

































Jan 01, 1970
সরাসরি পছন্দ অপ্টিমাইজেশান: আপনার ভাষা মডেল গোপনে একটি পুরস্কার মডেল দ্বারা@textmodels
231 পড়া
সরাসরি পছন্দ অপ্টিমাইজেশান: আপনার ভাষা মডেল গোপনে একটি পুরস্কার মডেল
দ্বারা Writings, Papers and Blogs on Text Models5m2024/08/25
অতিদীর্ঘ; পড়তে
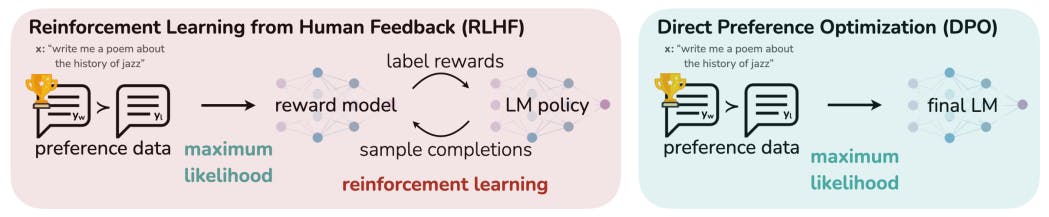
ডাইরেক্ট প্রেফারেন্স অপ্টিমাইজেশান (DPO) মানুষের পছন্দের সাথে ভাষার মডেলগুলিকে সারিবদ্ধ করার জন্য শক্তিবৃদ্ধি শেখার একটি সহজ, স্থিতিশীল বিকল্প প্রবর্তন করে। পুরষ্কার মডেলিং এবং জটিল প্রশিক্ষণ পদ্ধতির প্রয়োজনীয়তা দূর করে, ডিপিও দক্ষ ফাইন-টিউনিং অফার করে যা পিপিও-ভিত্তিক RLHF-এর মতো বিদ্যমান পদ্ধতিগুলির কার্যকারিতার সাথে মেলে বা ছাড়িয়ে যায়, বিশেষ করে সেন্টিমেন্ট মড্যুলেশন, সংক্ষিপ্তকরণ এবং সংলাপের কাজগুলিতে।লেখক:
(1) রাফায়েল রাফাইলো, স্ট্যানফোর্ড বিশ্ববিদ্যালয় এবং সমান অবদান; আগে তালিকাভুক্ত আরও জুনিয়র লেখক; (2) অর্চিত শর্মা, স্ট্যানফোর্ড বিশ্ববিদ্যালয় এবং সমান অবদান; আগে তালিকাভুক্ত আরও জুনিয়র লেখক; (3) এরিক মিচেল, স্ট্যানফোর্ড বিশ্ববিদ্যালয় এবং সমান অবদান; আগে তালিকাভুক্ত আরও জুনিয়র লেখক; (4) Stefano Ermon, CZ Biohub; (5) ক্রিস্টোফার ডি. ম্যানিং, স্ট্যানফোর্ড বিশ্ববিদ্যালয়; (6) চেলসি ফিন, স্ট্যানফোর্ড বিশ্ববিদ্যালয়।লিঙ্কের টেবিল
7 আলোচনা, স্বীকৃতি, এবং রেফারেন্স
A.1 KL- সীমাবদ্ধ পুরষ্কার সর্বাধিকীকরণ উদ্দেশ্যের সর্বোত্তম অর্জন করা
A.2 ব্র্যাডলি-টেরি মডেলের অধীনে ডিপিও উদ্দেশ্য অর্জন করা
A.3 প্লাকেট-লুস মডেলের অধীনে ডিপিও উদ্দেশ্য অর্জন করা
A.4 ডিপিও উদ্দেশ্যের গ্রেডিয়েন্ট বের করা এবং লেমা 1 এবং 2 এর A.5 প্রমাণ
B DPO বাস্তবায়নের বিবরণ এবং হাইপারপ্যারামিটার
C পরীক্ষামূলক সেট-আপ এবং C.1 IMDb সেন্টিমেন্ট পরীক্ষা এবং বেসলাইন বিশদ সম্পর্কিত আরও বিশদ
C.2 GPT-4 কম্পিউটিং সারসংক্ষেপ এবং সংলাপ জয়ের হারের জন্য অনুরোধ করে
D.1 বিভিন্ন N এবং D.2 নমুনা প্রতিক্রিয়া এবং GPT-4 বিচারের জন্য N বেসলাইনের সেরা পারফরম্যান্স
বিমূর্ত
যদিও বৃহৎ মাপের আন-সুপারভাইজড ল্যাঙ্গুয়েজ মডেল (LMs) বিস্তৃত বিশ্ব জ্ঞান এবং কিছু যুক্তির দক্ষতা শিখে, তাদের প্রশিক্ষণের সম্পূর্ণরূপে তত্ত্বাবধানহীন প্রকৃতির কারণে তাদের আচরণের সুনির্দিষ্ট নিয়ন্ত্রণ অর্জন করা কঠিন। এই ধরনের স্টিয়ারিবিলিটি অর্জনের জন্য বিদ্যমান পদ্ধতিগুলি মডেল জেনারেশনের আপেক্ষিক মানের মানব লেবেল সংগ্রহ করে এবং এই পছন্দগুলির সাথে সারিবদ্ধ করার জন্য তত্ত্বাবধান না করা এলএমকে সূক্ষ্ম-টিউন করে, প্রায়শই মানুষের প্রতিক্রিয়া (RLHF) থেকে রিইনফোর্সমেন্ট লার্নিং সহ। যাইহোক, RLHF হল একটি জটিল এবং প্রায়শই