























































Jan 01, 1970
701 Lesungen
Ein leicht verständlicher Überblick über die CPU- und GPU-Funktionen
Zu lang; Lesen
Der Artikel befasst sich mit den wesentlichen Unterschieden zwischen CPUs und GPUs bei der Verarbeitung paralleler Rechenaufgaben und behandelt Konzepte wie Von-Neumann-Architektur, Hyper-Threading und Instruction Pipelining. Er erläutert die Entwicklung von GPUs von Grafikprozessoren zu leistungsstarken Tools zur Beschleunigung von Deep-Learning-Algorithmen.Ein leicht verständlicher Überblick über das Geschehen in The Die
In diesem Artikel werden wir einige grundlegende Details auf niedriger Ebene durchgehen, um zu verstehen, warum GPUs gut für Grafik-, neuronale Netzwerk- und Deep-Learning-Aufgaben geeignet sind und CPUs für eine Vielzahl sequentieller, komplexer allgemeiner Computeraufgaben. Es gab mehrere Themen, die ich für diesen Beitrag recherchieren und etwas genauer verstehen musste, einige davon werde ich nur am Rande erwähnen. Der Fokus liegt bewusst nur auf den absoluten Grundlagen der CPU- und GPU-Verarbeitung.
Von Neumann Architecture
Frühere Computer waren dedizierte Geräte. Hardwareschaltkreise und Logikgatter wurden so programmiert, dass sie eine bestimmte Reihe von Aufgaben ausführen. Wenn etwas Neues getan werden musste, mussten die Schaltkreise neu verdrahtet werden. „Etwas Neues“ konnte so einfach sein wie die Durchführung mathematischer Berechnungen für zwei verschiedene Gleichungen. Während des Zweiten Weltkriegs arbeitete Alan Turing an einer programmierbaren Maschine, um die Enigma-Maschine zu schlagen, und veröffentlichte später das Papier „Turing Machine“. Etwa zur gleichen Zeit arbeiteten auch John von Neumann und andere Forscher an einer Idee, die im Wesentlichen vorschlug:
- Anweisungen und Daten sollten im gemeinsamen Speicher gespeichert werden (gespeichertes Programm).
- Verarbeitungs- und Speichereinheiten sollten getrennt sein.
- Die Steuereinheit kümmert sich um das Lesen von Daten und Anweisungen aus dem Speicher, um mithilfe der Verarbeitungseinheit Berechnungen durchzuführen.
Der Flaschenhals
- Verarbeitungsengpass - In einer Verarbeitungseinheit (physisches Logikgatter) kann sich immer nur ein Befehl und sein Operand befinden. Befehle werden nacheinander ausgeführt. Im Laufe der Jahre hat man sich darauf konzentriert, Prozessoren kleiner zu machen, schnellere Taktzyklen zu erzielen und die Anzahl der Kerne zu erhöhen.
- Speicherengpass - Da Prozessoren immer schneller wurden, wurden Geschwindigkeit und Datenmenge, die zwischen Speicher und Verarbeitungseinheit übertragen werden konnten, zum Engpass. Der Speicher ist um mehrere Größenordnungen langsamer als die CPU. Im Laufe der Jahre konzentrierte man sich auf die Erhöhung der Speicherdichte und Verkleinerung und verbesserte diese.
CPUs
Wir wissen, dass alles in unserem Computer binär ist. Zeichenfolgen, Bilder, Videos, Audiodateien, Betriebssysteme, Anwendungsprogramme usw. werden alle als Einsen und Nullen dargestellt. Die Spezifikationen der CPU-Architektur (RISC, CISC usw.) umfassen Befehlssätze (x86, x86-64, ARM usw.), die von den CPU-Herstellern eingehalten werden müssen und für die Schnittstelle zwischen Betriebssystem und Hardware verfügbar sind.
Betriebssystem- und Anwendungsprogramme werden einschließlich der Daten in Befehlssätze und Binärdaten übersetzt, die dann in der CPU verarbeitet werden. Auf Chipebene erfolgt die Verarbeitung an Transistoren und Logikgattern. Wenn Sie ein Programm zum Addieren zweier Zahlen ausführen, erfolgt die Addition (die „Verarbeitung“) an einem Logikgatter im Prozessor.
