























































Jan 01, 1970
701 lượt đọc
Tổng quan cấp cao dễ hiểu về khả năng của CPU và GPU
dài quá đọc không nổi
Bài viết đi sâu vào những khác biệt cốt lõi giữa CPU và GPU trong việc xử lý các tác vụ tính toán song song, bao gồm các khái niệm như Kiến trúc Von Neumann, Siêu phân luồng và Đường dẫn lệnh. Nó giải thích sự phát triển của GPU từ bộ xử lý đồ họa đến các công cụ mạnh mẽ để tăng tốc các thuật toán học sâu.Tổng quan cấp cao dễ hiểu về những gì xảy ra trong The Die
Trong bài viết này, chúng ta sẽ điểm qua một số chi tiết cơ bản ở cấp độ thấp để hiểu lý do tại sao GPU hoạt động tốt trong các tác vụ Đồ họa, Mạng thần kinh và Học sâu và CPU lại thực hiện tốt nhiều tác vụ tính toán cho mục đích chung phức tạp, tuần tự. Có một số chủ đề mà tôi phải nghiên cứu và hiểu chi tiết hơn một chút cho bài đăng này, một số chủ đề trong số đó tôi sẽ chỉ đề cập sơ qua. Nó được thực hiện có chủ ý để chỉ tập trung vào những điều cơ bản tuyệt đối về xử lý CPU & GPU.
Kiến trúc Von Neumann
Các máy tính trước đó là thiết bị chuyên dụng. Các mạch phần cứng và cổng logic được lập trình để thực hiện một số công việc cụ thể. Nếu cần phải làm điều gì đó mới thì các mạch điện cần phải được nối lại. “Một cái gì đó mới” có thể đơn giản như thực hiện các phép tính toán học cho hai phương trình khác nhau. Trong Thế chiến thứ hai, Alan Turing đang nghiên cứu một chiếc máy có thể lập trình để đánh bại máy Enigma và sau đó đã xuất bản bài báo "Máy Turing". Cùng lúc đó, John von Neumann và các nhà nghiên cứu khác cũng đang nghiên cứu một ý tưởng về cơ bản được đề xuất:
- Lệnh và dữ liệu phải được lưu trữ trong bộ nhớ dùng chung (Chương trình được lưu trữ).
- Các đơn vị xử lý và bộ nhớ phải tách biệt.
- Bộ điều khiển đảm nhiệm việc đọc dữ liệu và hướng dẫn từ bộ nhớ để thực hiện các phép tính bằng bộ xử lý.
Nút cổ chai
- Nút cổ chai xử lý - Tại một thời điểm, chỉ có thể có một lệnh và toán hạng của nó trong một đơn vị xử lý (cổng logic vật lý). Các lệnh được thực hiện tuần tự lần lượt. Trong những năm qua, chúng tôi đã tập trung và cải tiến để làm cho bộ xử lý nhỏ hơn, chu kỳ xung nhịp nhanh hơn và tăng số lượng lõi.
- Nút cổ chai bộ nhớ - Khi bộ xử lý ngày càng phát triển nhanh hơn, tốc độ và lượng dữ liệu có thể được truyền giữa bộ nhớ và bộ xử lý trở thành nút cổ chai. Bộ nhớ chậm hơn vài lệnh so với CPU. Trong những năm qua, trọng tâm và cải tiến là làm cho bộ nhớ dày đặc hơn và nhỏ hơn.
CPU
Chúng tôi biết rằng mọi thứ trong máy tính của chúng tôi đều là nhị phân. Chuỗi, hình ảnh, video, âm thanh, hệ điều hành, chương trình ứng dụng, v.v., đều được biểu diễn dưới dạng 1 và 0. Các thông số kỹ thuật của kiến trúc CPU (RISC, CISC, v.v.) có các bộ hướng dẫn (x86, x86-64, ARM, v.v.), mà các nhà sản xuất CPU phải tuân thủ và có sẵn để hệ điều hành giao tiếp với phần cứng.
Các chương trình ứng dụng và hệ điều hành bao gồm dữ liệu được dịch thành tập lệnh và dữ liệu nhị phân để xử lý trong CPU. Ở cấp độ chip, quá trình xử lý được thực hiện tại các bóng bán dẫn và cổng logic. Nếu bạn thực hiện một chương trình để cộng hai số, phép cộng ("xử lý") được thực hiện tại cổng logic trong bộ xử lý.
