


































Jan 01, 1970
Como desenvolver aplicativos de IA baseados em dados: um guia para criar serviços de IA diretamente do banco de dados por@paulparkinson
1,792 leituras
Como desenvolver aplicativos de IA baseados em dados: um guia para criar serviços de IA diretamente do banco de dados
por Paul Parkinson9m2024/01/07
Muito longo; Para ler
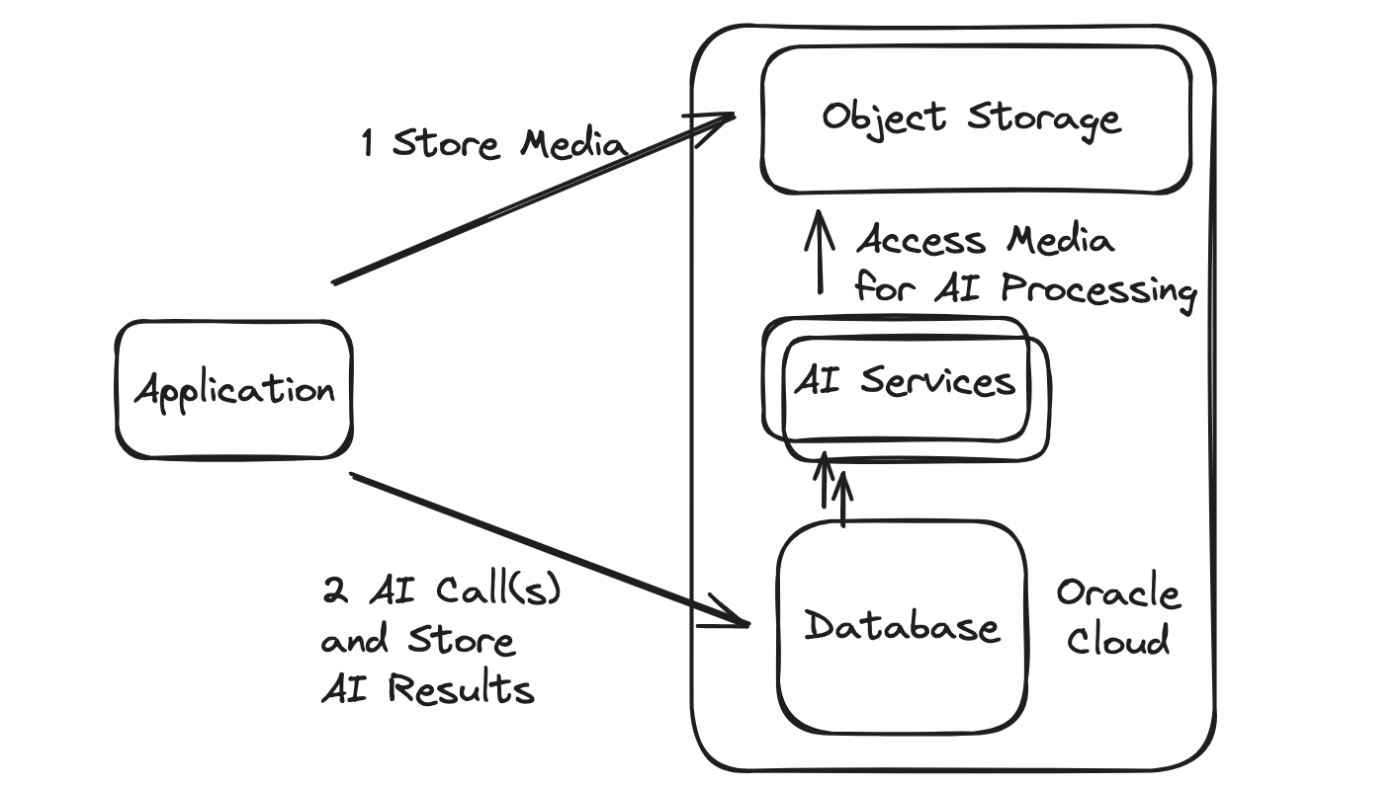
Este blog descreve uma abordagem otimizada para arquitetura de aplicativos de IA orientada por dados, onde as chamadas de IA são feitas diretamente do banco de dados vetorial Oracle.À medida que os serviços de IA e os dados que eles consomem e criam se tornam mais importantes e predominantes em vários aplicativos e processos, o mesmo acontece com as plataformas e arquiteturas nas quais são construídos. Como de costume, não existe um “tamanho único”, no entanto, o que é brevemente apresentado aqui é uma abordagem otimizada para essas arquiteturas de aplicativos de IA orientadas por dados.
