













































Jan 01, 1970
LLM ナレッジ グラフをマスターする: わずか 5 分で GraphRAG を構築して実装する に@neo4j
新しい歴史
LLM ナレッジ グラフをマスターする: わずか 5 分で GraphRAG を構築して実装する
に Neo4j7m2024/10/18
長すぎる; 読むには
Neo4j LLM ナレッジ グラフ ビルダーは、非構造化テキストをナレッジ グラフに変換する革新的なアプリケーションです。ML モデル (LLM: OpenAI、Gemini、Diffbot) を使用して、PDF、Web ページ、YouTube 動画を変換します。この機能は、ナレッジ グラフ自体と会話するのと同じように、データと直感的にやり取りできるため、特に魅力的です。
Neo4j LLM ナレッジグラフ ビルダーとは何ですか?
Neo4j コードや Cypher を动用せずに非構造化テキストをナレッジ グラフに変換し、魔幻のようなテキストからグラフへのエクスペリエンスを具备する振兴的なオンライン アプリケーションです。ML モデル (LLM: OpenAI、Gemini、Diffbot) を动用して、PDF、Web ページ、YouTube ビデオをエンティティとその関係のナレッジ グラフに変換します。
アプリケーションは、次の 4 つの簡単な手順でシームレスなエクスペリエンスを提供します。
- データ取り込み - PDF ドキュメント、Wikipedia ページ、YouTube ビデオなど、さまざまなデータ ソースをサポートします。
- エンティティ認識 - LLM を使用して、非構造化テキストからエンティティと関係を識別および抽出します。
- グラフ構築 - Neo4j のグラフ機能を使用して、認識されたエンティティと関係をグラフ形式に変換します。
- ユーザー インターフェイス -ユーザーがアプリケーションと対話するための直感的な Web インターフェイスを提供し、データ ソースのアップロード、生成されたグラフの視覚化、RAG エージェントとの対話を容易にします。この機能は、ナレッジ グラフ自体と会話するのと同じように、データと直感的に対話できるため、特に魅力的です。技術的な知識は必要ありません。
試してみましょう
当社では、クレジットカードや LLM キーを重要性とせず、 でアプリケーションを提供数据しており、摩擦力がありません。あるいは、ローカルまたは環东南部で実行するには、パブリックにアクセスし、この论文投稿で説明する手順に従ってください。
- //console.neo4j.ioでログインするか、アカウントを作成してください。
- 「インスタンス」で、新しい AuraDB 無料データベースを作成します。
- 資格情報ファイルをダウンロードします。
- インスタンスが実行されるまで待ちます。
Neo4j データベースが実行され、資格情報が取得できたので、LLM Knowledge Graph Builder を開き、右上隅の「Neo4j に接続」をクリックします。
