























































Jan 01, 1970
701 leituras
Uma visão geral resumida de alto nível dos recursos de CPU e GPU
Muito longo; Para ler
O artigo investiga as principais diferenças entre CPUs e GPUs no tratamento de tarefas de computação paralela, abordando conceitos como Arquitetura Von Neumann, Hyper-Threading e Pipelining de Instruções. Ele explica a evolução das GPUs, desde processadores gráficos até ferramentas poderosas para acelerar algoritmos de aprendizado profundo.Uma visão geral digerível de alto nível do que acontece em The Die
Neste artigo, examinaremos alguns detalhes fundamentais de baixo nível para entender por que as GPUs são boas em tarefas gráficas, redes neurais e aprendizado profundo e as CPUs são boas em um amplo número de tarefas de computação de uso geral complexas e sequenciais. Houve vários tópicos que tive que pesquisar e obter uma compreensão um pouco mais granular para este post, alguns dos quais mencionarei apenas de passagem. Isso é feito deliberadamente para focar apenas nos fundamentos absolutos do processamento de CPU e GPU.
Arquitetura Von Neumann
Os computadores anteriores eram dispositivos dedicados. Circuitos de hardware e portas lógicas foram programados para fazer um conjunto específico de coisas. Se algo novo tivesse que ser feito, os circuitos precisavam ser religados. “Algo novo” poderia ser tão simples quanto fazer cálculos matemáticos para duas equações diferentes. Durante a Segunda Guerra Mundial, Alan Turing estava trabalhando em uma máquina programável para vencer a máquina Enigma e mais tarde publicou o artigo "Máquina de Turing". Na mesma época, John von Neumann e outros pesquisadores também estavam trabalhando em uma ideia que propunha fundamentalmente:
- Instrução e dados devem ser armazenados em memória compartilhada (programa armazenado).
- As unidades de processamento e memória devem ser separadas.
- A unidade de controle cuida da leitura de dados e instruções da memória para fazer cálculos usando a unidade de processamento.
O Gargalo
- Gargalo de processamento - Apenas uma instrução e seu operando podem estar por vez em uma unidade de processamento (porta lógica física). As instruções são executadas sequencialmente, uma após a outra. Ao longo dos anos, o foco e as melhorias foram feitas para tornar os processadores menores, com ciclos de clock mais rápidos e aumentar o número de núcleos.
- Gargalo de memória - À medida que os processadores cresciam cada vez mais rápido, a velocidade e a quantidade de dados que podiam ser transferidos entre a memória e a unidade de processamento tornaram-se um gargalo. A memória é várias ordens mais lenta que a CPU. Ao longo dos anos, o foco e as melhorias têm sido tornar a memória mais densa e menor.
CPUs
Sabemos que tudo em nosso computador é binário. String, imagem, vídeo, áudio, sistema operacional, programa aplicativo, etc., são todos representados como 1s e 0s. As especificações da arquitetura da CPU (RISC, CISC, etc.) possuem conjuntos de instruções (x86, x86-64, ARM, etc.), que os fabricantes de CPU devem cumprir e estão disponíveis para o sistema operacional fazer interface com o hardware.
Os programas de sistema operacional e aplicativos, incluindo dados, são traduzidos em conjuntos de instruções e dados binários para processamento na CPU. No nível do chip, o processamento é feito em transistores e portas lógicas. Se você executar um programa para somar dois números, a adição (o "processamento") será feita em uma porta lógica do processador.
Na CPU, de acordo com a arquitetura Von Neumann, quando adicionamos dois números, uma única instrução de adição é executada em dois números no circuito. Por uma fração desse milissegundo, apenas a instrução add foi executada no núcleo (de execução) da unidade de processamento! Esse detalhe sempre me fascinou.
Núcleo em uma CPU moderna
Os componentes no diagrama acima são evidentes. Para mais detalhes e explicações detalhadas consulte este excelente . Nas CPUs modernas, um único núcleo físico pode conter mais de uma ALU inteira, ALU de ponto flutuante, etc. Novamente, essas unidades são portas lógicas físicas.
Precisamos entender o ‘Hardware Thread’ no núcleo da CPU para uma melhor apreciação da GPU. Um thread de hardware é uma unidade de computação que pode ser feita em unidades de execução de um núcleo de CPU, a cada ciclo de clock da CPU . Representa a menor unidade de trabalho que pode ser executada em um núcleo.
