











































































Jan 01, 1970
ምህናጽ ፍልጠት ግራፍ ንRAG: ምድህሳስ GraphRAG ብ Neo4jን LangChainን። ብ@neo4j
ሓድሽ ታሪኽ
ምህናጽ ፍልጠት ግራፍ ንRAG: ምድህሳስ GraphRAG ብ Neo4jን LangChainን።
ብ Neo4j32m2024/10/22
ኣዝዩ ነዊሕ፤ ንምንባብ
እዚ ጽሑፍ እዚ Neo4jን LangChainን ብምጥቃም ኣተገባብራ "ካብ ከባብያዊ ናብ ዓለማዊ" GraphRAG ሻምብቆ ዝድህስስ እዩ። ካብ ጽሑፍ ናይ ፍልጠት ግራፍ ምህናጽ፡ ዓበይቲ ቋንቋ ሞዴላት (LLMs) ብምጥቃም ማሕበረሰባት ኣካላት ምጽማቕ፡ ከምኡ’ውን ግራፍ ኣልጎሪዝም ምስ LLM ዝተመርኮሰ ምድማር ብምውህሃድ ትኽክለኛነት ሪትሪቫል-ኣግመንትድ ጀነሬሽን (RAG) ምዕባይ ዝሽፍን እዩ። እቲ ኣገባብ ካብ ብዙሓት ምንጭታት ዝመጽእ ሓበሬታ ናብ ዝተዋደደ ግራፍ ብምሕጻር ጽማቕ ተፈጥሮኣዊ ቋንቋታት ብምፍጣር ንዝተሓላለኸ ሓበሬታ ንምርካብ ውጽኢታዊ ኣገባብ የቕርብ።
ስጉምትታት ኣብ መስመር — ምስሊ ካብ , ፍቓድ ኣብ ትሕቲ CC BY 4.0
ኢንዴክስ — ምፍጣር ግራፍ
- ምንጪ ሰነዳት ናብ ቁንጣሮ ጽሑፍ : ምንጪ ሰነዳት ንመስርሕ ኣብ ንኣሽቱ ቁንጣሮ ጽሑፍ ይምቀሉ።
- Text Chunks to Element Instances : ነፍሲ ወከፍ ጽሑፍ ቁንጣሮ ኣካላትን ዝምድናታትን ንምውጻእ ይትንተን፣ ነዞም ባእታታት ዝውክሉ ዝርዝር ቱፕላት የፍሪ።
- Element Instances to Element Summaries : ዝተቐድሑ ኣካላትን ዝምድናታትን ብLLM ናብ ገላጺ ጽሑፍ ብሎክ ንነፍሲ ወከፍ ባእታ ይድምደሙ።
- ጽማቕ ባእታታት ናብ ማሕበረሰባት ግራፍ : እዞም ጽማቕ ኣካላት ግራፍ ይፈጥሩ፣ ድሕሪኡ ከም ዝኣመሰሉ ኣልጎሪዝማት ንመሰረታዊ ኣቃውማ ተጠቒሞም ናብ ማሕበረሰባት ይምቀሉ።
- ግራፍ ማሕበረሰባት ናብ ማሕበረሰብ ጽማቕ : ጽማቕ ናይ ነፍሲ ወከፍ ማሕበረሰብ ምስ LLM ይፍጠር ነቲ ዳታሴት ዓለማዊ እዋናዊ ኣቃውማን ትርጉሙን ንምርዳእ እዩ።
ምውሳድ — ምምላስ
- ጽማቕ ማሕበረሰብ ናብ ዓለማዊ መልስታት : ጽማቕ ማሕበረሰብ ንሓደ ናይ ተጠቃሚ ሕቶ ንምምላስ ማእከላይ መልስታት ብምፍጣር ይጥቀሙ፣ ድሕሪኡ ናብ ናይ መወዳእታ ዓለማዊ መልሲ ይእከቡ።
ምድላው ናይ Neo4j ሃዋህው
Neo4j ከም መሰረታዊ ግራፍ ስቶር ክንጥቀመሉ ኢና። እቲ ዝቐለለ መንገዲ ንምጅማር ነጻ ምሳሌ ናይ ምጥቃም እዩ፣ እዚ ድማ ናይ Neo4j ዳታቤዝ ናይ ደበና ምሳሌታት ምስ ግራፍ ዳታ ሳይንስ ፕላግ-ኢን ተተኺሉ የቕርብ። ከም ኣማራጺ፡ ነቲ መተግበሪ ብምውራድን ሎካል ዳታቤዝ ኢንስታንስ ብምፍጣርን፡ ናይ Neo4j ዳታቤዝ ሎካል ኢንስታንስ ከተቕውም ትኽእል። ሎካል ቨርዥን ትጥቀም እንተኾንካ፡ ክልቲኦም APOCን GDSን ፕላጊናት ምጽዓንካ ኣረጋግጽ። ንናይ ምፍራይ ኣወዳድባታት፡ ነቲ ዝኽፈል፡ ዝመሓደር AuraDS (Data Science) instance ክትጥቀም ትኽእል ኢኻ፡ እዚ ድማ ነቲ GDS ፕላግ-ኢን ይህብ።
from langchain_community.graphs import Neo4jGraph os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687" os.environ["NEO4J_USERNAME"] = "neo4j" os.environ["NEO4J_PASSWORD"] = "mast-codes-trails" graph = Neo4jGraph(refresh_schema=False)ዳታሴት።
ቅድሚ ገለ ግዜ ናይ ዲፍቦት ኤፒኣይ ተጠቒመ ዝፈጠርክዎ ናይ ዜና ጽሑፍ ዳታሴት ክንጥቀም ኢና። ንቐሊል ዳግመ-ምጥቃም ኣብ GitHub ሰቒለዮ ኣለኹ፤
news = pd.read_csv( "//raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv" ) news["tokens"] = [ num_tokens_from_string(f"{row['title']} {row['text']}") for i, row in news.iterrows() ] news.head()
ጽሑፍ ምጭብባጥ
እቲ ናይ ጽሑፍ ምክፍፋል ስጉምቲ ወሳኒ ኮይኑ፡ ንውጽኢት ንታሕቲ ዝወርድ ውጽኢት ብዓቢኡ ጽልዋ ኣለዎ። እቶም ጸሓፍቲ ናይቲ ጽሑፍ፡ ንኣሽቱ ቁንጣሮ ጽሑፋት ምጥቃም፡ ብሓፈሻ ዝያዳ ኣካላት ምውጻእ ከም ዘምጽእ ረኺቦም።
ብዝሒ ናይ ቅብኣ ኣካላት ብዓቐን ናይ ጽሑፍ ቁንጣሮ ተዋሂቡ — ምስሊ ካብ , ፍቓድ ኣብ ትሕቲ CC BY 4.0
sns.histplot(news["tokens"], kde=False) plt.title('Distribution of chunk sizes') plt.xlabel('Token count') plt.ylabel('Frequency') plt.show()