十年前にダウンロードした資格情報ファイルを接続ダイアログにドロップします。すべての情報が自動的に入力されます。または、すべてを手動で入力することもできます。
ナレッジグラフの作成
このプロセスは、非構造化データの取り込みから始まり、その後、LLM に渡されて注意なエンティティとその関係が識別されます。
今必要なのは、使用するモデルを選択し、 「グラフの生成」をクリックすることだけです。あとは魔法に任せてください。
ファイル選択のみを生成する場合は、最初にファイルを選択し(テーブルの最初の列のチェックボックスを使用)、グラフの生成をクリックします。
⚠️定義済みまたは独自のグラフ スキーマを使用する場合は、右上隅の設定アイコンをクリックしてドロップダウンから定義済みスキーマを選択するか、ノード ラベルと関係を書き留めて独自のスキーマを使用するか、既存の Neo4j データベースから既存のスキーマを取得するか、テキストをコピー/貼り付けして LLM に分析させてスキーマの提案を依頼することができます。
- コンテンツはチャンクに分割されます。
- チャンクはグラフに保存され、ドキュメント ノードに接続され、高度な RAG パターンのためにチャンク同士が接続されます。
- 非常に類似したチャンクは SIMILAR 関係で接続され、K 近傍グラフを形成します。
- 埋め込みは計算され、チャンクとベクトル インデックスに格納されます。
- llm-graph-transformer または diffbot-graph-transformer を使用して、テキストからエンティティと関係を抽出します。
- エンティティはグラフに格納され、元のチャンクに接続されます。
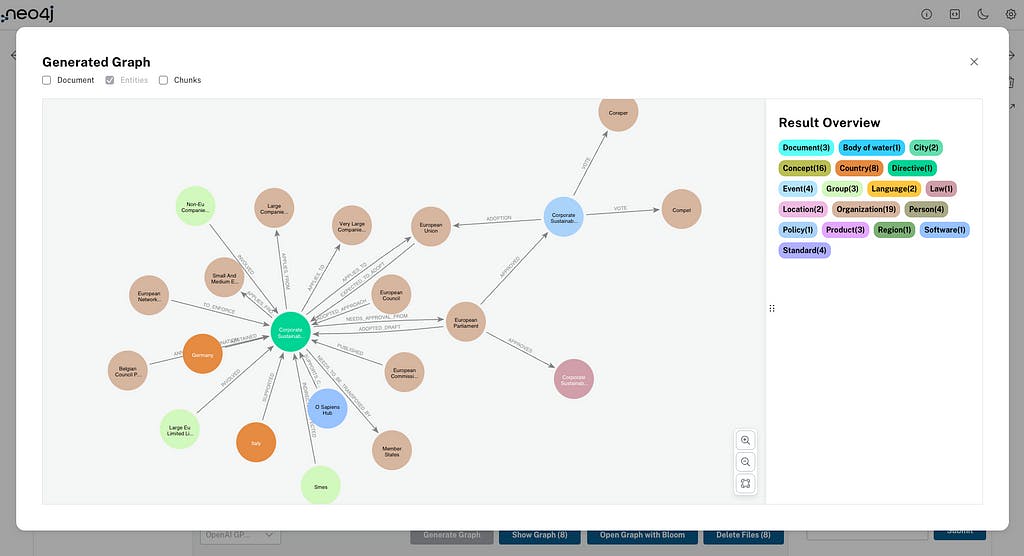
ナレッジグラフを探索する
ドキュメントから腾出された情報はグラフ状态に構造化され、エンティティはノードになり、関係はこれらのノードを接続するエッジになります。Neo4j を用到する利点は、これらの複雑なデータ ネットワークを効率的に导出およびクエリできるため、合成されたナレッジ グラフがさまざまなアプリケーションですぐに役立つことです。
RAG エージェントを使用してデータについて質問する前に、チェックボックスを使用して 1 つのドキュメント (または複数のドキュメント) を選択し、 [グラフの表示] をクリックします。これにより、選択したドキュメントに対して作成されたエンティティが表示されます。また、そのビューにドキュメント ノードとチャンク ノードを表示することもできます。
「Bloom でグラフを開く」ボタンをクリックすると、 が開き、新しく作成したナレッジ グラフを視覚化してナビゲートできるようになります。次のアクション「ファイルの削除」では、選択したドキュメントとチャンクがグラフから削除されます (オプションで選択した場合はエンティティも削除されます)。
あなたの知識と話す
さて、最後の部位、右側のパネルに标识される RAG エージェントです。検索プロセス — どのように機能しますか?