In einer CPU gemäß der Von-Neumann-Architektur wird beim Addieren von zwei Zahlen ein einziger Additionsbefehl für zwei Zahlen im Schaltkreis ausgeführt. Für den Bruchteil dieser Millisekunde wurde im (Ausführungs-)Kern der Verarbeitungseinheit nur der Additionsbefehl ausgeführt! Dieses Detail hat mich schon immer fasziniert.
Kern in einer modernen CPU
Die Komponenten im obigen Diagramm sind selbsterklärend. Weitere Einzelheiten und eine ausführliche Erklärung finden Sie in diesem hervorragenden . In modernen CPUs kann ein einzelner physischer Kern mehr als eine Integer-ALU, Gleitkomma-ALU usw. enthalten. Auch diese Einheiten sind physische Logikgatter.
Um GPU besser einschätzen zu können, müssen wir den „Hardware-Thread“ im CPU-Kern verstehen. Ein Hardware-Thread ist eine Recheneinheit, die in Ausführungseinheiten eines CPU-Kerns in jedem einzelnen CPU-Taktzyklus ausgeführt werden kann . Er stellt die kleinste Arbeitseinheit dar, die in einem Kern ausgeführt werden kann.
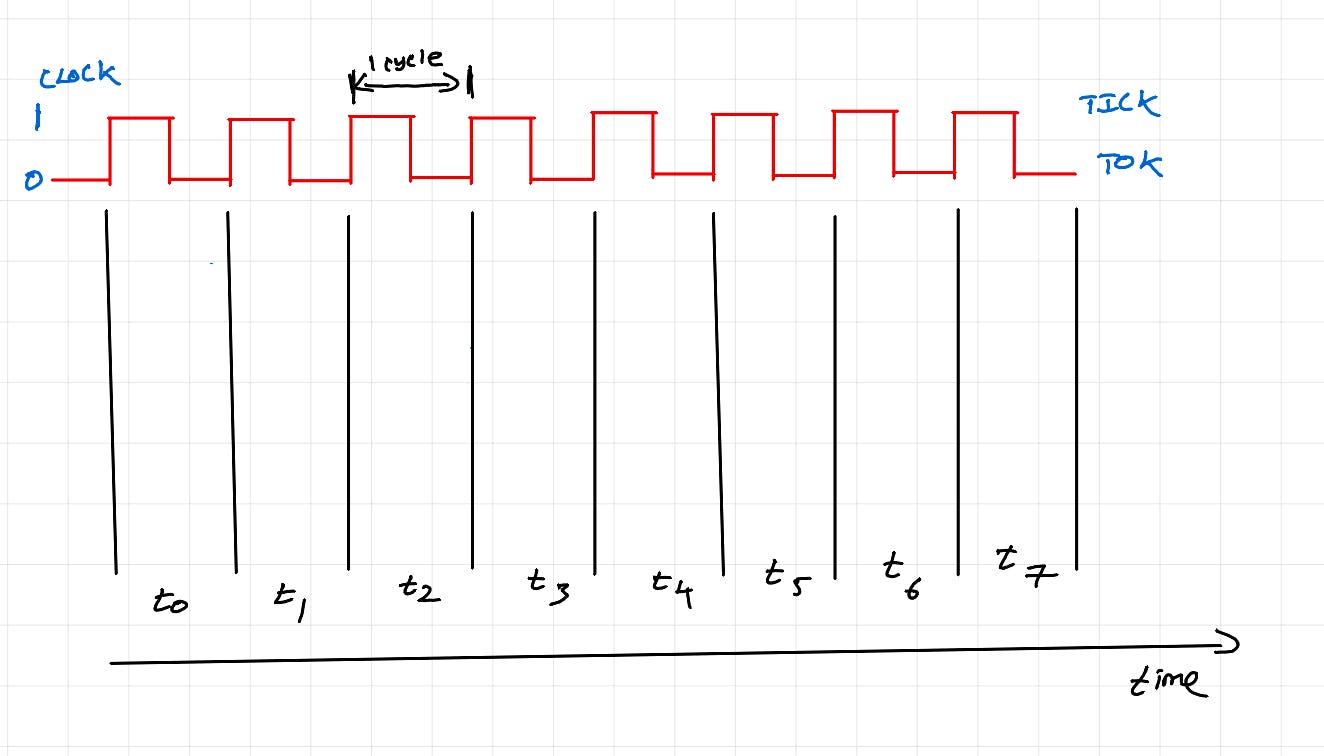
Unterrichtszyklus
Das obige Diagramm veranschaulicht den CPU-Befehlszyklus/Maschinenzyklus. Es handelt sich dabei um eine Reihe von Schritten, die die CPU durchführt, um einen einzelnen Befehl auszuführen (z. B.: c=a+b).
