




































visit
NLP Tutorial: Topic Modeling in Python with BerTopic by@davisdavid
47,086 reads
NLP Tutorial: Topic Modeling in Python with BerTopic
by Davis DavidAugust 24th, 2021
Too Long; Didn't Read
Topic modeling is an unsupervised machine learning technique that can automatically identify different topics present in a document (textual data). Data has become a key asset/tool to run many businesses around the world. With topic modeling, you can collect unstructured datasets, analyzing the documents, and obtain the relevant and desired information that can assist you in making a better decision.Company Mentioned
Topic modeling is an unsupervised machine learning technique that automatically identifies different topics present in a document (textual data). Data has become a key asset/tool to run many businesses around the world. With topic modeling, you can collect unstructured datasets, analyzing the documents, and obtain the relevant and desired information that can assist you in making a better decision.If you are interested in the visualization options, you need to install them as follows.BerTopic supports different transformers and language backends that you can use to create a model. You can install one according to the options available below.In the above code, the number of topics that will be generated is 20.(c) The last option is to reduce the number of topics after training the model. This is a great option if retraining the model will take many hours.In the above example, you reduce the number of topics to 15 after training the model.
There are different techniques to perform topic modeling (such as LDA) but, in this NLP tutorial, you will learn how to use the BerTopic technique developed by .
Table of Contents:
- What is BerTopic
- How to Install BerTopic
- Load Olympic Tokyo Tweets Data
- Create BerTopic Model
- Select Top Topics
- Select One Topic
- Topic Modeling Visualization
- Topic Reduction
- Make Prediction
- Save and Load Model
What is BerTopic?
BerTopic is a topic modeling technique that uses transformers (BERT embeddings) and class-based TF-IDF to create dense clusters. It also allows you to easily interpret and visualize the topics generated.The BerTopic algorithm contains 3 stages:
1.Embed the textual data(documents)
In this step, the algorithm extracts document embeddings with BERT, or it can use any other embedding technique.
- "paraphrase-MiniLM-L6-v2"- This is an English BERT-based model trained specifically for semantic similarity tasks.
- "paraphrase-multilingual-MiniLM-L12-v2"- This is similar to the first, with one major difference is that the xlm models work for 50+ languages.
2.Cluster Documents
It uses UMAP to reduce the dimensionality of embeddings and the HDBSCAN technique to cluster reduced embeddings and create clusters of semantically similar documents.
3.Create a topic representation
The last step is to extract and reduce topics with and then improve the coherence of words with Maximal Marginal Relevance.
How to Install BerTopic
You can install the package via pip:pip install bertopicpip install bertopic[visualization]- pip install bertopic[flair]
- pip install bertopic[gensim]
- pip install bertopic[spacy]
- pip install bertopic[use]
The Libraries
We will use the following libraries that will help us to load data and create a model from BerTopic.#import packages
import pandas as pd
import numpy as np
from bertopic import BERTopicStep 1. Load Data
In this NLP tutorial, we will use Olympic Tokyo 2020 Tweets with a goal to create a model that can automatically categorize the tweets by their topics.
You can download the datasets .#load data
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/data/tokyo_2020_tweets.csv", engine='python')
# select only 6000 tweets
df = df[0:6000]NB: We selected only 6,000 tweets for computational reasons.
Step 2. Create Model
To create a model using BERTopic, you need to load the tweets as a list and then pass it to the fit_transform method. This method will do the following:- Fit the model on the collection of tweets.
- Generate topics.
- Return the tweets with the topics.
# create model
model = BERTopic(verbose=True)
#convert to list
docs = df.text.to_list()
topics, probabilities = model.fit_transform(docs)
Step 3. Select Top Topics
After training the model, you can access the size of topics in descending order.model.get_topic_freq().head(11)Note: Topic -1 is the largest and it refers to outliers tweets that do not assign to any topics generated. In this case, we will ignore Topic -1.
Step 4. Select One Topic
You can select a specific topic and get the top n words for that topic and their c-TF-IDF scores.model.get_topic(6)For this selected topic, common words are Sweden, goal,rolfo, swedes, goals, soccer. It is obvious this topic focuses on “soccer for Sweden team”.