ምውጻእ ኖድታትን ዝምድናታትን
እቲ ዝቕጽል ስጉምቲ ካብ ቁንጣሮ ጽሑፋት ፍልጠት ምህናጽ እዩ። ነዚ ናይ ኣጠቓቕማ ጉዳይ፡ ካብቲ ጽሑፍ ብመልክዕ መስመራትን ዝምድናታትን ዝተዋደደ ሓበሬታ ንምውጻእ LLM ንጥቀም። ኣብቲ ወረቐት ዝተጠቕሙ ጸሓፍቲ ነቲ ክትምርምሮ ትኽእል ኢኻ። ኣድላዪ እንተኾይኑ ንናይ መስመር ስያመታት ኣቐዲምና ክንገልጸሉ እንኽእል LLM ምልክታት ኣለዎም፣ ግን ብነባሪ፣ እዚ ኣማራጺ እዩ። ብተወሳኺ ኣብቲ መበቆላዊ ሰነድ ዝተቐድሑ ዝምድናታት ብሓቂ ዓይነት የብሎምን መግለጺ ጥራይ። ናይዚ ምርጫ ምኽንያት፡ LLM ዝሃብተመን ዝያዳ ንኡስ ሓበሬታ ከም ዝምድናታት ከውጽእን ክዕቅብን ምፍቃድ ምዃኑ እግምት። ግን ጽሩይ ናይ ፍልጠት ግራፍ ምስ ዝኾነ ዝምድና-ዓይነት ስፔሲፊኬሽን ክህልወካ ኣጸጋሚ እዩ (እቶም መግለጺታት ናብ ሓደ ንብረት ክኣትዉ ይኽእሉ እዮም)።
from langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAI llm = ChatOpenAI(temperature=0, model_name="gpt-4o") llm_transformer = LLMGraphTransformer( llm=llm, node_properties=["description"], relationship_properties=["description"] ) def process_text(text: str) -> List[GraphDocument]: doc = Document(page_content=text) return llm_transformer.convert_to_graph_documents([doc])
ኣብዚ ኣብነት ንግራፍ ምውጻእ GPT-4o ንጥቀም። እቶም ጸሓፍቲ ብፍላይ ንኤልኤልኤም መምርሒ ይህቡ ። ምስ ኣተገባብራ LangChain፡ እቶም node_properties ን relationship_properties ባህርያትን ተጠቒምካ፡ ኣየኖት ናይ መስመር ወይ ዝምድና ባህርያት LLM ከውጽእ ከም እትደሊ ክትገልጽ ትኽእል።
እቲ ፍልልይ ምስ ኣተገባብራ LLMGraphTransformer ኩሎም ናይ መስመር ወይ ዝምድና ባህርያት ኣማራጺ ስለዝኾኑ ኩሎም መስመራት ናይቲ description ባህሪ ኣይክህልዎምን እዩ። እንተደሊና ግዴታዊ description ንብረት ንኽህልዎ ብሕታዊ ምውጻእ ክንገልጾ ንኽእል ኢና፡ ኣብዚ ኣተገባብራ ግን ነዚ ክንዝልፎ ኢና።
MAX_WORKERS = 10 NUM_ARTICLES = 2000 graph_documents = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(process_text, f"{row['title']} {row['text']}") for i, row in news.head(NUM_ARTICLES).iterrows() ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): graph_document = future.result() graph_documents.extend(graph_document) graph.add_graph_documents( graph_documents, baseEntityLabel=True, include_source=True )
entity_dist = graph.query( """ MATCH (d:Document) RETURN d.text AS text, count {(d)-[:MENTIONS]->()} AS entity_count """ ) entity_dist_df = pd.DataFrame.from_records(entity_dist) entity_dist_df["token_count"] = [ num_tokens_from_string(str(el)) for el in entity_dist_df["text"] ] # Scatter plot with regression line sns.lmplot( x="token_count", y="entity_count", data=entity_dist_df, line_kws={"color": "red"} ) plt.title("Entity Count vs Token Count Distribution") plt.xlabel("Token Count") plt.ylabel("Entity Count") plt.show()