Quando as chamadas são feitas a partir do próprio banco de dados, ela fornece uma arquitetura otimizada com vários benefícios, incluindo:
- Chamadas de rede reduzidas, reduzindo assim a latência.
- Chamadas de rede reduzidas, aumentando assim a confiabilidade.
- Operações transacionais (ACID) em IA e outros dados (e até mesmo mensagens ao usar TxEventQ) que evitam a necessidade de lógica de processamento idempotente/duplicada, etc., e os recursos desperdiçados relacionados.
- A otimização do processamento se deve à localidade dos dados, sejam eles armazenados diretamente no banco de dados, em um armazenamento de objetos ou em outra fonte. Isso ocorre porque o banco de dados Oracle fornece um front-end funcional robusto para buckets de armazenamento de objetos, que de outra forma seriam estúpidos, e o banco de dados oferece muitas opções para sincronizar ou operar de maneira ideal em dados existentes no armazenamento de objetos e em outras fontes de dados.
- Segurança aprimorada devido a um mecanismo de autenticação comum e reutilização de um banco de dados robusto e de uma infraestrutura de segurança em nuvem famosa.
- Configuração geral reduzida, pois as chamadas são feitas de um local central. O ponto de entrada para o próprio banco de dados pode ser exposto como um endpoint Rest (usando ORDS) com um único clique e, claro, drivers em vários idiomas também podem ser usados para acessar o banco de dados.
- Vantagens do banco de dados vetorial. Este tópico é um blog em si, e lançarei como continuação, especialmente porque a Oracle tem e está adicionando vários recursos poderosos nesta área.
- Aprendizado de máquina de banco de dados Oracle. Além de vários serviços de IA, o próprio banco de dados Oracle conta com um mecanismo de aprendizado de máquina há muitos anos. OML agiliza o ciclo de vida do ML, oferecendo ferramentas escalonáveis de SQL, R, Python, REST, AutoML e sem código com mais de 30 algoritmos no banco de dados, melhorando a sincronização e a segurança dos dados ao processar dados diretamente no banco de dados.
- Banco de dados autônomo Oracle. Selecione AI, que permite consultar dados usando linguagem natural e gerar SQL específico para seu banco de dados.
- Banco de dados autônomo Oracle. AI Vector Search, que inclui um novo tipo de dados vetoriais, índices vetoriais e operadores SQL de pesquisa vetorial, permite que o Oracle Database armazene o conteúdo semântico de documentos, imagens e outros dados não estruturados como vetores e use-os para executar consultas rápidas de similaridade .
Esses novos recursos também suportam RAG (Retrieval Augmented Generation), que fornece maior precisão e evita a exposição de dados privados, incluindo-os nos dados de treinamento do LLM.
Novamente, existem muitos fluxos e requisitos diferentes de aplicação de IA, mas uma comparação básica das duas abordagens pode ser visualizada da seguinte maneira:
O código
É possível rodar diversas linguagens diferentes no banco de dados, possibilitando ali realizar diversas lógicas de aplicação. Isso inclui Java, JavaScript e PL/SQL. Exemplos de PL/SQL são fornecidos aqui e podem ser executados na página Database Actions -> SQL no console do OCI, na ferramenta de linha de comando SQLcl (que está pré-instalada no OCI Cloud Shell ou pode ser baixada), em SQLDeveloper, VS Code (onde a Oracle possui um plugin conveniente), etc.
BEGIN dbms_cloud.create_credential ( credential_name => 'OCI_KEY_CRED', user_ocid => 'ocid1.user.oc1..[youruserocid]', tenancy_ocid => 'ocid1.tenancy.oc1..[yourtenancyocid]', private_key => '[yourprivatekey - you can read this from file or put the contents of your pem without header, footer, and line wraps]' fingerprint => '[7f:yourfingerprint]' ); END;
CREATE TABLE aivision_results (id RAW (16) NOT NULL, date_loaded TIMESTAMP WITH TIME ZONE, label varchar2(20), textfromai varchar2(32767), jsondata CLOB CONSTRAINT ensure_aivision_results_json CHECK (jsondata IS JSON)); /
E agora, a função simples que tipifica o coração da arquitetura… Aqui, vemos uma chamada para DBMS_CLOUD.send_request com a credencial que criamos e a URL do endpoint de operação de serviço (AI) (a operação analyzeImage do serviço Oracle Vision AI nesse caso).
