

































Jan 01, 1970
Doğrudan Tercih Optimizasyonu: Dil Modeliniz Gizlice Bir Ödül Modelidir ile@textmodels
231 okumalar
Doğrudan Tercih Optimizasyonu: Dil Modeliniz Gizlice Bir Ödül Modelidir
ile Writings, Papers and Blogs on Text Models5m2024/08/25
Çok uzun; Okumak
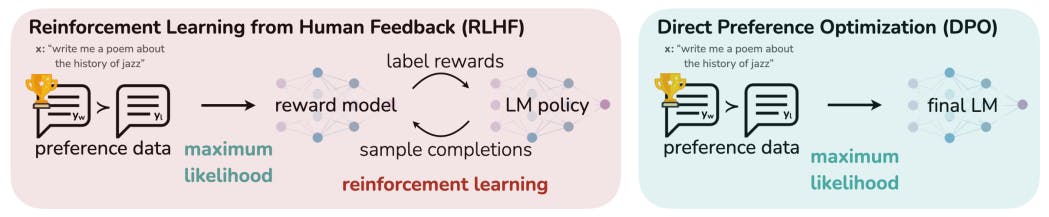
Doğrudan Tercih Optimizasyonu (DPO), dil modellerini insan tercihleriyle uyumlu hale getirmek için takviyeli öğrenmeye daha basit ve istikrarlı bir alternatif sunar. Ödül modelleme ve karmaşık eğitim prosedürlerine olan ihtiyacı ortadan kaldırarak DPO, özellikle duygu düzenleme, özetleme ve diyalog görevlerinde PPO tabanlı RLHF gibi mevcut yöntemlerin performansına uyan veya onu aşan verimli ince ayar sunar.Yazarlar:
(1) Rafael Rafailo, Stanford Üniversitesi ve Eşit katkı; daha önce listelenen daha genç yazarlar; (2) Archit Sharma, Stanford Üniversitesi ve Eşit katkı; daha önce listelenen daha genç yazarlar; (3) Eric Mitchel, Stanford Üniversitesi ve Eşit katkı; daha önce listelenen daha genç yazarlar; (4) Stefano Ermon, CZ Biohub; (5) Christopher D. Manning, Stanford Üniversitesi; (6) Chelsea Finn, Stanford Üniversitesi.Bağlantılar Tablosu
4 Doğrudan Tercih Optimizasyonu
7 Tartışma, Teşekkürler ve Referanslar
A.1 KL-Kısıtlı Ödül Maksimizasyonu Hedefinin Optimumunu Türetme
A.2 Bradley-Terry Modeli Altında DPO Hedefinin Türetilmesi
A.3 Plackett-Luce Modeli Altında DPO Hedefinin Türetilmesi
A.4 DPO Hedefinin Gradyanının Türetilmesi ve A.5 Lemma 1 ve 2'nin Kanıtı
B DPO Uygulama Ayrıntıları ve Hiperparametreler
C Deneysel Kurulum ve C.1 IMDb Duygu Deneyi ve Temel Ayrıntılar Hakkında Daha Fazla Bilgi
C.2 GPT-4 özetleme ve diyalog kazanma oranlarını hesaplama istemleri
C.3 Olasılıksızlık temel çizgisi
D.1 Çeşitli N ve D.2 Örnek Yanıtlar ve GPT-4 Yargıları için En İyi N temel çizgisinin performansı
Soyut
Büyük ölçekli gözetimsiz dil modelleri (LM'ler) geniş dünya bilgisi ve bazı muhakeme becerileri öğrenirken, eğitimlerinin tamamen gözetimsiz doğası nedeniyle davranışlarının kesin kontrolünü sağlamak zordur. Böyle bir yönlendirilebilirlik elde etmek için mevcut yöntemler, model nesillerinin göreceli kalitesinin insan etiketlerini toplar ve gözetimsiz LM'yi bu tercihlerle uyumlu hale getirmek için genellikle insan geri bildiriminden (RLHF) gelen takviyeli öğrenme ile ince ayarlar. Ancak RLHF karmaşık ve genellikle istikrarsız bir prosedürdür, önce insan tercihlerini yansıtan bir ödül modeline uyar ve ardından orijinal modelden çok uzaklaşmadan bu tahmini ödülü en üst düzeye çıkarmak için takviyeli öğrenmeyi kullanarak büyük gözetimsiz LM'yi ince ayarlar. Bu makalede, RLHF'deki ödül modelinin kapalı formda karşılık gelen en uygun politikanın çıkarılmasını sağlayan ve standart RLHF problemini yalnızca basit bir sınıflandırma kaybıyla çözmemize olanak tanıyan yeni bir parametrelendirmesini tanıtıyoruz. Doğrudan Tercih Optimizasyonu (DPO) adını verdiğimiz ortaya çıkan algoritma, kararlı, performanslı ve hesaplama açısından hafiftir ve ince ayar sırasında LM'den örnekleme veya önemli hiperparametre ayarlaması yapma ihtiyacını ortadan kaldırır. Deneylerimiz, DPO'nun LM'leri insan tercihleriyle uyumlu hale getirmek için mevcut yöntemler kadar veya daha iyi ince ayar yapabileceğini göstermektedir. Özellikle, DPO ile ince ayar, nesillerin duygusunu kontrol etme yeteneğinde PPO tabanlı RLHF'yi aşar ve özetleme ve tek turlu diyalogda yanıt kalitesini eşleştirir veya iyileştirirken uygulaması ve eğitimi önemli ölçüde daha basittir.1 Giriş
Çok büyük veri kümeleri üzerinde eğitilen büyük gözetimsiz dil modelleri (LM'ler) şaşırtıcı yetenekler kazanır [11, 7, 40, 8]. Ancak, bu modeller çok çeşitli hedeflere, önceliklere ve beceri setlerine sahip insanlar tarafından üretilen veriler üzerinde eğitilir. Bu hedeflerden ve beceri setlerinden bazılarını taklit etmek istenmeyebilir; örneğin, AI kodlama asistanımızın bunları düzeltmek için yaygın programlama hatalarını anlamasını isteyebilirken, yine de kod üretirken, modelimizi eğitim verilerinde bulunan (potansiyel olarak nadir) yüksek kaliteli kodlama yeteneğine doğru yönlendirmek isteriz. Benzer şekilde, dil modelimizin insanların %50'si tarafından inanılan yaygın bir yanlış anlamanın farkında olmasını isteyebiliriz, ancak modelin bu yanlış anlamanın kendisiyle ilgili sorguların %50'sinde doğru olduğunu iddia etmesini kesinlikle istemeyiz! Başka bir deyişle, modelin çok geniş bilgi ve yeteneklerinden istenen yanıtları ve davranışı seçmek, güvenli, performanslı ve kontrol edilebilir AI sistemleri oluşturmak için çok önemlidir [26]. Mevcut yöntemler genellikle LM'leri takviyeli öğrenme (RL) kullanarak insan tercihleriyle eşleşecek şekilde yönlendirirken,
Bu makale .
L O A D I N G
. . . comments & more!
. . . comments & more!