Fetch: Der Programmzähler (spezielles Register im CPU-Kern) verfolgt, welche Anweisungen abgerufen werden müssen. Anweisungen werden abgerufen und im Befehlsregister gespeichert. Für einfache Operationen werden auch entsprechende Daten abgerufen.
Decodierung: Die Anweisung wird decodiert, um Operatoren und Operanden anzuzeigen.
Ausführen: Basierend auf der angegebenen Operation wird die entsprechende Verarbeitungseinheit ausgewählt und ausgeführt.
Speicherzugriff: Wenn eine Anweisung komplex ist oder zusätzliche Daten benötigt werden (mehrere Faktoren können dies verursachen), erfolgt der Speicherzugriff vor der Ausführung. (Der Einfachheit halber wird dies im obigen Diagramm ignoriert.) Bei einer komplexen Anweisung sind die Anfangsdaten im Datenregister der Recheneinheit verfügbar, aber für die vollständige Ausführung der Anweisung ist ein Datenzugriff vom L1- und L2-Cache erforderlich. Dies bedeutet, dass möglicherweise eine kurze Wartezeit vergeht, bevor die Recheneinheit ausgeführt wird, und der Hardware-Thread hält die Recheneinheit während der Wartezeit noch fest.
Zurückschreiben: Wenn die Ausführung eine Ausgabe erzeugt (z. B.: c=a+b), wird die Ausgabe zurück in das Register/den Cache/den Speicher geschrieben. (Wird im obigen Diagramm oder an jeder anderen Stelle später im Beitrag der Einfachheit halber ignoriert)
Im obigen Diagramm wird nur zum Zeitpunkt t2 eine Berechnung durchgeführt. Den Rest der Zeit ist der Kern einfach im Leerlauf (wir erledigen keine Arbeit).
Moderne CPUs verfügen über Hardwarekomponenten, die grundsätzlich die gleichzeitige Ausführung von Schritten (Abrufen, Dekodieren, Ausführen) pro Taktzyklus ermöglichen.
Ein einzelner Hardware-Thread kann nun in jedem Taktzyklus Berechnungen durchführen. Dies wird als Instruction Pipelining bezeichnet.
Abrufen, Dekodieren, Speicherzugriff und Zurückschreiben werden von anderen Komponenten in einer CPU ausgeführt. In Ermangelung eines besseren Wortes werden diese als „Pipeline-Threads“ bezeichnet. Der Pipeline-Thread wird zu einem Hardware-Thread, wenn er sich in der Ausführungsphase eines Befehlszyklus befindet.
Wie Sie sehen, erhalten wir ab t2 in jedem Zyklus Rechenleistung. Zuvor erhielten wir alle 3 Zyklen Rechenleistung. Pipelining verbessert den Rechendurchsatz. Dies ist eine der Techniken zur Bewältigung von Verarbeitungsengpässen in der Von-Neumann-Architektur. Es gibt auch andere Optimierungen wie Out-of-Order-Ausführung, Verzweigungsvorhersage, spekulative Ausführung usw.
Hyper-Threading
Dies ist das letzte Konzept, das ich im Zusammenhang mit der CPU besprechen möchte, bevor wir zum Schluss kommen und zu den GPUs übergehen. Mit zunehmender Taktfrequenz wurden auch die Prozessoren schneller und effizienter. Mit zunehmender Komplexität der Anwendung (Befehlssatz) wurden die CPU-Rechenkerne nicht mehr ausreichend genutzt und es wurde mehr Zeit mit Warten auf den Speicherzugriff verbracht.