CREATE OR REPLACE FUNCTION VISIONAI_TEXTDETECTION ( p_endpoint VARCHAR2, p_compartment_ocid VARCHAR2, p_namespaceName VARCHAR2, p_bucketName VARCHAR2, p_objectName VARCHAR2, p_featureType VARCHAR2, p_label VARCHAR2 ) RETURN VARCHAR2 IS resp DBMS_CLOUD_TYPES.resp; json_response CLOB; v_textfromai VARCHAR2(32767); BEGIN resp := DBMS_CLOUD.send_request( credential_name => 'OCI_KEY_CRED', uri => p_endpoint || '/20220125/actions/analyzeImage', method => 'POST', body => UTL_RAW.cast_to_raw( JSON_OBJECT( 'features' VALUE JSON_ARRAY( JSON_OBJECT('featureType' VALUE p_featureType) ), 'image' VALUE JSON_OBJECT( 'source' VALUE 'OBJECT_STORAGE', 'namespaceName' VALUE p_namespaceName, 'bucketName' VALUE p_bucketName, 'objectName' VALUE p_objectName ), 'compartmentId' VALUE p_compartment_ocid ) ) ); json_response := DBMS_CLOUD.get_response_text(resp); SELECT LISTAGG(text, ', ') WITHIN GROUP (ORDER BY ROWNUM) INTO v_textfromai FROM JSON_TABLE(json_response, '$.imageText.words[*]' COLUMNS ( text VARCHAR2(100) PATH '$.text' ) ); INSERT INTO aivision_results (id, date_loaded, label, textfromai, jsondata) VALUES (SYS_GUID(), SYSTIMESTAMP, p_label, v_textfromai, json_response); RETURN v_textfromai; EXCEPTION WHEN OTHERS THEN RAISE; END VISIONAI_TEXTDETECTION; /
BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_OBJECTDETECTION', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_OBJECTDETECTION', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /Análise e pesquisa de texto de resultados de IA
Essa arquitetura também torna a análise e a pesquisa de texto de todos os resultados de IA convenientes e eficientes. A partir daqui, mais processamento e análise podem ocorrer. Vamos dar uma olhada em três declarações que nos fornecerão uma pesquisa de texto fácil de usar de nossos resultados de IA.
- Primeiro, criamos um índice para pesquisas de texto em nossa tabela aivision_results .
- Em seguida, criamos uma função que procura uma determinada string usando a poderosa funcionalidade contains , ou podemos usar adicionalmente/opcionalmente o pacote DBMS_SEARCH para pesquisar várias tabelas e retornar o refcursor dos resultados.
- Finalmente, expomos a função como um endpoint Rest.
create index aivisionresultsindex on aivision_results(textfromai) indextype is ctxsys.context; / CREATE OR REPLACE FUNCTION VISIONAI_RESULTS_TEXT_SEARCH(p_sql IN VARCHAR2) RETURN SYS_REFCURSOR AS refcursor SYS_REFCURSOR; BEGIN OPEN refcursor FOR select textfromai from AIVISION_RESULTS where contains ( textfromai, p_sql ) > 0; RETURN refcursor; END VISIONAI_RESULTS_TEXT_SEARCH; / BEGIN ORDS.ENABLE_OBJECT( P_ENABLED => TRUE, P_SCHEMA => 'AIUSER', P_OBJECT => 'VISIONAI_RESULTS_TEXT_SEARCH', P_OBJECT_TYPE => 'FUNCTION', P_OBJECT_ALIAS => 'VISIONAI_RESULTS_TEXT_SEARCH', P_AUTO_REST_AUTH => FALSE ); COMMIT; END; /Para concluir…
Este foi um blog rápido mostrando um padrão de arquitetura para o desenvolvimento de aplicativos de IA baseados em dados, fazendo chamadas para serviços de IA diretamente do banco de dados.
Também publicado
L O A D I N G
. . . comments & more!
. . . comments & more!



