





























Jan 01, 1970
3,028 পড়া
ডিপ লার্নিং মডেল তৈরি এবং প্রশিক্ষণের জন্য 10 সেরা কেরাস ডেটাসেট
দ্বারা Open Datasets Compiled by HackerNoon2023/03/08
অতিদীর্ঘ; পড়তে
কেরাস একটি উচ্চ-স্তরের API প্রদান করে যা জটিল নিউরাল নেটওয়ার্ক মডেল তৈরি ও প্রশিক্ষণের প্রক্রিয়াকে সহজ করে। পূর্ব-নির্মিত স্তর এবং ফাংশনগুলির বিস্তৃত পরিসরের সাথে, বিকাশকারীরা সহজেই গভীর শিক্ষার মডেলগুলি তৈরি এবং প্রশিক্ষণ দিতে পারে। কেরাস প্রশিক্ষণ এবং অনুমানের জন্য GPU ত্বরণকে সমর্থন করে, এটি গবেষণা এবং শিল্প অ্যাপ্লিকেশন উভয়ের জন্য একটি জনপ্রিয় পছন্দ করে তোলে।কেরাস একটি উচ্চ-স্তরের API প্রদান করে যা জটিল নিউরাল নেটওয়ার্ক মডেল তৈরি এবং প্রশিক্ষণের প্রক্রিয়াকে সহজ করে। পূর্ব-নির্মিত স্তর এবং ফাংশনগুলির বিস্তৃত পরিসরের সাথে, বিকাশকারীরা অপ্টিমাইজেশান অ্যালগরিদম ব্যবহার করে বড় ডেটাসেটে গভীর শিক্ষার মডেলগুলি সহজেই তৈরি এবং প্রশিক্ষণ দিতে পারে। কেরাস প্রশিক্ষণ এবং অনুমানের জন্য GPU ত্বরণকে সমর্থন করে, এটি গবেষণা এবং শিল্প অ্যাপ্লিকেশন উভয়ের জন্য একটি জনপ্রিয় পছন্দ করে তোলে।
"কেরাস ডেটাসেট" কি?
কেরাস ডেটাসেট হল প্রি-প্রসেসড ডেটাসেট যা কেরাস লাইব্রেরির সাথে আগে থেকে ইনস্টল করা হয়। এই ডেটাসেটগুলি সাধারণত চিত্র শ্রেণীবিভাগ, পাঠ্য শ্রেণীবিভাগ এবং রিগ্রেশনের মতো বিভিন্ন কাজের বেঞ্চমার্কিং মডেলের জন্য গভীর শিক্ষা সম্প্রদায়ে ব্যবহৃত হয়। এই ডেটাসেটগুলি ব্যবহার করে, বিকাশকারীরা বিভিন্ন গভীর শিক্ষার মডেলগুলির সাথে পরীক্ষা করতে পারে এবং সহজেই তাদের কর্মক্ষমতা তুলনা করতে পারে।
এই নিবন্ধটি বিশ্বব্যাপী বিকাশকারী এবং গবেষকদের কাছে অ্যাক্সেসযোগ্য ডিপ লার্নিং মডেল তৈরি এবং প্রশিক্ষণের জন্য সেরা কেরাস ডেটাসেটগুলি দেখে।
কেরাস ডেটাসেটের তালিকা
1.