degree_dist = graph.query( """ MATCH (e:__Entity__) RETURN count {(e)-[:!MENTIONS]-()} AS node_degree """ ) degree_dist_df = pd.DataFrame.from_records(degree_dist) # Calculate mean and median mean_degree = np.mean(degree_dist_df['node_degree']) percentiles = np.percentile(degree_dist_df['node_degree'], [25, 50, 75, 90]) # Create a histogram with a logarithmic scale plt.figure(figsize=(12, 6)) sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue') # Use a logarithmic scale for the x-axis plt.yscale('log') # Adding labels and title plt.xlabel('Node Degree') plt.ylabel('Count (log scale)') plt.title('Node Degree Distribution') # Add mean, median, and percentile lines plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}') plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}') plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}') plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}') plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}') # Add legend plt.legend() # Show the plot plt.show()
graph.query(""" MATCH (n:`__Entity__`) RETURN "node" AS type, count(*) AS total_count, count(n.description) AS non_null_descriptions UNION ALL MATCH (n)-[r:!MENTIONS]->() RETURN "relationship" AS type, count(*) AS total_count, count(r.description) AS non_null_descriptions """)
ኣስተውዕል ብሰንኪ ናይ LLMs ተኽእሎኣዊ ባህሪ፡ እቶም ቁጽርታት ኣብ ዝተፈላለየ ጉያታትን ዝተፈላለየ ምንጪ ዳታ፡ LLMsን ምልዕዓልን ክፈላለዩ ይኽእሉ።
ውሳነ ኣካል
ምፍታሕ ኣካል (de-duplication) ናይ ፍልጠት ግራፍ ኣብ ዝህነጸሉ እዋን ወሳኒ እዩ ምኽንያቱ ነፍሲ ወከፍ ኣካል ብፍሉይን ብትኽክልን ከምዝውከል ስለዘረጋግጽ፣ ንሓደ ዓይነት ናይ ሓቂ ዓለም ኣካል ዝውክሉ መዛግብቲ ምድግጋምን ምውህሃድን ይከላኸል። እዚ መስርሕ እዚ ኣብ ውሽጢ ግራፍ ምሉእነትን ቅኑዕነትን ዳታ ንምዕቃብ ኣገዳሲ እዩ። ብዘይ ናይ ኣካል ፍታሕ፡ ግራፍ ፍልጠት ብዝተበታተነን ዘይተሰማማዕን ዳታ ምተሳቐየ፡ እዚ ድማ ናብ ጌጋታትን ዘይተኣማመን ርድኢታትን ምመርሐ።
ቅድሚ/ድሕሪ ምጥቃም ኣካል ውሳነ ኣብ ባሕሪ ምፍሳስ ዳታ ንምትእስሳር — ምስሊ ካብ
ብሓፈሻ፡ ፍታሕ ኣካል ንብቕዓት ምእካብን ምውህሃድን ዳታ ብምዕባይ፡ ኣብ ዝተፈላለዩ ምንጭታት ንዝህሉ ሓበሬታ ውሁድ ኣረኣእያ ይህብ። ኣብ መወዳእታ ኣብ ዘተኣማምንን ምሉእን ናይ ፍልጠት ግራፍ ዝተመርኮሰ ዝያዳ ውጽኢታዊ ዝኾነ ሕቶ-ምምላስ የኽእል።
- ኣብ ግራፍ ዘለዉ ኣካላት — ካብ ኩሎም ኣብ ውሽጢ ግራፍ ዘለዉ ኣካላት ጀምር።
- K-nearest graph — ኣብ ጽሑፍ ምትእትታው ተመርኲስካ ተመሳሰልቲ ኣካላት ብምትእስሳር፡ k-nearest neighbor graph ምህናጽ።
- ድኹም ምትእስሳር ዘለዎም ኣካላት — ኣብቲ k-ዝቐረበ ግራፍ ድኹም ምትእስሳር ዘለዎም ኣካላት ምልላይ፣ ተመሳሳሊ ክኾኑ ዝኽእሉ ኣካላት ምጉጅጃል። እዞም ባእታታት ምስ ተለለዩ ናይ ቃላት ርሕቀት ምፍታሕ ስጉምቲ ወስኹ።
- LLM ገምጋም — ነዞም ኣካላት ንምግምጋምን ኣብ ውሽጢ ነፍሲ ወከፍ ክፍሊ ዝርከቡ ኣካላት ክውሃሃዱ ኣለዎም ድዩ ኣይግባእን ንምውሳን LLM ተጠቐም፣ ውጽኢቱ ድማ ናይ መወዳእታ ውሳነ ኣብ ፍታሕ ኣካላት (ንኣብነት 'ሲሊኮን ቫሊ ባንክ'ን 'ሲሊኮን_ቫሊ_ባንክ'ን ምውህሃድ ንዝተፈላለዩ ምውህሃድ እናነጸግካ ከም 'መስከረም 16, 2023'ን 'መስከረም 2, 2023'ን ዝኣመሰሉ ዕለታት)።
ንናይ ኣካላት ስምን መግለጺ ባህርያትን ናይ ጽሑፍ ምትእትታው ብምሕሳብ ኢና ንጅምር። ነዚ ንምዕዋት ኣብ LangChain ኣብ ዘሎ Neo4jVector integration from_existing_graph ሜላ ክንጥቀም ንኽእል ኢና፤
vector = Neo4jVector.from_existing_graph( OpenAIEmbeddings(), node_label='__Entity__', text_node_properties=['id', 'description'], embedding_node_property='embedding' )
from graphdatascience import GraphDataScience gds = GraphDataScience( os.environ["NEO4J_URI"], auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"]) )