Wir sehen also einen Speicherengpass. Die Recheneinheit verbringt Zeit mit Speicherzugriffen und erledigt keine nützliche Arbeit. Der Speicher ist um mehrere Größenordnungen langsamer als die CPU und diese Lücke wird sich nicht so schnell schließen. Die Idee war, die Speicherbandbreite in einigen Einheiten eines einzelnen CPU-Kerns zu erhöhen und Daten für die Recheneinheiten bereitzuhalten, wenn sie auf Speicherzugriff warten.
Hyper-Threading wurde 2002 von Intel in Xeon- und Pentium-4-Prozessoren verfügbar gemacht. Vor Hyper-Threading gab es nur einen Hardware-Thread pro Kern. Mit Hyper-Threading gibt es 2 Hardware-Threads pro Kern. Was bedeutet das? Doppelte Verarbeitungsschaltung für einige Register, Programmzähler, Abrufeinheit, Decodiereinheit usw.
Das obige Diagramm zeigt nur neue Schaltungselemente in einem CPU-Kern mit Hyperthreading. So wird ein einzelner physischer Kern für das Betriebssystem als 2 Kerne angezeigt. Wenn Sie einen 4-Kern-Prozessor mit aktiviertem Hyperthreading hätten, würde dieser vom Betriebssystem als 8 Kerne angezeigt . Die Cachegröße von L1 bis L3 wird erhöht, um zusätzliche Register unterzubringen. Beachten Sie, dass die Ausführungseinheiten gemeinsam genutzt werden.
Angenommen, wir haben die Prozesse P1 und P2, die a=b+c, d=e+f ausführen. Diese können aufgrund der HW-Threads 1 und 2 gleichzeitig in einem einzigen Taktzyklus ausgeführt werden. Mit einem einzigen HW-Thread wäre dies, wie wir zuvor gesehen haben, nicht möglich. Hier erhöhen wir die Speicherbandbreite innerhalb eines Kerns, indem wir einen Hardware-Thread hinzufügen, sodass die Verarbeitungseinheit effizient genutzt werden kann. Dies verbessert die Rechenparallelität.
Einige interessante Szenarien:
- Die CPU hat nur eine ganzzahlige ALU. Ein HW-Thread 1 oder HW-Thread 2 muss einen Taktzyklus warten und im nächsten Zyklus mit der Berechnung fortfahren.
- Die CPU verfügt über eine Integer-ALU und eine Floating-Point-ALU. HW-Thread 1 und HW-Thread 2 können mithilfe von ALU bzw. FPU gleichzeitig Additionen durchführen.
- Alle verfügbaren ALUs werden von HW-Thread 1 genutzt. HW-Thread 2 muss warten, bis eine ALU verfügbar ist. (Gilt nicht für das obige Additionsbeispiel, kann aber bei anderen Anweisungen vorkommen).
Warum ist die CPU beim herkömmlichen Desktop-/Server-Computing so gut?
- Hohe Taktraten – Höher als die GPU-Taktraten. Durch die Kombination dieser hohen Geschwindigkeit mit der Befehlspipeline sind CPUs bei sequentiellen Aufgaben extrem gut. Optimiert für Latenz.
- Vielfältige Anwendungs- und Rechenanforderungen – Personalcomputer und Server haben ein breites Anwendungsspektrum und Rechenanforderungen. Dies führt zu einem komplexen Befehlssatz. Die CPU muss in mehreren Dingen gut sein.
- Multitasking und Multi-Processing – Bei so vielen Anwendungen auf unseren Computern erfordert die CPU-Arbeitslast Kontextwechsel. Caching-Systeme und Speicherzugriff sind so eingerichtet, dass sie dies unterstützen. Wenn ein Prozess im CPU-Hardware-Thread geplant ist, hat er alle erforderlichen Daten bereit und führt Rechenanweisungen schnell nacheinander aus.
CPU-Nachteile
Lesen Sie diesen und probieren Sie auch das aus. Es zeigt, dass die Matrizenmultiplikation eine parallelisierbare Aufgabe ist und wie parallele Rechenkerne die Berechnung beschleunigen können.