Trong CPU theo kiến trúc Von Neumann, khi chúng ta cộng hai số, một lệnh cộng duy nhất sẽ chạy trên hai số trong mạch. Trong một phần của mili giây đó, chỉ có lệnh thêm được thực thi trong lõi (thực thi) của đơn vị xử lý! Chi tiết này luôn mê hoặc tôi.
Lõi trong CPU hiện đại
Các thành phần trong sơ đồ trên là hiển nhiên. Để biết thêm chi tiết và giải thích chi tiết, hãy tham khảo xuất sắc này. Trong các CPU hiện đại, một lõi vật lý có thể chứa nhiều ALU số nguyên, ALU dấu phẩy động, v.v.. Một lần nữa, các đơn vị này là các cổng logic vật lý.
Chúng ta cần hiểu rõ “Luồng phần cứng” trong lõi CPU để đánh giá GPU tốt hơn. Luồng phần cứng là một đơn vị tính toán có thể được thực hiện trong các đơn vị thực thi của lõi CPU, trong mỗi chu kỳ xung nhịp của CPU . Nó đại diện cho đơn vị công việc nhỏ nhất có thể được thực thi trong lõi.
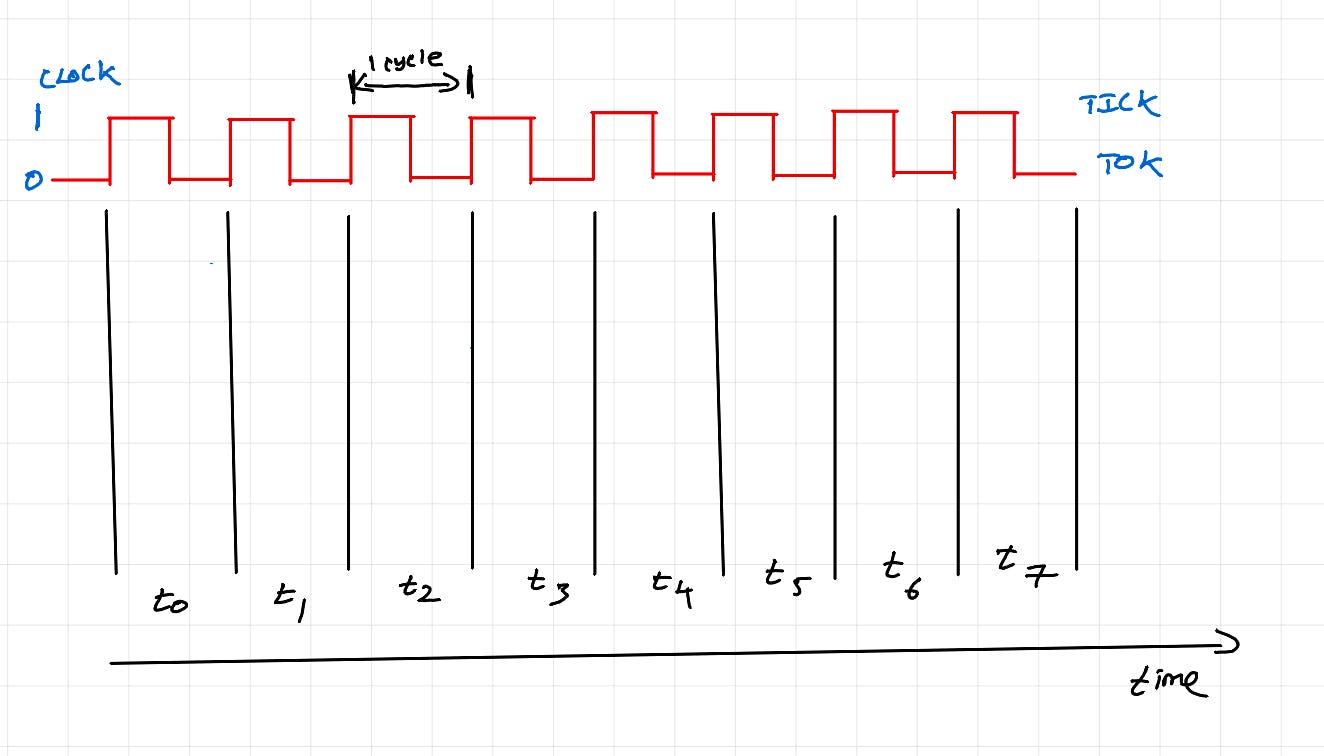
Chu kỳ hướng dẫn
Sơ đồ trên minh họa chu trình lệnh/chu trình máy của CPU. Đó là một chuỗi các bước mà CPU thực hiện để thực hiện một lệnh đơn (ví dụ: c=a+b).