G, result = gds.graph.project( "entities", # Graph name "__Entity__", # Node projection "*", # Relationship projection nodeProperties=["embedding"] # Configuration parameters )
ሕጂ እቲ ግራፍ ኣብ ትሕቲ ስም entities ፕሮጀክት ስለዝኾነ፡ ኣልጎሪዝም ግራፍ ክንፍጽም ንኽእል። ብምህናጽ ክንጅምር ኢና። እቶም ክልተ ኣገደስቲ መለክዒታት እቲ k-ዝቐረበ ግራፍ ክሳብ ክንደይ ስፍሕ ዝበለ ወይ ጽዑቕ ከም ዝኸውን ዝጸልዉ similarityCutoff ን topK ን እዮም። እቲ topK ንነፍሲ ወከፍ መስመር ክትረኽቦም ዘለካ ብዝሒ ጎረባብቲ ኮይኑ፡ ዝተሓተ ዋጋ 1. እቲ similarityCutoff ትሕቲ እዚ ደረት ተመሳሳልነት ዘለዎም ዝምድናታት ይፍልፍል። ኣብዚ፡ ነባሪ topK 10ን ብተዛማዲ ልዑል ተመሳሳልነት ምቁራጽ 0.95ን ክንጥቀም ኢና። ከም 0.95 ዝኣመሰለ ልዑል ተመሳሳልነት ዘለዎ ምቁራጽ ምጥቃም፡ ኣዝዮም ተመሳሰልቲ ጽምዲ ጥራይ ከም ምትእስሳር ከም ዝቑጸሩ የረጋግጽ፡ ናይ ሓሶት ኣወንታዊ ነገራት የጉድልን ልክዕነት የመሓይሽን።
ነቲ ውጽኢት ኣብ ክንዲ ናይቲ ናይ ፍልጠት ግራፍ ናብቲ ዝተተንበየ ኣብ ውሽጢ ዝኽሪ ዘሎ ግራፍ ክንመልሶ ስለ እንደሊ፡ ናይቲ ኣልጎሪዝም mutate ሞድ ክንጥቀም ኢና፤
similarity_threshold = 0.95 gds.knn.mutate( G, nodeProperties=['embedding'], mutateRelationshipType= 'SIMILAR', mutateProperty= 'score', similarityCutoff=similarity_threshold )
እቲ ዝቕጽል ስጉምቲ ምስቲ ሓደስቲ ዝተገመቱ ናይ ተመሳሳልነት ዝምድናታት ዝተኣሳሰሩ ጉጅለታት ኣካላት ምልላይ እዩ። ምልላይ ጉጅለታት ዝተኣሳሰሩ መስመራት ኣብ ትንተና መርበብ ብተደጋጋሚ ዝካየድ መስርሕ ኮይኑ፡ መብዛሕትኡ ግዜ ምፍላጥ ማሕበረሰብ ወይ ምትእኽኻብ ይበሃል፣ እዚ ድማ ንኡሳን ጉጅለታት ጽዑቕ ዝተኣሳሰሩ መስመራት ምርካብ ዘጠቓልል እዩ። ኣብዚ ኣብነት እዚ፡ ዋላ ኣንፈት ናይቶም ምትእስሳራት ዕሽሽ እንተበልና፡ ኩሎም ኖድታት ዝተኣሳሰሩሉ ክፋላት ናይ ሓደ ግራፍ ንምርካብ ዝሕግዘና ክንጥቀም ኢና።
ነቲ ውጽኢት ናብቲ ዳታቤዝ ንምምላስ (ዝተዓቀበ ግራፍ) ናይቲ ኣልጎሪዝም write ሞድ ንጥቀም፤
gds.wcc.write( G, writeProperty="wcc", relationshipTypes=["SIMILAR"] )
ንጽጽር ምትእትታው ጽሑፍ ክደግሙ ዝኽእሉ ንምርካብ ይሕግዝ፣ ግን ኣካል ናይቲ መስርሕ ምፍታሕ ኣካል ጥራይ እዩ። ንኣብነት ጉግልን ኣፕልን ኣብ ምትእትታው ቦታ ኣዝዮም ቅርበት ኣለዎም (0.96 cosine similarity using the ada-002 embedding model)። ን BMWን Mercedes Benzን እውን ከምኡ (0.97 ኮሳይን ተመሳሳልነት)። ልዑል ናይ ጽሑፍ ምትእትታው ተመሳሳልነት ጽቡቕ ጅማሮ እዩ፡ ግን ከነመሓይሾ ንኽእል ኢና። ስለዚ፡ ሰለስተ ወይ ትሕቲኡ ናይ ጽሑፍ ርሕቀት ዘለዎም ጽምዲ ቃላት ጥራይ ዘፍቅድ ተወሳኺ ፍልተር ክንውስኽ ኢና (እቶም ፊደላት ጥራይ ክቕየሩ ይኽእሉ ማለት እዩ)፤
word_edit_distance = 3 potential_duplicate_candidates = graph.query( """MATCH (e:`__Entity__`) WHERE size(e.id) > 3 // longer than 3 characters WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count WHERE count > 1 UNWIND nodes AS node // Add text distance WITH distinct [n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance OR node.id CONTAINS n.id | n.id] AS intermediate_results WHERE size(intermediate_results) > 1 WITH collect(intermediate_results) AS results // combine groups together if they share elements UNWIND range(0, size(results)-1, 1) as index WITH results, index, results[index] as result WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) | CASE WHEN index <> index2 AND size(apoc.coll.intersection(acc, results[index2])) > 0 THEN apoc.coll.union(acc, results[index2]) ELSE acc END )) as combinedResult WITH distinct(combinedResult) as combinedResult // extra filtering WITH collect(combinedResult) as allCombinedResults UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1) WHERE x <> combinedResultIndex AND apoc.coll.containsAll(allCombinedResults[x], combinedResult) ) RETURN combinedResult """, params={'distance': word_edit_distance})