- Extrem gut bei sequenziellen Aufgaben, aber nicht gut bei parallelen Aufgaben.
- Komplexer Befehlssatz und komplexes Speicherzugriffsmuster.
- Die CPU verbraucht auch viel Energie für Kontextwechsel und Steuereinheitenaktivitäten zusätzlich zu der Berechnung
Die zentralen Thesen
- Durch die Anweisungspipeline wird der Rechendurchsatz verbessert.
- Eine Erhöhung der Speicherbandbreite verbessert die Rechenparallelität.
- CPUs eignen sich gut für sequentielle Aufgaben (optimiert für Latenz). Sie eignen sich nicht für massiv parallele Aufgaben, da hierfür eine große Anzahl von Recheneinheiten und Hardware-Threads erforderlich ist, die nicht verfügbar sind (nicht optimiert für Durchsatz). Diese sind nicht verfügbar, da CPUs für allgemeine Berechnungen ausgelegt sind und über komplexe Befehlssätze verfügen.
Grafikprozessoren
Mit der zunehmenden Rechenleistung stieg auch die Nachfrage nach Grafikverarbeitung. Aufgaben wie UI-Rendering und Gaming erfordern parallele Operationen, was den Bedarf an zahlreichen ALUs und FPUs auf Schaltkreisebene erhöht. CPUs, die für sequentielle Aufgaben entwickelt wurden, konnten diese parallelen Arbeitslasten nicht effektiv bewältigen. Daher wurden GPUs entwickelt, um die Nachfrage nach paralleler Verarbeitung bei Grafikaufgaben zu erfüllen, was später den Weg für ihre Einführung zur Beschleunigung von Deep-Learning-Algorithmen ebnete.
Ich kann es nur wärmstens empfehlen:
- Sehen Sie sich dieses an, in dem die parallelen Aufgaben beim Rendern von Videospielen erklärt werden.
- Lesen Sie diesen um die parallelen Aufgaben zu verstehen, die in einem Transformer enthalten sind. Es gibt auch andere Deep-Learning-Architekturen wie CNNs und RNNs. Da LLMs die Welt erobern, würde ein umfassendes Verständnis der Parallelität bei Matrixmultiplikationen, die für Transformer-Aufgaben erforderlich sind, einen guten Kontext für den Rest dieses Beitrags bieten. (Zu einem späteren Zeitpunkt plane ich, Transformer vollständig zu verstehen und einen verständlichen Überblick darüber zu geben, was in den Transformer-Schichten eines kleinen GPT-Modells passiert.)
Beispiel für CPU- und GPU-Spezifikationen
Kerne, Hardware-Threads, Taktfrequenz, Speicherbandbreite und On-Chip-Speicher von CPUs und GPUs unterscheiden sich erheblich. Beispiel:
- Intel Xeon 8280 :
- 2700 MHz Basis und 4000 MHz im Turbo
- 28 Kerne und 56 Hardware-Threads
- Gesamtzahl der Pipeline-Threads: 896 - 56
- L3-Cache: 38,5 MB (von allen Kernen gemeinsam genutzt) L2-Cache: 28,0 MB (aufgeteilt auf die Kerne) L1-Cache: 1,375 MB (aufgeteilt auf die Kerne)
- Die Registergröße ist nicht öffentlich verfügbar
- Max. Speicher: 1 TB DDR4, 2933 MHz, 6 Kanäle
- Max. Speicherbandbreite: 131 GB/s
- Spitzenleistung bei FP64 = 4,0 GHz 2 AVX-512-Einheiten 8 Operationen pro AVX-512-Einheit pro Taktzyklus * 28 Kerne = ~2,8 TFLOPs [Abgeleitet mithilfe von: Spitzenleistung bei FP64 = (Maximale Turbofrequenz) (Anzahl der AVX-512-Einheiten) (Operationen pro AVX-512-Einheit pro Taktzyklus) * (Anzahl der Kerne)]
Diese Zahl wird zum Vergleich mit der GPU verwendet, da das Erreichen der Spitzenleistung bei Allzweck-Computern sehr subjektiv ist. Diese Zahl ist eine theoretische Höchstgrenze, was bedeutet, dass FP64-Schaltkreise maximal genutzt werden.