Tìm nạp: Bộ đếm chương trình (thanh ghi đặc biệt trong lõi CPU) theo dõi lệnh nào phải được tìm nạp. Lệnh được lấy và lưu trữ trong thanh ghi lệnh. Đối với các thao tác đơn giản, dữ liệu tương ứng cũng được tìm nạp.
Giải mã: Lệnh được giải mã để xem các toán tử và toán hạng.
Thực thi: Dựa trên hoạt động được chỉ định, đơn vị xử lý thích hợp được chọn và thực thi.
Truy cập bộ nhớ: Nếu một lệnh phức tạp hoặc cần thêm dữ liệu (một số yếu tố có thể gây ra điều này), việc truy cập bộ nhớ sẽ được thực hiện trước khi thực hiện. (Bỏ qua trong sơ đồ trên để đơn giản). Đối với một lệnh phức tạp, dữ liệu ban đầu sẽ có sẵn trong thanh ghi dữ liệu của đơn vị tính toán, nhưng để thực hiện đầy đủ lệnh, cần phải truy cập dữ liệu từ bộ nhớ đệm L1 & L2. Điều này có nghĩa là có thể mất một khoảng thời gian chờ ngắn trước khi đơn vị điện toán thực thi và luồng phần cứng vẫn giữ đơn vị điện toán trong thời gian chờ.
Ghi lại: Nếu quá trình thực thi tạo ra đầu ra (ví dụ: c=a+b), đầu ra sẽ được ghi lại vào thanh ghi/bộ đệm/bộ nhớ. (Bỏ qua trong sơ đồ trên hoặc bất kỳ vị trí nào sau này trong bài viết để đơn giản)
Trong sơ đồ trên, chỉ tại t2 việc tính toán mới được thực hiện. Thời gian còn lại, lõi chỉ ở trạng thái rảnh (chúng tôi không hoàn thành công việc nào).
Các CPU hiện đại có các thành phần CTNH về cơ bản cho phép các bước (tìm nạp-giải mã-thực thi) diễn ra đồng thời trên mỗi chu kỳ xung nhịp.
Một luồng phần cứng hiện có thể thực hiện tính toán trong mỗi chu kỳ xung nhịp. Điều này được gọi là đường dẫn hướng dẫn.
Tìm nạp, giải mã, truy cập bộ nhớ và ghi lại được thực hiện bởi các thành phần khác trong CPU. Vì thiếu từ hay hơn nên chúng được gọi là "luồng đường ống". Luồng đường ống trở thành luồng phần cứng khi nó ở giai đoạn thực thi của chu kỳ lệnh.
Như bạn có thể thấy, chúng tôi nhận được đầu ra tính toán mỗi chu kỳ từ t2. Trước đây, cứ 3 chu kỳ chúng tôi lại nhận được kết quả điện toán. Pipeline cải thiện thông lượng tính toán. Đây là một trong những kỹ thuật quản lý tắc nghẽn xử lý trong Kiến trúc Von Neumann. Ngoài ra còn có các tối ưu hóa khác như thực thi không theo thứ tự, dự đoán nhánh, thực thi suy đoán, v.v.
Siêu phân luồng
Đây là khái niệm cuối cùng tôi muốn thảo luận về CPU trước khi kết luận và chuyển sang GPU. Khi tốc độ xung nhịp tăng lên, bộ xử lý cũng nhanh hơn và hiệu quả hơn. Với sự gia tăng độ phức tạp của ứng dụng (tập lệnh), các lõi tính toán của CPU không được sử dụng đúng mức và phải mất nhiều thời gian hơn để chờ truy cập bộ nhớ.
Vì vậy, chúng tôi thấy có một nút cổ chai về bộ nhớ. Đơn vị tính toán đang dành thời gian truy cập bộ nhớ và không thực hiện bất kỳ công việc hữu ích nào. Bộ nhớ chậm hơn CPU vài đơn hàng và khoảng cách sẽ không sớm thu hẹp lại. Ý tưởng là tăng băng thông bộ nhớ trong một số đơn vị của một lõi CPU và giữ cho dữ liệu luôn sẵn sàng để sử dụng các đơn vị tính toán khi nó đang chờ truy cập bộ nhớ.