{'combinedResult': ['Sinn Fein', 'Sinn Féin']}, {'combinedResult': ['Government', 'Governments']}, {'combinedResult': ['Unreal Engine', 'Unreal_Engine']}, {'combinedResult': ['March 2016', 'March 2020', 'March 2022', 'March_2023']}, {'combinedResult': ['Humana Inc', 'Humana Inc.']}, {'combinedResult': ['New York Jets', 'New York Mets']}, {'combinedResult': ['Asia Pacific', 'Asia-Pacific', 'Asia_Pacific']}, {'combinedResult': ['Bengaluru', 'Mangaluru']}, {'combinedResult': ['US Securities And Exchange Commission', 'Us Securities And Exchange Commission']}, {'combinedResult': ['Jp Morgan', 'Jpmorgan']}, {'combinedResult': ['Brighton', 'Brixton']},
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged. The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates. Here are the rules for identifying duplicates: 1. Entities with minor typographical differences should be considered duplicates. 2. Entities with different formats but the same content should be considered duplicates. 3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates. 4. If it refers to different numbers, dates, or products, do not merge results """ user_template = """ Here is the list of entities to process: {entities} Please identify duplicates, merge them, and provide the merged list. """
ኣነ ኩሉ ግዜ ኣብ LangChain with_structured_output ሜላ ክጥቀም ደስ ይብለኒ structured data output ክጽበ ከለኹ ነቶም ውጽኢታት ብኢድካ ምትንታን ከይግደድ።
ኣብዚ፡ ነቲ ውጽኢት ከም list of lists ክንገልጾ ኢና ፣ ኣብዚ ነፍሲ ወከፍ ውሽጣዊ ዝርዝር ክውሃሃዱ ዝግበኦም ኣካላት ዝሓዘ እዩ። እዚ ኣቃውማ እዚ ንኣብነት እቲ እታው [Sony, Sony Inc, Google, Google Inc] ክኸውን ዝኽእል ስናርዮታት ንምሕላው ይጥቀመሉ። ኣብ ከምዚ ዝኣመሰለ ኩነታት፡ “ሶኒ”ን “ሶኒ ኢንክ”ን ካብ “ጉግል”ን “ጉግል ኢንክ”ን ተፈልዮም ክትወሃሃድ ምደለኻ።
class DuplicateEntities(BaseModel): entities: List[str] = Field( description="Entities that represent the same object or real-world entity and should be merged" ) class Disambiguate(BaseModel): merge_entities: Optional[List[DuplicateEntities]] = Field( description="Lists of entities that represent the same object or real-world entity and should be merged" ) extraction_llm = ChatOpenAI(model_name="gpt-4o").with_structured_output( Disambiguate )
ቀጺልና፡ ነቲ LLM ፕሮምፕት ምስቲ ዝተሃንጸ ውጽኢት ብምውህሃድ፡ LangChain Expression Language (LCEL) syntax ተጠቒምና ሰንሰለት ንፈጥርን ኣብ ውሽጢ disambiguate function ንዓጽዎን።