- Nvidia A100 80 GB SXM :
- 1065 MHz Basis und 1410 MHz im Turbo
- 108 SMs, 64 FP32 CUDA-Kerne (auch SPs genannt) pro SM, 4 FP64 Tensor-Kerne pro SM, 68 Hardware-Threads (64 + 4) pro SM
- Insgesamt pro GPU: 6912 64 FP32 CUDA-Kerne, 432 FP 64 Tensor-Kerne, 7344 (6912 + 432) Hardware-Threads
- Pipeline-Threads pro SM: 2048 - 68 = 1980 pro SM
- Gesamtzahl der Pipeline-Threads pro GPU: (2048 x 108) - (68 x 108) = 21184 - 7344 = 13840
- Siehe:
- L2-Cache: 40 MB (gemeinsam genutzt für alle SMs) L1-Cache: 20,3 MB insgesamt (192 KB pro SM)
- Registergröße: 27,8 MB (256 KB pro SM)
- Max. GPU-Hauptspeicher: 80 GB HBM2e, 1512 MHz
- Max. GPU-Hauptspeicherbandbreite: 2,39 TB/s
- Spitzenleistung von FP64 = 19,5 TFLOPs [nur bei Verwendung aller FP64-Tensor-Kerne]. Der niedrigere Wert beträgt 9,7 TFLOPs, wenn nur FP64 in CUDA-Kernen verwendet wird. Diese Zahl ist eine theoretische Höchstgrenze, was bedeutet, dass FP64-Schaltkreise maximal genutzt werden.
Kern in einer modernen GPU
Die Terminologien, die wir bei CPUs gesehen haben, lassen sich nicht immer direkt auf GPUs übertragen. Hier sehen wir Komponenten und Kerne der NVIDIA A100 GPU. Bei der Recherche für diesen Artikel war ich überrascht, dass CPU-Anbieter nicht veröffentlichen, wie viele ALUs, FPUs usw. in den Ausführungseinheiten eines Kerns verfügbar sind. NVIDIA ist sehr transparent, was die Anzahl der Kerne angeht, und das CUDA-Framework bietet vollständige Flexibilität und Zugriff auf Schaltkreisebene.
Im obigen Diagramm in der GPU können wir sehen, dass es keinen L3-Cache, einen kleineren L2-Cache, einen kleineren, aber viel größeren Steuereinheiten- und L1-Cache und eine große Anzahl von Verarbeitungseinheiten gibt.
Hier sind die GPU-Komponenten in den obigen Diagrammen und ihr CPU-Äquivalent für unser erstes Verständnis. Ich habe noch keine CUDA-Programmierung durchgeführt, daher hilft der Vergleich mit CPU-Äquivalenten beim ersten Verständnis. CUDA-Programmierer verstehen dies sehr gut.
- Mehrere Streaming-Multiprozessoren <> Multi-Core-CPU
- Streaming-Multiprozessor (SM) <> CPU-Kern
- Streaming-Prozessor (SP)/ CUDA Core <> ALU / FPU in Ausführungseinheiten eines CPU-Cores
- Tensor Core (kann 4x4 FP64-Operationen mit einem einzigen Befehl ausführen) <> SIMD-Ausführungseinheiten in einem modernen CPU-Kern (z. B. AVX-512)
- Hardware-Thread (Berechnungen in CUDA- oder Tensor-Cores in einem einzigen Taktzyklus durchführen) <> Hardware-Thread (Berechnungen in Ausführungseinheiten [ALUs, FPUs usw.] in einem einzigen Taktzyklus durchführen)
- HBM / VRAM / DRAM / GPU-Speicher <> RAM
- On-Chip-Speicher/SRAM (Register, L1-, L2-Cache) <> On-Chip-Speicher/SRAM (Register, L1-, L2-, L3-Cache)
- Hinweis: Register in einem SM sind deutlich größer als Register in einem Kern. Wegen der hohen Anzahl an Threads. Denken Sie daran, dass wir beim Hyper-Threading in der CPU eine Zunahme der Registeranzahl, aber nicht der Recheneinheiten festgestellt haben. Gleiches Prinzip hier.