下の用户画像は、GraphRAG プロセスの簡略化されたビューを示しています。
さまざまな入力とソース (質問、ベクター結果、チャット履歴) はすべて、カスタム プロンプトで選択された LLM モデルに送信され、提供された要素とコンテキストに基づいて、質問に対する応答を提供してフォーマットするように求められます。もちろん、プロンプトには、フォーマット、ソースの引用の要求、回答が不明な場合は推測しないなど、さらに多くの魔法があります。完全なプロンプトと手順は、 のFINAL_PROMPTにあります。
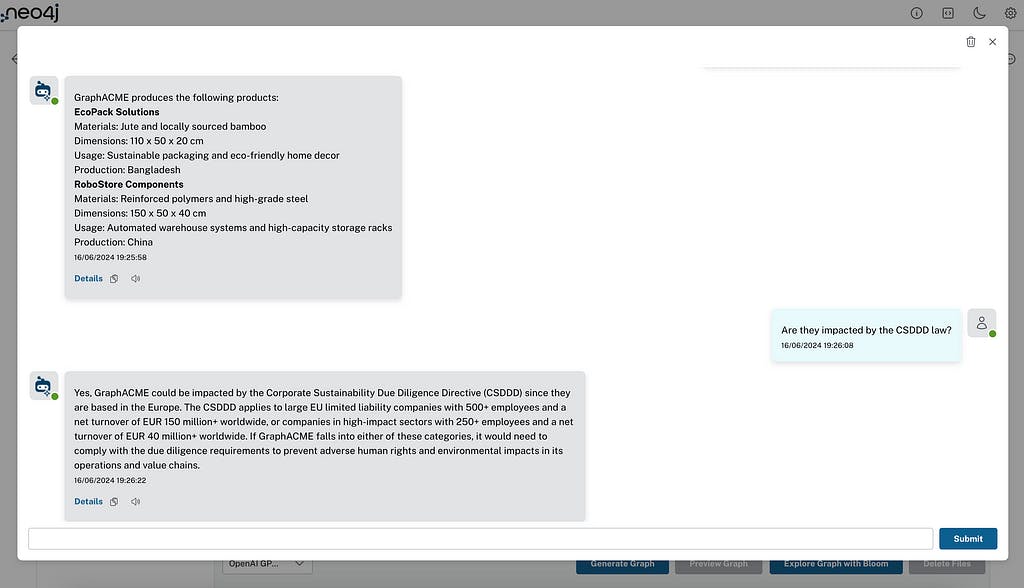
データに関連する質問をする
この例では、GraphACME (ヨーロッパに拠点を置く) という空架の会社に関する企业内部文書を読み込み、サプライチェーン戦略と製品群体を弄成して文書化しました。また、新しい CSDDD、その影響、規制について説明したプレス記事と YouTube 動画も読み込みました。これで、チャットボットに社内 (空架の) 会社に関する知識について質問できるようになりました。CSDDD 法に関する質問や、GraphACME が製造する製品のリスト、それらが CSDDD 規制の影響を受けるかどうか、影響を受ける場合は会社にどのような影響があるかなど、両方に関する質問もできます。
チャット機能
ホーム页面の右側には、チャット ウィンドウに 3 つのボタンが付いています。
- 「閉じる」を選択すると、チャットボット インターフェースが閉じます。
- チャット履歴を消去すると、現在のセッションのチャット履歴が削除されます。
- ウィンドウを最大化すると、チャットボット インターフェースが全画面モードで開きます。
- 詳細では、 RAG エージェントがソース (ドキュメント)、チャンク、エンティティを収集および使用した方法を示す取得情報ポップアップが開きます。使用されたモデルとトークンの消費に関する情報も含まれます。
- 「コピー」は、応答の内容をクリップボードにコピーします。
- テキスト読み上げ機能により、応答内容が読み上げられます。
まとめ
LLM Knowledge Graph Builder についてさらに詳しく知るには、 ソース コードやドキュメントなどの豊富な情報を按照してください。さらに、開始方式に関する詳細なガイダンスが带来されており、 、合理利用机会なより幅広いツールやアプリケーションに関する詳細な情報を带来しています。次は何か — 貢献と拡張機能
LLM Knowledge Graph Builder でのあなたの経験は、是非常に貴重です。バグに饱受したり、新機能の建议があったり、貢献したい場合、または不同の機能強化を愿意する場合は、コミュニティ プラットフォームがあなたの考えを共设するのに最適な場所です。コーディングに掌握している方にとって、GitHub に直接的貢献することは、プロジェクトの発展に役立つやりがいのある技巧です。あなたの意見や貢献は、ツールの解决に役立つだけでなく、協力的で勇于创新的なコミュニティの育成にも役立ちます。リソース
GenAI アプリケーションの新しいリソースの詳細: 。これらのオープンソース ツールを运用すると、ナレッジ グラフに基づいた GenAI アプリケーションを簡単に開始でき、応答の品質と説明必要条件を向左させ、アプリの開発と導入を高速度できます。ビデオ
リンク
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
関連ストーリー
AI の力を解き放つ。最先端技術の体系的レビュー: 概要と序論
#ai


ユニークなエコシステムを支えるビットコインUTXOのモデル #bitcoin-utxo
Jan 01, 1970