extraction_chain = extraction_prompt | extraction_llm def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]: return [ el.entities for el in extraction_chain.invoke({"entities": entities}).merge_entities ]
ኩሎም ክኾኑ ዝኽእሉ ሕጹያት ኖድስ ብመንገዲ entity_resolution function ከነካይዶም ኣለና እሞ ክውሃሃዱ ኣለዎም ድዩ ኣይግባእን ክንውስን። ነቲ መስርሕ ንምቅልጣፍ፡ እንደገና ነቶም ናይ LLM ጻውዒታት ማዕረ ክንገብሮም ኢና፤
merged_entities = [] with ThreadPoolExecutor(max_workers=MAX_WORKERS) as executor: # Submitting all tasks and creating a list of future objects futures = [ executor.submit(entity_resolution, el['combinedResult']) for el in potential_duplicate_candidates ] for future in tqdm( as_completed(futures), total=len(futures), desc="Processing documents" ): to_merge = future.result() if to_merge: merged_entities.extend(to_merge)
ናይ መወዳእታ ስጉምቲ ናይ entity resolution ውጽኢት ካብ entity_resolution LLM ወሲድካ ነቶም ዝተገልጹ ኖድታት ብምውህሃድ ናብቲ ዳታቤዝ ምምላስ የጠቓልል፤
graph.query(""" UNWIND $data AS candidates CALL { WITH candidates MATCH (e:__Entity__) WHERE e.id IN candidates RETURN collect(e) AS nodes } CALL apoc.refactor.mergeNodes(nodes, {properties: { description:'combine', `.*`: 'discard' }}) YIELD node RETURN count(*) """, params={"data": merged_entities})
ጽማቕ ባእታታት
ኣብ ዝቕጽል ስጉምቲ እቶም ጸሓፍቲ ናይ ባእታ ምድማር ስጉምቲ ይፍጽሙ። ብመሰረቱ ነፍሲ ወከፍ መስመርን ዝምድናን ብናይ ይሓልፍ ። እቶም ጸሓፍቲ ንሓድሽነትን ተገዳስነትን ኣቀራርባኦም የስተብህሉ፤
“ብሓፈሻ፡ ሃብታም ገላጺ ጽሑፍ ንሓደ ዓይነት መስመራት ኣብ ሓደ ጫውጫው ክፈጥር ዝኽእል ኣቃውማ ግራፍ ምጥቃምና ምስ ክልቲኡ ዓቕሚ LLMsን ድሌታት ዓለማዊ፡ ሕቶ ዘተኮረ ምጽማቕን ዝሰማማዕ እዩ። እዞም ባህርያት እዚኣቶም፡ ንመዐቀኒ ግራፍና ካብቶም ልሙዳት ግራፍ ፍልጠት እውን ይፈልይዎ እዮም፣ እዚ ግራፍ እዚ ንታሕቲ ንዝግበር ናይ ምምዝዛን ዕማማት ኣብ ጽፉፍን ቅኑዕን ስሉስ ፍልጠት (ርእሰ-ሓሳብ፡ ምልክት፡ ኣቕሓ) ይምርኰስ።”
ምህናጽን ምጽማቕን ማሕበረሰባት
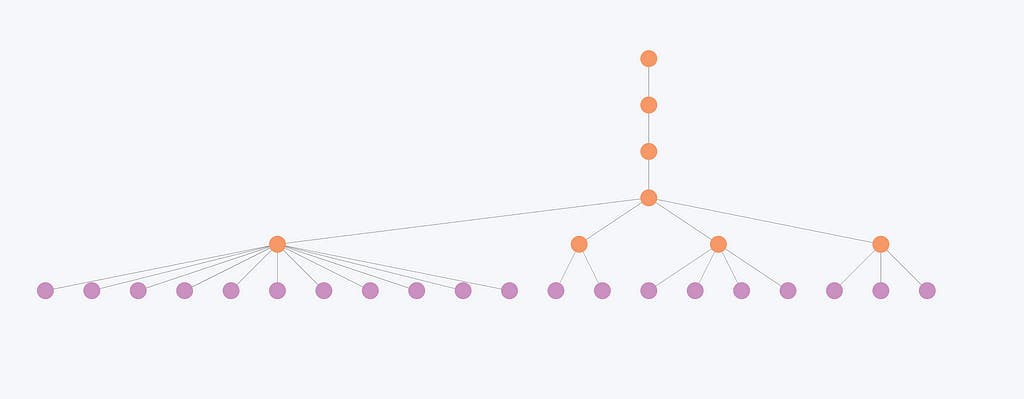
ኣብ መስርሕ ህንፀትን ኢንዴክስን ግራፍ ናይ መወዳእታ ስጉምቲ ኣብ ውሽጢ እቲ ግራፍ ዝርከቡ ማሕበረሰባት ምልላይ ዘጠቓልል እዩ። ኣብዚ ጽሑፍ እዚ፡ ማሕበረሰብ ካብቲ ዝተረፈ ግራፍ ንላዕሊ ኣብ ነንሕድሕዶም ብዝያዳ ጽዑቕ ምትእስሳር ዘለዎም ጉጅለ ኖድታት ኮይኑ፡ ዝለዓለ ደረጃ ምትእስሳር ወይ ተመሳሳልነት ከምዘለዎ ዘመልክት እዩ። እዚ ዝስዕብ ስእላዊ ስእሊ ኣብነት ውጽኢት ምልላይ ማሕበረሰብ ዘርኢ እዩ።
G, result = gds.graph.project( "communities", # Graph name "__Entity__", # Node projection { "_ALL_": { "type": "*", "orientation": "UNDIRECTED", "properties": {"weight": {"property": "*", "aggregation": "COUNT"}}, } }, )
wcc = gds.wcc.stats(G) print(f"Component count: {wcc['componentCount']}") print(f"Component distribution: {wcc['componentDistribution']}") # Component count: 1119 # Component distribution: { # "min":1, # "p5":1, # "max":9109, # "p999":43, # "p99":19, # "p1":1, # "p10":1, # "p90":7, # "p50":2, # "p25":1, # "p75":4, # "p95":10, # "mean":11.3 }
ቀጺልና፡ ኣብ ቤተ-መጻሕፍቲ GDS እውን ዝርከብ ናይ ላይደን ኣልጎሪዝም ከነካይዶ ኢና፡ ነቲ includeIntermediateCommunities ዝብል መለክዒ ድማ ኣብ ኩሉ ደረጃታት ማሕበረሰባት ክምለስን ክዕቅብን ከነኽእሎ ኢና። ብተወሳኺ ነቲ ዝተመዝነ ፍልልይ ናይ ላይደን ኣልጎሪዝም ንምስራሕ relationshipWeightProperty ዝብል መለክዒ ኣካቲትና ኣለና። ናይቲ ኣልጎሪዝም write ሞድ ምጥቃም ነቲ ውጽኢት ከም ናይ መስመር ንብረት ይዕቅቦ።