Verschieben von Daten und Speicherbandbreite
Grafik- und Deep-Learning-Aufgaben erfordern eine Ausführung vom Typ SIM(D/T) [Single Instruction Multi Data/Thread]. Das bedeutet, dass mit einer einzigen Anweisung große Datenmengen gelesen und bearbeitet werden müssen.
Wir haben besprochen, dass auch Befehlspipelines und Hyperthreading in CPUs und GPUs möglich sind. Die Implementierung und Funktionsweise unterscheiden sich geringfügig, aber die Prinzipien sind dieselben.
Im Gegensatz zu CPUs bieten GPUs (über CUDA) direkten Zugriff auf Pipeline-Threads (Daten aus dem Speicher abrufen und die Speicherbandbreite nutzen). GPU-Scheduler arbeiten zunächst, indem sie versuchen, Recheneinheiten (einschließlich des zugehörigen gemeinsam genutzten L1-Cache und Register zum Speichern von Rechenoperanden) zu füllen, dann „Pipeline-Threads“, die Daten in Register und HBM abrufen. Ich möchte noch einmal betonen, dass CPU-App-Programmierer nicht darüber nachdenken und Spezifikationen zu „Pipeline-Threads“ und der Anzahl der Recheneinheiten pro Kern nicht veröffentlicht werden. Nvidia veröffentlicht diese nicht nur, sondern bietet Programmierern auch vollständige Kontrolle.
Ich werde in einem speziellen Beitrag über das CUDA-Programmiermodell und die „Batching“-Technik bei der Modellbereitstellungsoptimierung näher darauf eingehen und dort zeigen, wie vorteilhaft dies ist.
Das obige Diagramm zeigt die Ausführung von Hardware-Threads im CPU- und GPU-Kern. Siehe den Abschnitt „Speicherzugriff“, den wir zuvor bei CPU-Pipelining besprochen haben. Dieses Diagramm zeigt das. Die komplexe Speicherverwaltung der CPU macht diese Wartezeit klein genug (einige Taktzyklen), um Daten aus dem L1-Cache in Register zu holen. Wenn Daten aus L3 oder dem Hauptspeicher geholt werden müssen, erhält der andere Thread, für den sich Daten bereits im Register befinden (wir haben dies im Abschnitt zum Hyper-Threading gesehen), die Kontrolle über die Ausführungseinheiten.
Aufgrund der Überbuchung (hohe Anzahl von Pipeline-Threads und Registern) und des einfachen Befehlssatzes sind in GPUs bereits große Datenmengen in Registern verfügbar, die auf ihre Ausführung warten. Diese auf ihre Ausführung wartenden Pipeline-Threads werden zu Hardware-Threads und führen die Ausführung in jedem Taktzyklus aus, da Pipeline-Threads in GPUs leichtgewichtig sind.
Bandbreite, Rechenintensität und Latenz
Was ist über dem Ziel?
- Nutzen Sie die Hardwareressourcen (Recheneinheiten) in jedem Taktzyklus voll aus, um das Beste aus der GPU herauszuholen.
- Um die Recheneinheiten beschäftigt zu halten, müssen wir ihnen genügend Daten zuführen.
Dies ist der Hauptgrund, warum die Latenz der Matrixmultiplikation kleinerer Matrizen bei CPU und GPU mehr oder weniger gleich ist. .
Aufgaben müssen parallel genug sein, die Daten müssen groß genug sein, um Rechen-FLOPs und Speicherbandbreite auszulasten. Wenn eine einzelne Aufgabe nicht groß genug ist, müssen mehrere solcher Aufgaben gepackt werden, um Speicher und Rechenleistung auszulasten und die Hardware voll auszunutzen.
Rechenintensität = FLOPs/Bandbreite , d. h. das Verhältnis der Arbeitsmenge, die von den Recheneinheiten pro Sekunde erledigt werden kann, zur Datenmenge, die vom Speicher pro Sekunde bereitgestellt werden kann.
