



















visit
Why You Should (Almost) Always Choose Sync Gunicorn Workers by@shamik-ray
22,813 reads
Why You Should (Almost) Always Choose Sync Gunicorn Workers
by Shamik RayApril 19th, 2020
Too Long; Didn't Read
Gunicorn is a widely popular WSGI Server and its popularity is because it is lightweight, fast, simple yet can support most of the requirements you would have to host an app on production. The default worker type is Sync and I will be arguing for it. Async workers like Gevent create new greenlets (lightweight pseudo threads) Every time a new request comes they are handled by greenlets spawned by the worker threads. At the same time, the resources needed to serve the requests will be less.Company Mentioned
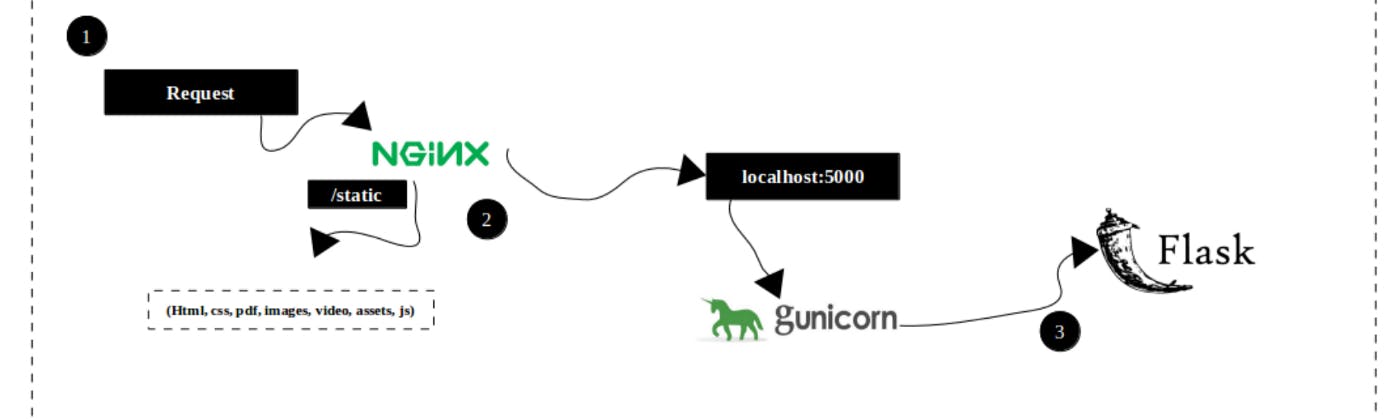
Anyone working on a WSGI web application frameworks like would know that as a best practice it is very important to use a WSGI HTTP Server like to deploy the app outside your development servers.Gunicorn is a widely popular WSGI Server and its popularity is because it is lightweight, fast, simple yet can support most of the requirements you would have to host an app on production. I wouldn’t go in detail here on “Why Gunicorn/Or Why Not”. The thing I will be discussing here is what type of worker type you should select and why.
Gunicorn is based on the pre-fork worker model. This means that there is a central master process that manages a set of worker processes. The master never knows anything about individual clients. All requests and responses are handled completely by worker processes.Worker Types
The gunicorn worker can be of 2 broad types: Sync and Async.
The default worker type is Sync and I will be arguing for it. As the name suggests the sync workers execute one request after another. You can have multiple such workers, and the no of concurrent requests served is equal to the no of such workers.In contrast to this Gunicorn offers an Async worker type. I will talk about the Gevent worker type which is the most popular among all. Async workers like Gevent create new greenlets (lightweight pseudo threads). Every time a new request comes they are handled by greenlets spawned by the worker threads. The core idea is when there is IO bound action in your code the greenlet will yield and give a handle to another greenlet to use the CPU. So when many requests are coming to your app, it can handle them concurrently, the IO-bound calls are not going to block the CPU and throughput will improve. At the same time, the resources needed to serve the requests will be less.Why not async workers
While it is tempting to use async worker type like Gevent and spawn thousands of greenlets, but it comes at a cost that you need to know about.The Gunicorn documentation clearly defines when you should be using an async worker typeWe can infer from these any IO-bound operations where IO is relatively longer can benefit from async workers.any web application which makes outgoing requests to APIs which can take an undefined amount of time to return will benefit from an asynchronous worker
The points in favor of using async are as follows
- IO-bound operations are not going to use CPU resources, and CPU cycles won’t get wasted when you are doing IO. Some other requests can use the CPU.
- Modern-day networks can do a lot of network operations at the same time, also RAMs are cheaper than ever before, so theoretically all IO can be done in parallel if you have a lot of IO-bound requests.
- If one or more of your backend service which you are calling is slow to respond then only those requests which are calling them are affected and not the other ones since your worker thread is continuing to respond to other requests creating newer greenlets and your CPU is not blocked.
- Lastly, this lets you have workers memory footprint small since the pseudo threads share the memory and if you are loading large Models you can have one worker and server more requests(theoretically, if you get things right)
Caveats which are not specified in the examples
There are a lot of resources/examples on the internet where you will find people advocating Gevent. But most of these examples don’t talk about the issues you would face when using it in the actual production-grade app.- Using Gevent needs all of your code to be co-operative in nature or all libraries you use should be monkey-patchable. Now this line may sound simple but it’s a big ask. This means either ensuring all the DB drivers, clients, 3rd party libraries used all of these are either pure python, which would ensure they can be monkey-patched OR they are written specifically with Gevent support. If any of your library or part of code does not yield while doing IO then all your greenlets in that worker are blocked and this will result in long halts. You will need to find any such code and fix it.
- Using greenlets, your connections to your backend services will explode and needs to be handled. You need to have connection pools that can be reused and at the same time ensure that your app and backend service can create and maintain that many socket connections.
- CPU blocking operations are going to stop all of your greenlets so if your requests have some CPU bound task it’s not going to help much. Of course, you can explicitly yield in between these tasks but you will need to ensure that part of code is greenlet safe.
- You need to do all of these every time you/your team write a new piece of code
Sync is Simple
Sync workers are largely simplified and works well in most of the cases. My advice is you start with sync workers and try to fix your app code as much possible if that is in your control, instead of expecting magic to happen when you turn on ‘Gevent’.If your backend services are all in the same network then latency will be very low and you shouldn’t be super worried about blocking IO. Can say from experience, with 3–4 workers you can handle thousands of concurrent users easily with a proper application cache in place. In case you need more throughput you can have more threads per worker which will make the worker type gthread, but still, a sync worker and the memory footprint per thread will be lower.If you are having a large memory footprint per worker, maybe because you are loading a large model, try using preload True, which would ensure that you are loading and then forking the workers. There are other options as well. I would love to write something on it later.If your app has multiple outbound calls to API’s outside your network, then you must safeguard your app by setting reasonable timeouts in your urllib/requests connection pool. Also, make sure that your application has reasonable worker timeouts which would ensure that one or more bad requests don’t block your other requests for a long time.Finally, if all of these fails and you are not able to scale and use your resources efficiently consider using async workers.NOTE: In some specific cases like setting up a web socket, Streaming requests, and responses you will need to use async workers always.
References: CallslogsL O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES


8 Lessons From My 9 Years in Tech #life-lessons
Nov 03, 2021