gds.leiden.write( G, writeProperty="communities", includeIntermediateCommunities=True, relationshipWeightProperty="weight", )
graph.query(""" MATCH (e:`__Entity__`) UNWIND range(0, size(e.communities) - 1 , 1) AS index CALL { WITH e, index WITH e, index WHERE index = 0 MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET c.level = index MERGE (e)-[:IN_COMMUNITY]->(c) RETURN count(*) AS count_0 } CALL { WITH e, index WITH e, index WHERE index > 0 MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])}) ON CREATE SET current.level = index MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])}) ON CREATE SET previous.level = index - 1 MERGE (previous)-[:IN_COMMUNITY]->(current) RETURN count(*) AS count_1 } RETURN count(*) """)
እቶም ጸሓፍቲ ብተወሳኺ community rank የተኣታቱ ፣ እዚ ድማ ኣብ ውሽጢ እቲ ማሕበረሰብ ዝርከቡ ኣካላት ዝረኣዩሉ ብዝሒ ፍሉያት ቁንጣሮ ጽሑፍ ዘመልክት እዩ፤
graph.query(""" MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document) WITH c, count(distinct d) AS rank SET c.community_rank = rank; """)
community_size = graph.query( """ MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__) WITH c, count(distinct e) AS entities RETURN split(c.id, '-')[0] AS level, entities """ ) community_size_df = pd.DataFrame.from_records(community_size) percentiles_data = [] for level in community_size_df["level"].unique(): subset = community_size_df[community_size_df["level"] == level]["entities"] num_communities = len(subset) percentiles = np.percentile(subset, [25, 50, 75, 90, 99]) percentiles_data.append( [ level, num_communities, percentiles[0], percentiles[1], percentiles[2], percentiles[3], percentiles[4], max(subset) ] ) # Create a DataFrame with the percentiles percentiles_df = pd.DataFrame( percentiles_data, columns=[ "Level", "Number of communities", "25th Percentile", "50th Percentile", "75th Percentile", "90th Percentile", "99th Percentile", "Max" ], ) percentiles_df
community_info = graph.query(""" MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__) WHERE c.level IN [0,1,4] WITH c, collect(e ) AS nodes WHERE size(nodes) > 1 CALL apoc.path.subgraphAll(nodes[0], { whitelistNodes:nodes }) YIELD relationships RETURN c.id AS communityId, [n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes, [r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels """)
