

































Jan 01, 1970
Прямая оптимизация предпочтений: ваша языковая модель — это тайная модель вознаграждения к@textmodels
231 чтения
Прямая оптимизация предпочтений: ваша языковая модель — это тайная модель вознаграждения
к Writings, Papers and Blogs on Text Models5m2024/08/25
Слишком долго; Читать
Оптимизация прямых предпочтений (DPO) представляет собой более простую и стабильную альтернативу обучению с подкреплением для согласования языковых моделей с предпочтениями человека. Устраняя необходимость в моделировании вознаграждений и сложных процедурах обучения, DPO предлагает эффективную тонкую настройку, которая соответствует или превосходит производительность существующих методов, таких как RLHF на основе PPO, особенно в задачах модуляции настроений, резюмирования и диалога.Авторы:
(1) Рафаэль Рафаило, Стэнфордский университет и Equal Benefits; более молодые авторы, перечисленные ранее; (2) Арчит Шарма, Стэнфордский университет и Equal Benefits; более молодые авторы, перечисленные ранее; (3) Эрик Митчел, Стэнфордский университет и Equal Benefits; более молодые авторы, перечисленные ранее; (4) Стефано Эрмон, CZ Biohub; (5) Кристофер Д. Мэннинг, Стэнфордский университет; (6) Челси Финн, Стэнфордский университет.Таблица ссылок
4 Прямая оптимизация предпочтений
7 Обсуждение, благодарности и ссылки
A.1 Выведение оптимума для цели максимизации вознаграждения с ограничениями KL
A.2 Выведение цели DPO по модели Брэдли-Терри
A.3 Выведение цели DPO в соответствии с моделью Плакетта-Льюса
A.4 Вывод градиента цели DPO и A.5 Доказательство леммы 1 и 2
Детали реализации B DPO и гиперпараметры
C.2 Подсказки GPT-4 для вычисления коэффициентов резюмирования и выигрыша диалогов
C.3 Маловероятность исходного уровня
D.1 Эффективность базового уровня Best of N для различных N и D.2 Образцы ответов и суждения GPT-4
D.3 Подробности исследования на людях
Абстрактный
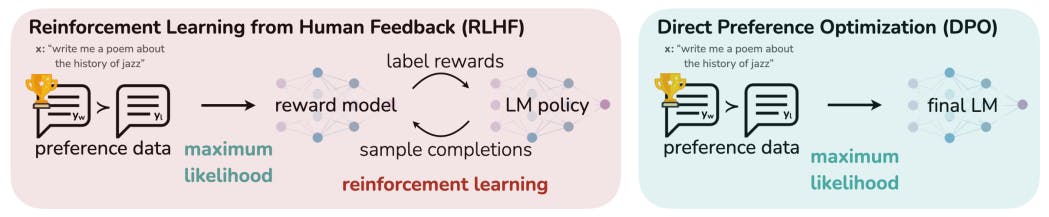
В то время как крупномасштабные неконтролируемые языковые модели (LM) изучают обширные мировые знания и некоторые навыки рассуждения, достижение точного контроля над их поведением затруднено из-за полностью неконтролируемой природы их обучения. Существующие методы получения такой управляемости собирают человеческие метки относительного качества поколений моделей и тонко настраивают неконтролируемый LM для соответствия этим предпочтениям, часто с подкреплением обучения на основе обратной связи с человеком (RLHF). Однако RLHF является сложной и часто нестабильной процедурой, сначала подбирая модель вознаграждения, которая отражает человеческие предпочтения, а затем тонко настраивая большой неконтролируемый LM с подкреплением обучения для максимизации этого предполагаемого вознаграждения, не уходя слишком далеко от исходной модели. В этой статье мы представляем новую параметризацию модели вознаграждения в RLHF, которая позволяет извлекать соответствующую оптимальную политику в замкнутой форме, позволяя нам решать стандартную задачу RLHF только с простой потерей классификации. Полученный алгоритм, который мы называем Direct Preference Optimization (DPO), является стабильным, производительным и вычислительно легким, устраняя необходимость в выборке из LM во время тонкой настройки или выполнения значительной настройки гиперпараметров. Наши эксперименты показывают, что DPO может точно настраивать LM для соответствия человеческим предпочтениям так же хорошо или лучше, чем существующие методы. В частности, тонкая настройка с DPO превосходит RLHF на основе PPO в способности контролировать настроения поколений и соответствует или улучшает качество ответа при резюмировании и однопоточном диалоге, будучи при этом существенно проще в реализации и обучении.1 Введение
Большие неконтролируемые языковые модели (LM), обученные на очень больших наборах данных, приобретают удивительные возможности [11, 7, 40, 8]. Однако эти модели обучаются на данных, сгенерированных людьми с широким спектром целей, приоритетов и наборов навыков. Некоторые из этих целей и наборов навыков могут быть нежелательными для имитации; например, хотя мы можем хотеть, чтобы наш помощник по кодированию ИИ понимал распространенные ошибки программирования, чтобы исправить их, тем не менее, при генерации кода мы хотели бы сместить нашу модель в сторону (потенциально редкой) высококачественной способности кодирования, присутствующей в ее обучающих данных. Аналогично, мы могли бы хотеть, чтобы наша языковая модель знала о распространенном заблуждении, в которое верят 50% людей, но мы определенно не хотим, чтобы модель утверждала, что это заблуждение является истинным в 50% запросов о ней! Другими словами, выбор желаемых ответов и поведения модели из ее очень широких знаний и способностей имеет решающее значение для создания систем ИИ, которые являются безопасными, производительными и управляемыми [26]. В то время как существующие методы обычно направляют LM в соответствии с предпочтениями человека, используя обучение с подкреплением (RL),
Данная статья по лицензии CC BY-NC-ND 4.0 DEED.
L O A D I N G
. . . comments & more!
. . . comments & more!