Im obigen Diagramm sehen wir, dass die Rechenintensität zunimmt, wenn wir zu höherer Latenz und geringerer Speicherbandbreite übergehen. Wir möchten, dass diese Zahl so klein wie möglich ist, damit die Rechenleistung voll ausgenutzt wird. Dafür müssen wir so viele Daten wie möglich in L1/Registern behalten, damit die Berechnung schnell erfolgen kann. Wenn wir einzelne Daten von HBM abrufen, gibt es nur wenige Operationen, bei denen wir 100 Operationen an einzelnen Daten durchführen, damit es sich lohnt. Wenn wir keine 100 Operationen durchführen, sind die Recheneinheiten im Leerlauf. Hier kommt die hohe Anzahl von Threads und Registern in GPUs ins Spiel. Um so viele Daten wie möglich in L1/Registern zu behalten, müssen die Rechenintensität niedrig gehalten und parallele Kerne ausgelastet werden.
Es besteht ein vierfacher Unterschied in der Rechenintensität zwischen CUDA- und Tensor-Kernen, da CUDA-Kerne nur einen 1x1 FP64 MMA ausführen können, während Tensor-Kerne 4x4 FP64 MMA-Befehle pro Taktzyklus ausführen können.
Die zentralen Thesen
Eine hohe Anzahl an Recheneinheiten (CUDA- und Tensor-Kerne), eine hohe Anzahl an Threads und Registern (über Abonnement), ein reduzierter Befehlssatz, kein L3-Cache, HBM (SRAM), ein einfaches und hochdurchsatzstarkes Speicherzugriffsmuster (im Vergleich zu CPUs – Kontextwechsel, mehrschichtiges Caching, Speicher-Paging, TLB usw.) sind die Prinzipien, die GPUs beim parallelen Rechnen (Grafik-Rendering, Deep Learning usw.) so viel besser machen als CPUs.
Über GPUs hinaus
GPUs wurden ursprünglich für die Verarbeitung von Grafikverarbeitungsaufgaben entwickelt. KI-Forscher begannen, CUDA und seinen direkten Zugriff auf leistungsstarke Parallelverarbeitung über CUDA-Kerne zu nutzen. NVIDIA GPU verfügt über Texture Processing, Ray Tracing, Raster, Polymorph-Engines usw. (sagen wir, grafikspezifische Befehlssätze). Mit der zunehmenden Verbreitung von KI werden Tensor-Kerne hinzugefügt, die sich gut für 4x4-Matrixberechnungen (MMA-Befehle) eignen und speziell für Deep Learning entwickelt wurden.
Seit 2017 hat NVIDIA die Anzahl der Tensor-Kerne in jeder Architektur erhöht. Diese GPUs eignen sich jedoch auch gut für die Grafikverarbeitung. Obwohl der Befehlssatz und die Komplexität bei GPUs viel geringer sind, sind sie nicht vollständig auf Deep Learning ausgerichtet (insbesondere Transformer Architecture).
, eine Softwareschichtoptimierung (mechanische Sympathie für das Speicherzugriffsmuster der Aufmerksamkeitsschicht) für die Transformer-Architektur, sorgt für eine Verdoppelung der Aufgabenbeschleunigung.
Mit unserem tiefgreifenden, auf Grundprinzipien basierenden Verständnis von CPU und GPU können wir die Notwendigkeit von Transformer-Beschleunigern verstehen: Ein dedizierter Chip (Schaltkreis nur für Transformer-Operationen), mit noch mehr Recheneinheiten für Parallelität, reduziertem Befehlssatz, keine L1/L2-Caches, massiver DRAM (Register) als Ersatz für HBM, Speichereinheiten, die für das Speicherzugriffsmuster der Transformer-Architektur optimiert sind. Schließlich sind LLMs neue Begleiter für Menschen (nach Web und Mobile) und sie benötigen dedizierte Chips für Effizienz und Leistung.
Einige KI-Beschleuniger:
Transformatorbeschleuniger:
FPGA-basierte Transformer-Beschleuniger:
Verweise:
- Wie funktionieren Videospielgrafiken? -
- CPU vs. GPU vs. TPU vs. DPU vs. QPU -
- So funktioniert GPU-Computing | GTC 2021 | Stephen Jones -
- Rechenintensität -
- So funktioniert CUDA-Programmierung | GTC Fall 2022 | Stephen Jones -
- Warum GPU mit neuronalen Netzwerken verwenden? -
- CUDA-Hardware | Tom Nurkkala | Vorlesung an der Taylor University -
L O A D I N G
. . . comments & more!
. . . comments & more!