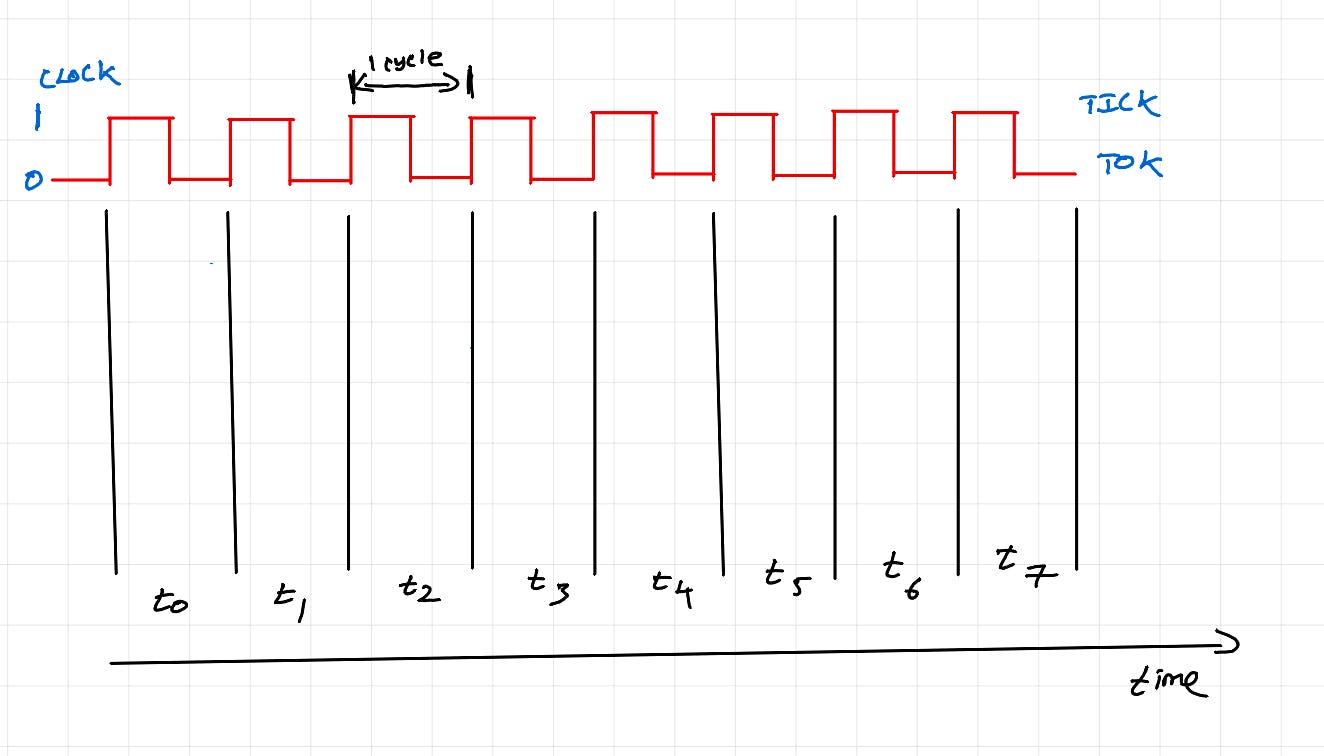
Ciclo de instrução
O diagrama acima ilustra o ciclo de instrução da CPU/ciclo de máquina. É uma série de etapas que a CPU executa para executar uma única instrução (ex.: c=a+b).
Fetch: O contador do programa (registro especial no núcleo da CPU) monitora quais instruções devem ser buscadas. A instrução é buscada e armazenada no registrador de instruções. Para operações simples, os dados correspondentes também são buscados.
Decodificar: a instrução é decodificada para ver operadores e operandos.
Executar: Com base na operação especificada, a unidade de processamento apropriada é escolhida e executada.
Acesso à memória: Se uma instrução for complexa ou forem necessários dados adicionais (vários fatores podem causar isso), o acesso à memória é feito antes da execução. (Ignorado no diagrama acima para simplificar). Para uma instrução complexa, os dados iniciais estarão disponíveis no registro de dados da unidade de computação, mas para a execução completa da instrução, é necessário o acesso aos dados do cache L1 e L2. Isso significa que pode haver um pequeno tempo de espera antes que a unidade de computação seja executada e o thread de hardware ainda retenha a unidade de computação durante o tempo de espera.
Write Back: Se a execução produzir saída (por exemplo: c = a + b), a saída será gravada de volta no registro/cache/memória. (Ignorado no diagrama acima ou em qualquer lugar posterior na postagem para simplificar)
No diagrama acima, apenas em t2 o cálculo está sendo feito. No resto do tempo, o núcleo fica ocioso (não estamos realizando nenhum trabalho).
CPUs modernas possuem componentes de HW que essencialmente permitem que etapas (buscar-decodificar-executar) ocorram simultaneamente por ciclo de clock.
Um único thread de hardware agora pode fazer cálculos em cada ciclo de clock. Isso é chamado de pipelining de instruções.
Buscar, decodificar, acessar a memória e gravar de volta são feitos por outros componentes em uma CPU. Por falta de uma palavra melhor, eles são chamados de “threads de pipeline”. O thread do pipeline se torna um thread de hardware quando está no estágio de execução de um ciclo de instrução.