Siêu phân luồng được Intel cung cấp vào năm 2002 trong bộ xử lý Xeon & Pentium 4. Trước khi có siêu phân luồng, chỉ có một luồng phần cứng trên mỗi lõi. Với siêu phân luồng, sẽ có 2 luồng phần cứng trên mỗi lõi. Nó có nghĩa là gì? Mạch xử lý trùng lặp cho một số thanh ghi, bộ đếm chương trình, bộ tìm nạp, bộ giải mã, v.v.
Sơ đồ trên chỉ hiển thị các phần tử mạch mới trong lõi CPU có siêu phân luồng. Đây là cách một lõi vật lý duy nhất được hiển thị dưới dạng 2 lõi đối với Hệ điều hành. Nếu bạn có bộ xử lý 4 lõi, có bật tính năng siêu phân luồng thì hệ điều hành sẽ coi đó là 8 lõi . Kích thước bộ đệm L1 - L3 sẽ tăng lên để chứa các thanh ghi bổ sung. Lưu ý rằng các đơn vị thực thi được chia sẻ.
Giả sử chúng ta có các tiến trình P1 và P2 thực hiện a=b+c, d=e+f, những tiến trình này có thể được thực thi đồng thời trong một chu kỳ xung nhịp nhờ các luồng CTNH 1 và 2. Với một luồng CTNH duy nhất, như chúng ta đã thấy trước đó, điều này sẽ không thể thực hiện được. Ở đây, chúng tôi đang tăng băng thông bộ nhớ trong lõi bằng cách thêm Chuỗi phần cứng để đơn vị xử lý có thể được sử dụng hiệu quả. Điều này cải thiện khả năng tính toán đồng thời.
Một số tình huống thú vị:
- CPU chỉ có một ALU nguyên. Một HW Thread 1 hoặc HW Thread 2 phải đợi một chu kỳ xung nhịp và tiến hành tính toán trong chu kỳ tiếp theo.
- CPU có một ALU số nguyên và một ALU dấu phẩy động. HW Thread 1 và HW Thread 2 có thể thực hiện phép cộng đồng thời bằng cách sử dụng ALU và FPU tương ứng.
- Tất cả các ALU có sẵn đang được HW Thread 1 sử dụng. HW Thread 2 phải đợi cho đến khi ALU có sẵn. (Không áp dụng cho ví dụ bổ sung ở trên nhưng có thể xảy ra với các hướng dẫn khác).
Tại sao CPU lại có khả năng tính toán máy tính để bàn/máy chủ truyền thống tốt đến vậy?
- Tốc độ xung nhịp cao - Cao hơn tốc độ xung nhịp GPU. Kết hợp tốc độ cao này với hệ thống dẫn lệnh, CPU thực hiện các tác vụ tuần tự cực kỳ tốt. Tối ưu hóa cho độ trễ.
- Ứng dụng và nhu cầu tính toán đa dạng - Máy tính cá nhân và máy chủ có rất nhiều ứng dụng và nhu cầu tính toán. Điều này dẫn đến một tập lệnh phức tạp. CPU phải giỏi một số thứ.
- Đa nhiệm & Đa xử lý - Với rất nhiều ứng dụng trong máy tính của chúng ta, khối lượng công việc của CPU yêu cầu chuyển đổi ngữ cảnh. Hệ thống bộ nhớ đệm và quyền truy cập bộ nhớ được thiết lập để hỗ trợ việc này. Khi một quy trình được lên lịch trong luồng phần cứng CPU, nó có sẵn tất cả dữ liệu cần thiết và thực hiện nhanh chóng từng lệnh tính toán.
Hạn chế của CPU
Hãy xem này và dùng thử . Nó cho thấy phép nhân ma trận là một nhiệm vụ có thể song song như thế nào và các lõi tính toán song song có thể tăng tốc độ tính toán như thế nào.
- Cực kỳ giỏi ở các nhiệm vụ tuần tự nhưng không giỏi ở các nhiệm vụ song song.
- Tập lệnh phức tạp và mẫu truy cập bộ nhớ phức tạp.
- CPU cũng tiêu tốn nhiều năng lượng cho việc chuyển đổi ngữ cảnh và các hoạt động của đơn vị điều khiển bên cạnh việc tính toán
Bài học chính
- Đường ống hướng dẫn cải thiện thông lượng tính toán.