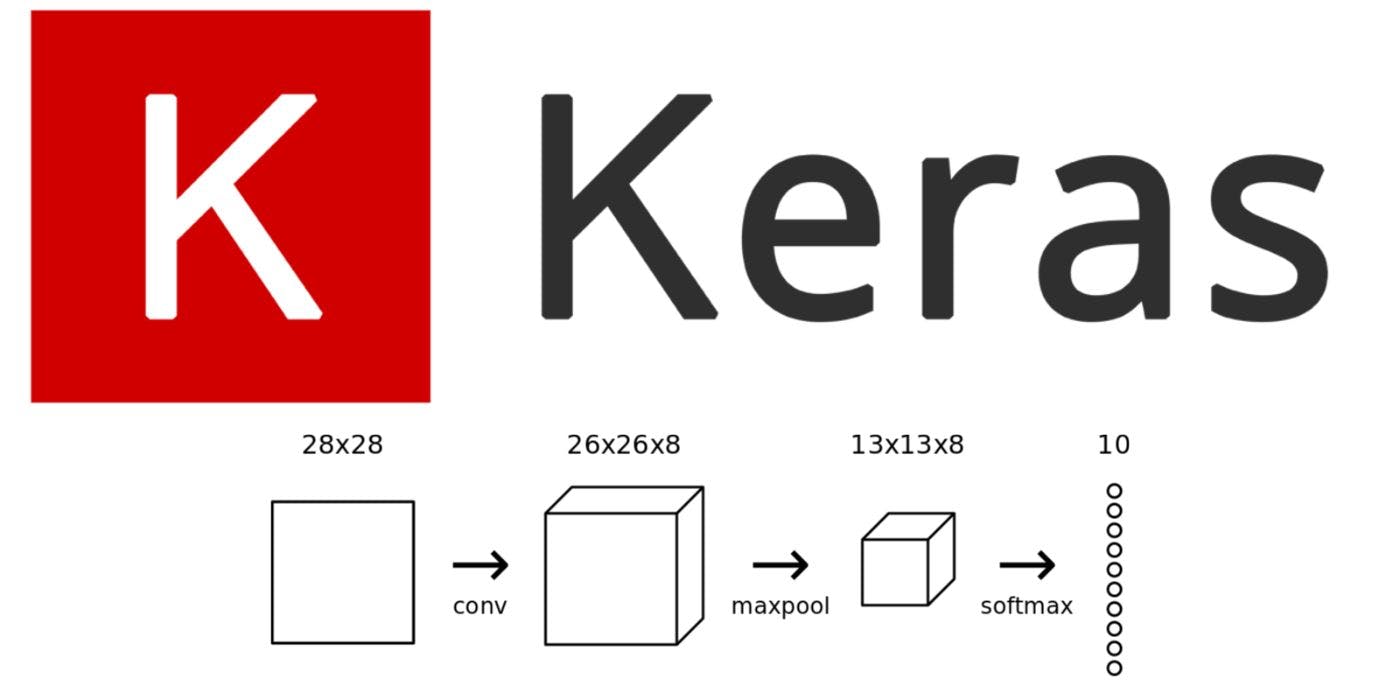
MNIST ডেটাসেট মেশিন লার্নিং এবং কম্পিউটার ভিশনের ক্ষেত্রে জনপ্রিয় এবং ব্যাপকভাবে ব্যবহৃত হয়। এটিতে হাতে লেখা 0-9 সংখ্যার 70,000টি গ্রেস্কেল চিত্র রয়েছে, যার মধ্যে 60,000টি প্রশিক্ষণের জন্য এবং 10,000টি পরীক্ষার জন্য রয়েছে। প্রতিটি চিত্রের আকার 28x28 পিক্সেল এবং একটি সংশ্লিষ্ট লেবেল রয়েছে যা নির্দেশ করে যে এটি কোন সংখ্যাগুলিকে প্রতিনিধিত্ব করে৷
এই ডেটাসেট থেকে ডাউনলোড করা যেতে পারে
tf.keras.datasets.mnist.load_data(path="mnist.npz") 2.
CIFAR-10 ডেটাসেটে 10টি ক্লাসে 60,000টি 32x32টি রঙিন ছবি রয়েছে, প্রতি ক্লাসে 6,000টি ছবি রয়েছে। এটিতে মোট 50,000টি প্রশিক্ষণের ছবি এবং 10,000টি পরীক্ষার ছবি রয়েছে যা আরও পাঁচটি প্রশিক্ষণ ব্যাচে এবং একটি পরীক্ষা ব্যাচে বিভক্ত, প্রতিটিতে 10,000টি ছবি রয়েছে।
এই ডেটাসেট থেকে ডাউনলোড করা যেতে পারে
tf.keras.datasets.cifar10.load_data() 3.