Step 5:Topic Modeling Visualization
BerTopic allows you to visualize the topics that were generated in a way very similar to LDAvis. This will allow you to get more insights into the topic's quality. In this article, we will look at three methods to visualize the topics.Visualize Topics
The visualize_topics method can help you visualize topics generated with their sizes and corresponding words. The visualization is inspired by LDavis.model.visualize_topics()Visualize Terms
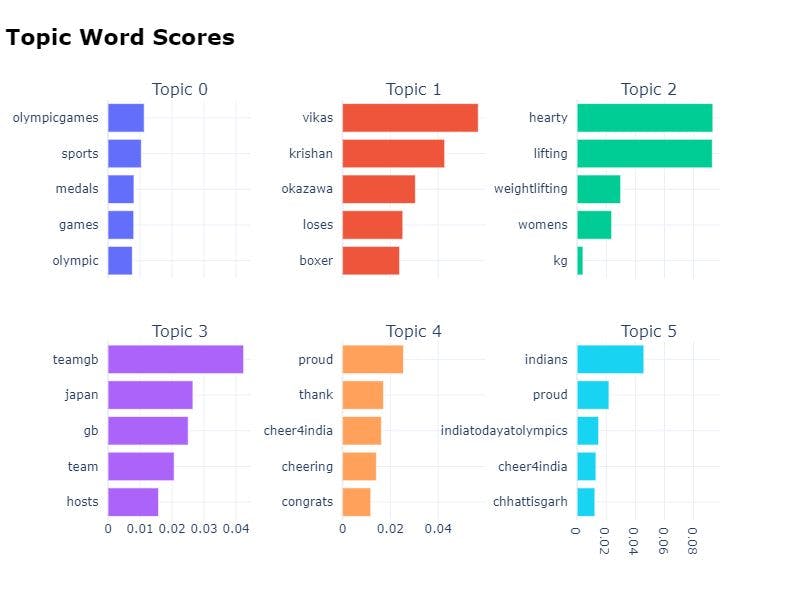
The visualize_barchart method will show the selected terms for a few topics by creating bar charts out of the c-TF-IDF scores. You can then compare topic representations to each other and gain more insights from the topic generated.model.visualize_barchart()In the above graph, you can see Top words in Topic 4 are proud, thank, cheer4india, cheering, and congrats.
Visualize Topic Similarity
You can also visualize how similar certain topics are to each other. To visualize the heatmap, simply call.model.visualize_heatmap()In the above graph, you can see that topic 93 is similar to topic 102 with a similarity score of 0.933.
Topic Reduction
Sometimes you may end up with too many topics or too few topics generated, BerTopic gives you an option to control this behavior in different ways.(a) You can set the number of topics you want by setting the argument "nr_topics" with a number of topics you want. The BerTopic will find similar topics and merge them.
model = BERTopic(nr_topics=20) (b)Another option is to reduce the number of topics automatically. To use this option, you need to set "nr_topics" to "auto" before training the model.
model = BERTopic(nr_topics="auto")new_topics, new_probs = model.reduce_topics(docs, topics, probabilities, nr_topics=15)Step 6:Make Prediction
To predict a topic of a new document, you need to add a new instance(s) on the transform method.topics, probs = model.transform(new_docs)Step 7:Save Model
You can save a trained model by using the save method.model.save("my_topics_model")Step 8:Load Model
You can load the model by using the load method.BerTopic_model = BERTopic.load("my_topics_model")Final Thoughts on Topic Modeling in Python with BerTopic
In this NLP tutorial, you have learned- How to create a BerTopic Model.
- Select topics generated.
- Visualize topics and words per topic to gain more insights.
- Different techniques to reduce the number of topics generated.
- How to make predictions.
- How to save and load BerTopic Model.
model = BERTopic(language="German")Note: Select a language in which its embedding model exists.
If you have a mixture of languages in your documents, you can set
language="multilingual"And you can read more articles like this here.
Want to keep up to date with all the latest in python? Subscribe to our newsletter in the footer below.
L O A D I N G
. . . comments & more!
. . . comments & more!