- Tăng băng thông bộ nhớ giúp cải thiện khả năng tính toán đồng thời.
- CPU thực hiện tốt các tác vụ tuần tự (được tối ưu hóa cho độ trễ). Không giỏi thực hiện các tác vụ song song ồ ạt vì nó cần một số lượng lớn các đơn vị tính toán và luồng phần cứng không có sẵn (không được tối ưu hóa cho thông lượng). Những thứ này không có sẵn vì CPU được xây dựng cho mục đích tính toán đa năng và có các tập lệnh phức tạp.
GPU
Khi sức mạnh tính toán tăng lên, nhu cầu xử lý đồ họa cũng tăng theo. Các tác vụ như hiển thị giao diện người dùng và chơi trò chơi yêu cầu hoạt động song song, dẫn đến nhu cầu về nhiều ALU và FPU ở cấp độ mạch. CPU, được thiết kế cho các tác vụ tuần tự, không thể xử lý các khối lượng công việc song song này một cách hiệu quả. Do đó, GPU được phát triển để đáp ứng nhu cầu xử lý song song trong các tác vụ đồ họa, sau này mở đường cho việc áp dụng chúng trong việc tăng tốc các thuật toán học sâu.
Tôi rất muốn giới thiệu:
- Xem này giải thích các tác vụ song song liên quan đến kết xuất Trò chơi điện tử.
- Đọc này để hiểu các nhiệm vụ song song liên quan đến máy biến áp. Ngoài ra còn có các kiến trúc deep learning khác như CNN và RNN. Vì LLM đang chiếm lĩnh thế giới nên sự hiểu biết ở mức độ cao về tính song song trong phép nhân ma trận cần thiết cho các nhiệm vụ máy biến áp sẽ tạo bối cảnh tốt cho phần còn lại của bài đăng này. (Sau này, tôi dự định tìm hiểu đầy đủ về máy biến áp và chia sẻ tổng quan cấp cao dễ hiểu về những gì xảy ra trong các lớp máy biến áp của mô hình GPT nhỏ.)
Thông số kỹ thuật CPU và GPU mẫu
Lõi, luồng phần cứng, tốc độ xung nhịp, băng thông bộ nhớ và bộ nhớ trên chip của CPU và GPU khác nhau đáng kể. Ví dụ:
- Intel Xeon 8280 :
- 2700 MHz cơ sở và 4000 MHz ở Turbo
- 28 lõi và 56 luồng phần cứng
- Chủ đề đường ống tổng thể: 896 - 56
- Bộ đệm L3: 38,5 MB (được chia sẻ cho tất cả các lõi) Bộ đệm L2: 28,0 MB (được chia cho các lõi) Bộ đệm L1: 1,375 MB (được chia cho các lõi)
- Kích thước đăng ký không có sẵn công khai
- Bộ nhớ tối đa: 1TB DDR4, 2933 MHz, 6 kênh
- Băng thông bộ nhớ tối đa: 131 GB/s
- Hiệu suất cao nhất của FP64 = 4,0 GHz 2 đơn vị AVX-512 8 hoạt động trên mỗi đơn vị AVX-512 trên mỗi chu kỳ xung nhịp * 28 lõi = ~2,8 TFLOP [Dựa trên: Hiệu suất FP64 cao nhất = (Tần số Turbo tối đa) (Số lượng đơn vị AVX-512) ( Hoạt động trên mỗi đơn vị AVX-512 trên mỗi chu kỳ xung nhịp) * (Số lõi)]
Con số này được sử dụng để so sánh với GPU vì việc đạt được hiệu suất cao nhất của máy tính đa năng là rất chủ quan. Con số này là giới hạn tối đa về mặt lý thuyết, có nghĩa là các mạch FP64 đang được sử dụng tối đa.