CIFAR-100 ডেটাসেটে 60,000টি (50,000 প্রশিক্ষণের ছবি এবং 10,000 পরীক্ষার ছবি) 32x32 রঙের ছবি 100টি ক্লাসে রয়েছে, প্রতি ক্লাসে 600টি ছবি রয়েছে। 100টি শ্রেণীকে 20টি সুপার-ক্লাসে বিভক্ত করা হয়েছে, একটি সূক্ষ্ম লেবেল সহ এটির শ্রেণী বোঝানোর জন্য এবং একটি মোটা লেবেল যা এটির অন্তর্গত সুপার-ক্লাসের প্রতিনিধিত্ব করে।
এই ডেটাসেট থেকে ডাউনলোড করা যেতে পারে
tf.keras.datasets.cifar100.load_data(label_mode="fine") 4.
ফ্যাশন MNIST ডেটাসেটটি মূল MNIST ডেটাসেটের প্রতিস্থাপন হিসাবে Zalando রিসার্চ দ্বারা তৈরি করা হয়েছিল। ফ্যাশন MNIST ডেটাসেটে 70,000টি গ্রেস্কেল ছবি (60,000টির প্রশিক্ষণ সেট এবং 10,000টির একটি পরীক্ষামূলক সেট) পোশাকের আইটেম রয়েছে।
চিত্রগুলি 28x28 পিক্সেল আকারের এবং টি-শার্ট/টপস, ট্রাউজার, পুলওভার, ড্রেস, কোট, স্যান্ডেল, শার্ট, স্নিকার, ব্যাগ এবং গোড়ালি বুট সহ 10টি বিভিন্ন শ্রেণীর পোশাকের আইটেমগুলিকে উপস্থাপন করে৷ এটি মূল MNIST ডেটাসেটের অনুরূপ, তবে পোশাকের আইটেমগুলির বৃহত্তর জটিলতা এবং বৈচিত্র্যের কারণে আরও চ্যালেঞ্জিং শ্রেণীবিভাগের কাজ রয়েছে৷
এই ডেটাসেট থেকে ডাউনলোড করা যেতে পারে
tf.keras.datasets.fashion_mnist.load_data()
5.
আইএমডিবি ডেটাসেটটি সাধারণত অনুভূতি বিশ্লেষণের জন্য ব্যবহৃত হয়, যেখানে লক্ষ্য হল তাদের বিষয়বস্তুর উপর ভিত্তি করে পর্যালোচনাগুলিকে ইতিবাচক বা নেতিবাচক হিসাবে শ্রেণীবদ্ধ করা। এটি ইন্টারনেট মুভি ডেটাবেস ওয়েবসাইট থেকে 50,000টি মুভি রিভিউ (প্রশিক্ষণ সেট 25,000 এবং একটি পরীক্ষা সেট 25,000) এর একটি সংগ্রহ নিয়ে গঠিত, ইতিবাচক এবং নেতিবাচক পর্যালোচনাগুলির মধ্যে সমানভাবে বিভক্ত।
এই ডেটাসেটের প্রতিটি পর্যালোচনা হল একটি পাঠ্য নথি, পূর্ব-প্রসেস করা এবং পূর্ণসংখ্যার ক্রমগুলিতে রূপান্তরিত, যেখানে প্রতিটি পূর্ণসংখ্যা পর্যালোচনায় একটি শব্দ উপস্থাপন করে। শব্দভান্ডারের আকার ডেটাসেটের 10,000টি ঘন ঘন শব্দের মধ্যে সীমাবদ্ধ এবং যে কোনও কম ঘন ঘন শব্দ একটি বিশেষ "অজানা" টোকেন দিয়ে প্রতিস্থাপিত হয়।
এই ডেটাসেট থেকে ডাউনলোড করা যেতে পারে
tf.keras.datasets.imdb.load_data( path="imdb.npz", num_words=None, skip_top=0, maxlen=None, seed=113, start_char=1, oov_char=2, index_from=3, **kwargs ) 6.
