every service or component needs to be instrumented to get a distributed trace, or the trace breaks.
One cannot just get started with a single service - as one can with monitoring or logging - and realize value. Distributed tracing requires instrumentation across a collective set of services to generate usable traces.
2. Need for complex sampling decisions
Next, the volume of trace data generated by Distributed Tracing can be overwhelming. Imagine hundreds of services each emitting a small amount of trace data for every single request. This is going to be millions of requests per second, and makes distributed tracing expensive both in terms of storage and network bandwidth.
While logging also does the same thing (and emits more data per request, which is then managed by massive log aggregation tools), the difference is that most companies today already have logging. Introducing one more data type which is going to be almost as voluminous as logging is a daunting task and will likely double the spend.
3. But sampling meaningfully diminishes the value
Let's assume a company goes through the effort of instrumenting every service/ component and then deciding the sampling strategy to ensure they don't break the bank.
Imagine a developer's experience - "I can't find the issue I know is there. I generated the error, but I cannot find the corresponding trace".
4. Developer usage is low frequency
Given these constraints, today Distributed Tracing is primarily sold as a way to troubleshoot performance problems.
Remember that a basic distributed trace really just tells us who called who and how long each span took. Distributed traces don't tell us what happened within the service that caused the error/ high latency. For that, developers still have to look at the log message and/ or reproduce the issue locally to debug.
Impact of all these challenges
In summary:- Distributed tracing is hard to implement
- Distributed Tracing needs extensive sampling to control costs
- But sampling reduces the value considerably
- As a result, developers only use tracing for the odd one-off performance use case
Future of distributed tracing
Instant instrumentation with no code changes
Imagine dropping in an agent and being able to cover an entire distributed system (all services, components) in one go without code changes.
Sampling gives way to AI-based selection of requests-of-interest
In an LLM world, random sampling begins to look like a relic from the dark ages. Ideally, we should be able to look at 100% of traces, identify anything that looks anomalous, and store that for future examination. No more random sampling.
The emergence of "rich" distributed traces that enable all debugging
A true leap into the next generation of tracing will be when tracing evolves from the realm of "performance issues only" to "all issues". That is when the true power of distributed tracing is unleashed.
Imagine a scenario where each span in each trace has:
- Request & response payloads (with PII masking)
- Stack traces for any exceptions
- Logs
- Kubernetes events
- Pod states
-
And anything else that occurred along that span
Summary
In summary, Distributed Tracing is a necessary and intuitive view required for being able to observe distributed application architectures in production.
L O A D I N G
. . . comments & more!
. . . comments & more!