- Nvidia A100 80GB SXM :
- Tần số cơ sở 1065 MHz và 1410 MHz ở Turbo
- 108 SM, 64 lõi CUDA FP32 (còn gọi là SP) trên mỗi SM, 4 lõi Tensor FP64 trên mỗi SM, 68 luồng phần cứng (64 + 4) trên mỗi SM
- Tổng thể trên mỗi GPU: 6912 64 lõi CUDA FP32, 432 FP 64 lõi Tensor, 7344 (6912 + 432) luồng phần cứng
- Chủ đề đường ống trên mỗi SM: 2048 - 68 = 1980 trên mỗi SM
- Các luồng đường dẫn tổng thể trên mỗi GPU: (2048 x 108) - (68 x 108) = 21184 - 7344 = 13840
- Tham khảo:
- Bộ đệm L2: 40 MB (được chia sẻ giữa tất cả các SM) Bộ đệm L1: tổng cộng 20,3 MB (192 KB mỗi SM)
- Kích thước đăng ký: 27,8 MB (256 KB mỗi SM)
- Bộ nhớ chính GPU tối đa: 80GB HBM2e, 1512 MHz
- Băng thông bộ nhớ chính GPU tối đa: 2,39 TB/s
- Hiệu suất cao nhất của FP64 = 19,5 TFLOP [chỉ sử dụng tất cả các lõi Tensor FP64]. Giá trị thấp hơn là 9,7 TFLOP khi chỉ sử dụng FP64 trong lõi CUDA. Con số này là giới hạn tối đa về mặt lý thuyết, có nghĩa là các mạch FP64 đang được sử dụng tối đa.
Lõi trong GPU hiện đại
Các thuật ngữ chúng ta thấy trong CPU không phải lúc nào cũng dịch trực tiếp sang GPU. Ở đây chúng ta sẽ thấy các thành phần và lõi GPU NVIDIA A100. Một điều khiến tôi ngạc nhiên khi nghiên cứu bài viết này là các nhà cung cấp CPU không công bố số lượng ALU, FPU, v.v., có sẵn trong các đơn vị thực thi của một lõi. NVIDIA rất minh bạch về số lượng lõi và khung CUDA mang lại sự linh hoạt và quyền truy cập hoàn toàn ở cấp độ mạch.
Trong sơ đồ trên về GPU, chúng ta có thể thấy rằng không có Bộ đệm L3, bộ đệm L2 nhỏ hơn, bộ điều khiển & bộ đệm L1 nhỏ hơn nhưng nhiều hơn và một số lượng lớn các đơn vị xử lý.
Dưới đây là các thành phần GPU trong sơ đồ trên và CPU tương đương của chúng theo hiểu biết ban đầu của chúng tôi. Tôi chưa thực hiện lập trình CUDA, vì vậy việc so sánh nó với CPU tương đương sẽ giúp hiểu rõ ban đầu. Các lập trình viên CUDA hiểu rất rõ điều này.
- Nhiều bộ xử lý đa luồng phát trực tuyến <> CPU đa lõi
- Bộ xử lý đa luồng (SM) <> CPU Core
- Bộ xử lý truyền phát (SP)/ Lõi CUDA <> ALU / FPU trong các đơn vị thực thi của Lõi CPU
- Tensor Core (có khả năng thực hiện các thao tác 4x4 FP64 trên một lệnh duy nhất) <> Các đơn vị thực thi SIMD trong lõi CPU hiện đại (ví dụ: AVX-512)
- Luồng phần cứng (thực hiện tính toán trong CUDA hoặc Tensor Cores trong một chu kỳ xung nhịp) <> Luồng phần cứng (thực hiện tính toán trong các đơn vị thực thi [ALU, FPU, v.v.] trong một chu kỳ xung nhịp)
- Bộ nhớ HBM / VRAM / DRAM / GPU <> RAM
- Bộ nhớ trên chip/SRAM (Thanh ghi, bộ đệm L1, L2) <> Bộ nhớ trên chip/SRAM (Thanh ghi, bộ đệm L1, L2, L3)
- Lưu ý: Các thanh ghi trong SM lớn hơn đáng kể so với các thanh ghi trong lõi. Vì số lượng chủ đề cao. Hãy nhớ rằng trong siêu phân luồng trong CPU, chúng ta đã thấy số lượng thanh ghi tăng lên nhưng không tăng đơn vị tính toán. Nguyên tắc tương tự ở đây.
Di chuyển dữ liệu và băng thông bộ nhớ
Các tác vụ đồ họa và deep learning yêu cầu thực thi kiểu SIM(D/T) [Single command multi data/thread]. tức là đọc và làm việc trên lượng lớn dữ liệu cho một lệnh.
Chúng tôi đã thảo luận về khả năng phân luồng lệnh và siêu phân luồng trong CPU và GPU. Cách thức triển khai và hoạt động hơi khác một chút nhưng nguyên tắc thì giống nhau.