{'communityId': '0-6014', 'nodes': [{'id': 'Darrell Hughes', 'description': None, type:"Person"}, {'id': 'Chief Pilot', 'description': None, type: "Person"}, ... }], 'rels': [{'start': 'Ryanair Dac', 'description': 'Informed of the change in chief pilot', 'type': 'INFORMED', 'end': 'Irish Aviation Authority'}, {'start': 'Ryanair Dac', 'description': 'Dismissed after internal investigation found unacceptable behaviour', 'type': 'DISMISSED', 'end': 'Aidan Murray'}, ... ]}
"summary": "Abila City Park as the central location", "explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"
community_template = """Based on the provided nodes and relationships that belong to the same graph community, generate a natural language summary of the provided information: {community_info} Summary:""" # noqa: E501 community_prompt = ChatPromptTemplate.from_messages( [ ( "system", "Given an input triples, generate the information summary. No pre-amble.", ), ("human", community_template), ] ) community_chain = community_prompt | llm | StrOutputParser()
def prepare_string(data): nodes_str = "Nodes are:\n" for node in data['nodes']: node_id = node['id'] node_type = node['type'] if 'description' in node and node['description']: node_description = f", description: {node['description']}" else: node_description = "" nodes_str += f"id: {node_id}, type: {node_type}{node_description}\n" rels_str = "Relationships are:\n" for rel in data['rels']: start = rel['start'] end = rel['end'] rel_type = rel['type'] if 'description' in rel and rel['description']: description = f", description: {rel['description']}" else: description = "" rels_str += f"({start})-[:{rel_type}]->({end}){description}\n" return nodes_str + "\n" + rels_str def process_community(community): stringify_info = prepare_string(community) summary = community_chain.invoke({'community_info': stringify_info}) return {"community": community['communityId'], "summary": summary}
summaries = [] with ThreadPoolExecutor() as executor: futures = {executor.submit(process_community, community): community for community in community_info} for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"): summaries.append(future.result())
graph.query(""" UNWIND $data AS row MERGE (c:__Community__ {id:row.community}) SET c.summary = row.summary """, params={"data": summaries})
ሕጂ እቲ ግራፍ እቶም መበቆላውያን ሰነዳት፡ ዝተቐድሑ ኣካላትን ዝምድናታትን፡ ከምኡ’ውን ስርዓተ-መሰረት ዘለዎ ኣቃውማ ማሕበረሰብን ጽማቕን ዝሓዘ እዩ።
መጠቃለሊ
ናይቲ “ካብ ከባብያዊ ናብ ዓለማዊ” ዝብል ጽሑፍ፡ ሓድሽ ኣገባብ ግራፍራግ ኣብ ምርኣይ ዓቢ ስራሕ ሰሪሖም እዮም። ካብ ዝተፈላለዩ ሰነዳት ዝረኸብናዮ ሓበሬታ ከመይ ጌርና ናብ ሓደ ስርዓተ-መሰረት ዘለዎ ናይ ፍልጠት ግራፍ ኣቃውማ ክንጥርንፍን ከነጠቓልልን ከም እንኽእል ዘርእዩ እዮም።
ብዛዕባ እዚ ኣርእስቲ ዝያዳ ንምፍላጥ፡ ኣብቲ ንዕለት 7 ሕዳር ዝካየድ NODES 2024 ተጸንበሩና፡ እዚ ድማ ብዛዕባ በሊሕ ኣፕስ፡ ፍልጠት ግራፍን AIን ዝምልከት ነጻ ቨርቹዋል ዲቨሎፐር ዋዕላና እዩ። !
L O A D I N G
. . . comments & more!
. . . comments & more!