বোস্টন হাউজিং ডেটাসেটে বোস্টন এলাকার আবাসন সম্পর্কিত তথ্য রয়েছে। এই তথ্যে 506টি দৃষ্টান্ত রয়েছে (404টি প্রশিক্ষণ এবং 102টি পরীক্ষার দৃষ্টান্ত), প্রতিটি উদাহরণের জন্য বৈশিষ্ট্য সহ।
গুণাবলীতে পরিমাণগত এবং শ্রেণীগত পরিবর্তনশীলগুলির মিশ্রণ রয়েছে, যেমন প্রতি বাসস্থানে কক্ষের গড় সংখ্যা, মাথাপিছু অপরাধের হার এবং শহর প্রতি নন-রিটেল ব্যবসার একর অনুপাত।
এই ডেটাসেট থেকে ডাউনলোড করা যেতে পারে
tf.keras.datasets.boston_housing.load_data( path="boston_housing.npz", test_split=0.2, seed=113 ) 7.
ওয়াইন কোয়ালিটির ডেটাসেটে লাল এবং সাদা ওয়াইনের নমুনার তথ্য রয়েছে। এই ডেটাসেটের লক্ষ্য হল পিএইচ, ঘনত্ব, অ্যালকোহল সামগ্রী এবং সাইট্রিক অ্যাসিড সামগ্রীর মতো রাসায়নিক বৈশিষ্ট্যের উপর ভিত্তি করে ওয়াইনের গুণমানকে শ্রেণিবদ্ধ করা।
এই ডেটাসেটের ভেরিয়েবলগুলির মধ্যে রয়েছে:
- স্থির অম্লতা - ওয়াইনে স্থির অ্যাসিডের সংখ্যা, g/dm^3 এ প্রকাশ করা হয়।
- উদ্বায়ী অম্লতা - ওয়াইনে উদ্বায়ী অ্যাসিডের সংখ্যা, g/dm^3 এ প্রকাশ করা হয়।
- সাইট্রিক অ্যাসিড - ওয়াইনে সাইট্রিক অ্যাসিডের পরিমাণ, g/dm^3 এ প্রকাশ করা হয়।
- অবশিষ্ট চিনি: ওয়াইনে অবশিষ্ট চিনির পরিমাণ, g/dm^3 এ প্রকাশ করা হয়।
- ক্লোরাইড - ওয়াইনে ক্লোরাইডের পরিমাণ, g/dm^3 এ প্রকাশ করা হয়।
- বিনামূল্যে সালফার ডাই অক্সাইড - ওয়াইনে বিনামূল্যে সালফার ডাই অক্সাইডের পরিমাণ, mg/dm^3 এ প্রকাশ করা হয়।
- মোট সালফার ডাই অক্সাইড - ওয়াইনে মোট সালফার ডাই অক্সাইডের পরিমাণ, mg/dm^3 এ প্রকাশ করা হয়।
- ঘনত্ব - ওয়াইনের ঘনত্ব, g/cm^3 এ প্রকাশ করা হয়।
- pH - ওয়াইনের pH স্তর।
- সালফেটস - ওয়াইনে সালফেটের সংখ্যা, g/dm^3 এ প্রকাশ করা হয়।
- অ্যালকোহল - ওয়াইনের অ্যালকোহল সামগ্রী, % ভলিউমে প্রকাশ করা হয়েছে।
- গুণমান - ওয়াইনের মানের রেটিং, 0 থেকে 10 এর স্কেলে।
আপনি ডেটাসেট ডাউনলোড করতে পারেন
from keras.datasets import wine_quality (X_train, y_train), (X_test, y_test) = wine_quality.load_data(test_split=0.2, seed=113) 8.