Không giống như CPU, GPU (thông qua CUDA) cung cấp quyền truy cập trực tiếp vào Luồng đường ống (tìm nạp dữ liệu từ bộ nhớ và sử dụng băng thông bộ nhớ). Bộ lập lịch GPU hoạt động trước tiên bằng cách cố gắng lấp đầy các đơn vị điện toán (bao gồm bộ nhớ đệm L1 dùng chung liên quan và các thanh ghi để lưu trữ toán hạng điện toán), sau đó là "luồng đường ống" tìm nạp dữ liệu vào các thanh ghi và HBM. Một lần nữa, tôi muốn nhấn mạnh rằng các lập trình viên ứng dụng CPU không nghĩ đến điều này và các thông số kỹ thuật về "luồng đường ống" & số lượng đơn vị tính toán trên mỗi lõi không được công bố. Nvidia không chỉ xuất bản những thứ này mà còn cung cấp toàn quyền kiểm soát cho các lập trình viên.
Tôi sẽ đi sâu vào chi tiết hơn về vấn đề này trong một bài viết dành riêng về mô hình lập trình CUDA & "phân khối" trong kỹ thuật tối ưu hóa phân phát mô hình, nơi chúng ta có thể thấy điều này mang lại lợi ích như thế nào.
Sơ đồ trên mô tả việc thực thi luồng phần cứng trong lõi CPU & GPU. Tham khảo phần "truy cập bộ nhớ" mà chúng ta đã thảo luận trước đó trong quy trình xử lý CPU. Sơ đồ này cho thấy điều đó. Việc quản lý bộ nhớ phức tạp của CPU khiến thời gian chờ này đủ nhỏ (vài chu kỳ xung nhịp) để tìm nạp dữ liệu từ bộ đệm L1 đến các thanh ghi. Khi dữ liệu cần được tìm nạp từ L3 hoặc bộ nhớ chính, luồng khác có dữ liệu đã có trong thanh ghi (chúng ta đã thấy điều này trong phần siêu phân luồng) sẽ kiểm soát các đơn vị thực thi.
Trong GPU, do đăng ký quá mức (số lượng luồng và thanh ghi đường dẫn cao) & tập lệnh đơn giản, một lượng lớn dữ liệu đã có sẵn trên các thanh ghi đang chờ thực thi. Các luồng đường ống đang chờ thực thi này sẽ trở thành các luồng phần cứng và thực hiện việc thực thi thường xuyên trong mỗi chu kỳ xung nhịp vì các luồng đường ống trong GPU rất nhẹ.
Băng thông, cường độ tính toán và độ trễ
Vượt mục tiêu là gì?
- Tận dụng tối đa tài nguyên phần cứng (đơn vị tính toán) trong mỗi chu kỳ xung nhịp để tận dụng tối đa GPU.
- Để giữ cho các đơn vị tính toán luôn bận rộn, chúng ta cần cung cấp đủ dữ liệu cho nó.
Đây là lý do chính tại sao độ trễ của phép nhân ma trận của các ma trận nhỏ hơn ít nhiều giống nhau ở CPU & GPU. .
Các tác vụ cần phải đủ song song, dữ liệu cần đủ lớn để bão hòa FLOP tính toán và băng thông bộ nhớ. Nếu một tác vụ không đủ lớn thì nhiều tác vụ như vậy cần được đóng gói để làm bão hòa bộ nhớ và tính toán nhằm tận dụng tối đa phần cứng.
Cường độ tính toán = FLOP / Băng thông . tức là Tỷ lệ số lượng công việc có thể được thực hiện bởi các đơn vị tính toán mỗi giây với lượng dữ liệu có thể được bộ nhớ cung cấp mỗi giây.
Trong sơ đồ trên, chúng ta thấy rằng cường độ tính toán tăng lên khi chúng ta chuyển sang độ trễ cao hơn và bộ nhớ có băng thông thấp hơn. Chúng tôi muốn con số này càng nhỏ càng tốt để tính toán được tận dụng tối đa. Để làm được điều đó, chúng ta cần lưu giữ càng nhiều dữ liệu trong L1 / Thanh ghi để việc tính toán có thể diễn ra nhanh chóng. Nếu chúng tôi tìm nạp dữ liệu đơn lẻ từ HBM, chỉ có một số thao tác mà chúng tôi thực hiện 100 thao tác trên một dữ liệu để làm cho dữ liệu đó có giá trị. Nếu chúng tôi không thực hiện 100 thao tác, các đơn vị tính toán sẽ không hoạt động. Đây là nơi phát huy tác dụng của số lượng lớn luồng và thanh ghi trong GPU. Để giữ càng nhiều dữ liệu trong L1/Các thanh ghi nhằm giữ cường độ tính toán ở mức thấp và giữ cho các lõi song song luôn bận rộn.