অস্থির প্রক্রিয়া, প্রথমে একটি পুরস্কার মডেল ফিট করে যা মানুষের পছন্দগুলিকে প্রতিফলিত করে এবং তারপরে মূল মডেল থেকে খুব বেশি দূরে না গিয়ে এই আনুমানিক পুরষ্কারকে সর্বাধিক করার জন্য রিইনফোর্সমেন্ট লার্নিং ব্যবহার করে বৃহৎ অ-তত্ত্বাবধান করা LM-কে ফাইন-টিউনিং করে। এই কাগজে আমরা RLHF-এ পুরষ্কার মডেলের একটি নতুন প্যারামিটারাইজেশন প্রবর্তন করি যা বদ্ধ আকারে সংশ্লিষ্ট সর্বোত্তম নীতির নিষ্কাশন সক্ষম করে, যা আমাদের শুধুমাত্র একটি সাধারণ শ্রেণিবিন্যাসের ক্ষতির সাথে স্ট্যান্ডার্ড RLHF সমস্যা সমাধান করতে দেয়। ফলস্বরূপ অ্যালগরিদম, যাকে আমরা বলি ডাইরেক্ট প্রেফারেন্স অপ্টিমাইজেশান (DPO), স্থিতিশীল, পারফরম্যান্ট এবং গণনাগতভাবে হালকা, সূক্ষ্ম-টিউনিং বা উল্লেখযোগ্য হাইপারপ্যারামিটার টিউনিং করার সময় LM থেকে নমুনা নেওয়ার প্রয়োজনীয়তা দূর করে। আমাদের পরীক্ষাগুলি দেখায় যে ডিপিও এলএমগুলিকে সূক্ষ্ম-টিউন করতে পারে মানুষের পছন্দগুলির সাথে সাথে বা বিদ্যমান পদ্ধতিগুলির চেয়ে ভাল। উল্লেখযোগ্যভাবে, ডিপিও-র সাথে ফাইন-টিউনিং প্রজন্মের অনুভূতি নিয়ন্ত্রণ করার ক্ষমতার ক্ষেত্রে পিপিও-ভিত্তিক RLHF-কে ছাড়িয়ে যায় এবং বাস্তবায়ন এবং প্রশিক্ষণের জন্য যথেষ্ট সহজ হওয়ার সাথে সাথে সংক্ষিপ্তকরণ এবং একক-পালা সংলাপে প্রতিক্রিয়ার গুণমানকে মেলে বা উন্নত করে।1 ভূমিকা
খুব বড় ডেটাসেটে প্রশিক্ষিত বৃহৎ অনিয়ন্ত্রিত ভাষা মডেল (LMs) আশ্চর্যজনক ক্ষমতা অর্জন করে [11, 7, 40, 8]। যাইহোক, এই মডেলগুলি বিভিন্ন লক্ষ্য, অগ্রাধিকার এবং দক্ষতার সাথে মানুষের দ্বারা উত্পন্ন ডেটার উপর প্রশিক্ষিত। এর মধ্যে কিছু লক্ষ্য এবং দক্ষতা অনুকরণ করা বাঞ্ছনীয় নাও হতে পারে; উদাহরণস্বরূপ, যদিও আমরা আমাদের এআই কোডিং সহকারীকে সাধারণ প্রোগ্রামিং ভুলগুলিকে সংশোধন করার জন্য বুঝতে চাই, তবুও, কোড তৈরি করার সময়, আমরা আমাদের মডেলটিকে তার প্রশিক্ষণে উপস্থিত (সম্ভাব্য বিরল) উচ্চ-মানের কোডিং ক্ষমতার প্রতি পক্ষপাতিত্ব করতে চাই। তথ্য একইভাবে, আমরা আমাদের ভাষা মডেলটি 50% লোকের দ্বারা বিশ্বাস করা একটি সাধারণ ভুল ধারণা সম্পর্কে সচেতন হতে চাই, কিন্তু আমরা অবশ্যই চাই না যে মডেলটি এই ভুল ধারণাটিকে 50% প্রশ্নের ক্ষেত্রে সত্য বলে দাবি করুক! অন্য কথায়, মডেলের কাঙ্খিত প্রতিক্রিয়া এবং আচরণকে এর খুব বিস্তৃত জ্ঞান এবং ক্ষমতা থেকে নির্বাচন করা AI সিস্টেমগুলি তৈরি করার জন্য গুরুত্বপূর্ণ যা নিরাপদ, পারফরম্যান্স এবং নিয়ন্ত্রণযোগ্য [26]। যদিও বিদ্যমান পদ্ধতিগুলি সাধারণত রিইনফোর্সমেন্ট লার্নিং (RL) ব্যবহার করে মানুষের পছন্দের সাথে মেলে এলএমগুলি চালায়,
এই কাগজটি CC BY-NC-ND 4.0 DEED লাইসেন্সের অধীনে ।
L O A D I N G
. . . comments & more!
. . . comments & more!