রয়টার্স নিউজওয়্যার ডেটাসেট হল মূল রয়টার্স ডেটাসেটের একটি প্রাক-প্রসেসড সংস্করণ, যেখানে পাঠ্যটি পূর্ণসংখ্যার ক্রম হিসাবে এনকোড করা হয়েছে। এটি 30,979 শব্দের শব্দভান্ডার সহ 11,228 টি সংবাদ নিবন্ধ নিয়ে গঠিত।
প্রতিটি নিবন্ধকে 46টি ভিন্ন বিষয়ের মধ্যে একটিতে শ্রেণীবদ্ধ করা হয়েছে যেমন "ভুট্টা", "অশোধিত", "আয়" এবং "অধিগ্রহণ"।
আপনি থেকে ডেটাসেট ডাউনলোড করতে পারেন
tf.keras.datasets.reuters.load_data(path="reuters.npz",num_words=None,skip_top=0, maxlen=None,test_split=0.2,seed=113,start_char=1,oov_char=2,index_from=3,**kwargs) 9.
এই ডেটাসেটে পিমা ভারতীয় মহিলাদের সম্পর্কে মেডিকেল ডেটা রয়েছে, যেমন বয়স, গর্ভধারণের সংখ্যা, গ্লুকোজের মাত্রা, রক্তচাপ, ত্বকের পুরুত্ব, BMI এবং ইনসুলিনের মাত্রা। পিমা ইন্ডিয়ানস ডায়াবেটিস ডেটাসেটের কেরাস সংস্করণে 8টি ইনপুট ভেরিয়েবল এবং 1টি আউটপুট ভেরিয়েবল সহ 768টি নমুনা রয়েছে।
পিমা ইন্ডিয়ানস ডায়াবেটিস ডেটাসেট ডাউনলোড করা যেতে পারে
from tensorflow.keras.datasets import pima_indians_diabetes (x_train, y_train), (x_test, y_test) = pima_indians_diabetes.load_data() 10.
কুকুর বনাম বিড়াল ডেটাসেটে কুকুর এবং বিড়ালের 25,000টি লেবেলযুক্ত চিত্র রয়েছে, প্রতিটি শ্রেণীর 12,500টি চিত্র রয়েছে। এই চিত্রগুলি বিভিন্ন মাপ এবং গুণমান সহ বিভিন্ন উত্স থেকে সংগ্রহ করা হয়েছিল।
আপনি থেকে ডেটাসেট ডাউনলোড করতে পারেন
# Import the necessary Keras libraries: from keras.preprocessing.image import ImageDataGenerator # Set the paths to the training and validation directories: train_dir = 'path/to/train' validation_dir = 'path/to/validation' # Define an ImageDataGenerator object to perform data augmentation and normalization: train_datagen = ImageDataGenerator(rescale=1./255, rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True) # Use flow_from_directory to load directory data in Keras: validation_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory(train_dir, target_size=(150, 150), batch_size=32, class_mode='binary') validation_generator = validation_datagen.flow_from_directory(validation_dir, target_size=(150, 150), batch_size=32, class_mode='binary') # The flow_from_directory yields preprocessed image batches and labels as DirectoryIterator.
উল্লেখ্য যে উপরের কোডে, আমরা অতিরিক্ত ফিটিং প্রতিরোধে সাহায্য করার জন্য প্রশিক্ষণের চিত্রগুলির বৈচিত্র তৈরি করতে ডেটা বৃদ্ধি ব্যবহার করছি। বৈধতা তথ্য বর্ধিত হয় না.
কেরাস ডেটাসেটের জন্য সাধারণ ব্যবহারের ক্ষেত্রে
সর্বশেষ ভাবনা
কেরাস ডেটাসেটগুলি মেশিন লার্নিং অনুশীলনকারীদের এবং গবেষকদের জন্য একটি মূল্যবান সংস্থান, যা ডেটা সংগ্রহ এবং প্রিপ্রসেসিংয়ে সময় এবং শ্রম সাশ্রয় করতে পারে, মডেল বিকাশ এবং পরীক্ষা-নিরীক্ষার উপর আরও ফোকাস করার অনুমতি দেয়।
এই কেরাস ডেটাসেটগুলি যে কেউ ডাউনলোড করতে এবং অবাধে ব্যবহার করতে পারে।
আরও ডেটাসেট তালিকা:
L O A D I N G
. . . comments & more!
. . . comments & more!