Có sự khác biệt về cường độ tính toán 4X giữa lõi CUDA và lõi Tensor vì lõi CUDA chỉ có thể thực hiện một 1x1 FP64 MMA trong khi lõi Tensor có thể thực hiện lệnh MMA 4x4 FP64 trên mỗi chu kỳ xung nhịp.
Bài học chính
Số lượng đơn vị tính toán cao (lõi CUDA & Tensor), số lượng luồng và thanh ghi cao (đăng ký quá mức), tập lệnh giảm, không có bộ đệm L3, HBM (SRAM), mẫu truy cập bộ nhớ thông lượng cao và đơn giản (so với chuyển đổi ngữ cảnh của CPU , bộ nhớ đệm nhiều lớp, phân trang bộ nhớ, TLB, v.v.) là những nguyên tắc giúp GPU tốt hơn rất nhiều so với CPU trong tính toán song song (kết xuất đồ họa, học sâu, v.v.)
Ngoài GPU
GPU lần đầu tiên được tạo ra để xử lý các tác vụ xử lý đồ họa. Các nhà nghiên cứu AI bắt đầu tận dụng CUDA và khả năng truy cập trực tiếp của nó vào quá trình xử lý song song mạnh mẽ thông qua lõi CUDA. GPU NVIDIA có các công cụ Xử lý kết cấu, Truy tìm tia, Raster, Đa hình, v.v. (giả sử các bộ hướng dẫn dành riêng cho đồ họa). Với sự gia tăng áp dụng AI, các lõi Tensor có khả năng tính toán ma trận 4x4 tốt (lệnh MMA) đang được bổ sung để dành riêng cho việc học sâu.
Kể từ năm 2017, NVIDIA đã tăng số lượng lõi Tensor trong mỗi kiến trúc. Tuy nhiên, những GPU này cũng có khả năng xử lý đồ họa tốt. Mặc dù tập lệnh và độ phức tạp trong GPU ít hơn nhiều nhưng nó không hoàn toàn dành riêng cho deep learning (đặc biệt là Kiến trúc Transformer).
, một tính năng tối ưu hóa lớp phần mềm (sự đồng cảm cơ học với mẫu truy cập bộ nhớ của lớp chú ý) dành cho kiến trúc máy biến áp giúp tăng tốc các tác vụ lên gấp 2 lần.
Với hiểu biết sâu sắc dựa trên các nguyên tắc đầu tiên về CPU & GPU, chúng tôi có thể hiểu nhu cầu về Bộ tăng tốc máy biến áp: Một con chip chuyên dụng (mạch chỉ dành cho hoạt động của máy biến áp), với số lượng lớn các đơn vị tính toán để xử lý song song, giảm tập lệnh, không cần Bộ nhớ đệm L1/L2, DRAM (thanh ghi) lớn thay thế HBM, bộ nhớ được tối ưu hóa cho kiểu truy cập bộ nhớ của kiến trúc máy biến áp. Xét cho cùng, LLM là những người bạn đồng hành mới của con người (sau web và thiết bị di động) và họ cần chip chuyên dụng để đạt hiệu quả và hiệu suất.
Một số công cụ tăng tốc AI:
Máy gia tốc máy biến áp:
Máy gia tốc biến áp dựa trên FPGA:
Người giới thiệu:
- Đồ họa trò chơi điện tử hoạt động như thế nào? -
- CPU so với GPU so với TPU so với DPU so với QPU -
- Cách hoạt động của máy tính GPU | GTC 2021 | Stephen Jones -
- Cường độ tính toán -
- Lập trình CUDA hoạt động như thế nào | GTC Mùa thu 2022 | Stephen Jones -
- Tại sao nên sử dụng GPU với Mạng thần kinh? -
- Phần cứng CUDA | Tom Nurkkala | Bài giảng của Đại học Taylor -
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
chuyên mục
NHỮNG BÀI VIẾT LIÊN QUAN
85 Stories To Learn About Travel
#travel

223 Stories To Learn About Science #science
Jan 01, 1970

179 Stories To Learn About Reading #reading
Jan 01, 1970