Como você pode ver, obtemos resultados computacionais a cada ciclo de t2. Anteriormente, recebíamos saída de computação uma vez a cada 3 ciclos. O pipeline melhora o rendimento da computação. Esta é uma das técnicas para gerenciar gargalos de processamento na Arquitetura Von Neumann. Existem também outras otimizações, como execução fora de ordem, previsão de ramificação, execução especulativa, etc.,
Hiper-Threading
Este é o último conceito que quero discutir em CPU antes de concluirmos e passarmos para GPUs. À medida que a velocidade do clock aumentou, os processadores também ficaram mais rápidos e eficientes. Com o aumento da complexidade do aplicativo (conjunto de instruções), os núcleos de computação da CPU foram subutilizados e passaram mais tempo aguardando o acesso à memória.
Então, vemos um gargalo de memória. A unidade de computação está gastando tempo acessando a memória e não realizando nenhum trabalho útil. A memória é várias ordens mais lenta que a CPU e a lacuna não vai diminuir tão cedo. A ideia era aumentar a largura de banda da memória em algumas unidades de um único núcleo de CPU e manter os dados prontos para utilizar as unidades de computação quando aguardarem acesso à memória.
O Hyper-threading foi disponibilizado em 2002 pela Intel nos processadores Xeon e Pentium 4. Antes do hyper-threading, havia apenas um thread de hardware por núcleo. Com o hyper-threading, haverá 2 threads de hardware por núcleo. O que isso significa? Circuito de processamento duplicado para alguns registros, contador de programa, unidade de busca, unidade de decodificação, etc.
O diagrama acima mostra apenas novos elementos de circuito em um núcleo de CPU com hyperthreading. É assim que um único núcleo físico é visível como 2 núcleos para o sistema operacional. Se você tivesse um processador de 4 núcleos, com hyper-threading habilitado, ele seria visto pelo SO como 8 núcleos . O tamanho do cache L1 - L3 aumentará para acomodar registros adicionais. Observe que as unidades de execução são compartilhadas.
Suponha que temos processos P1 e P2 fazendo a=b+c, d=e+f, eles podem ser executados simultaneamente em um único ciclo de clock por causa dos threads de HW 1 e 2. Com um único thread de HW, como vimos anteriormente, isso não seria possível. Aqui estamos aumentando a largura de banda da memória dentro de um núcleo adicionando Thread de Hardware para que a unidade de processamento possa ser utilizada de forma eficiente. Isso melhora a simultaneidade de computação.
Alguns cenários interessantes:
- A CPU possui apenas uma ALU inteira. Um HW Thread 1 ou HW Thread 2 deve aguardar um ciclo de clock e prosseguir com a computação no próximo ciclo.
- A CPU possui uma ALU inteira e uma ALU de ponto flutuante. HW Thread 1 e HW Thread 2 podem fazer adição simultaneamente usando ALU e FPU respectivamente.
- Todas as ALUs disponíveis estão sendo utilizadas pelo HW Thread 1. HW Thread 2 deve esperar até que a ALU esteja disponível. (Não aplicável ao exemplo de adição acima, mas pode acontecer com outras instruções).
Por que a CPU é tão boa na computação tradicional de desktop/servidor?
- Altas velocidades de clock - Maiores que as velocidades de clock da GPU. Combinando essa alta velocidade com o pipeline de instruções, as CPUs são extremamente boas em tarefas sequenciais. Otimizado para latência.
- Diversas aplicações e necessidades de computação - Os computadores pessoais e servidores têm uma ampla gama de aplicações e necessidades de computação. Isso resulta em um conjunto de instruções complexo. A CPU tem que ser boa em várias coisas.
- Multitarefa e multiprocessamento - Com tantos aplicativos em nossos computadores, a carga de trabalho da CPU exige alternância de contexto. Sistemas de cache e acesso à memória são configurados para suportar isso. Quando um processo é agendado no thread de hardware da CPU, ele tem todos os dados necessários prontos e executa instruções de computação rapidamente, uma por uma.
Desvantagens da CPU
Confira este e experimente também o . Ele mostra como a multiplicação de matrizes é uma tarefa paralelizável e como núcleos de computação paralelos podem acelerar o cálculo.
- Extremamente bom em tarefas sequenciais, mas não bom em tarefas paralelas.
- Conjunto complexo de instruções e padrão complexo de acesso à memória.
- A CPU também gasta muita energia na troca de contexto e nas atividades da unidade de controle, além de computar
Principais conclusões
- O pipeline de instruções melhora o rendimento da computação.
- Aumentar a largura de banda da memória melhora a simultaneidade de computação.
- As CPUs são boas em tarefas sequenciais (otimizadas para latência). Não é bom em tarefas massivamente paralelas, pois precisa de um grande número de unidades de computação e threads de hardware que não estão disponíveis (não otimizados para rendimento). Eles não estão disponíveis porque as CPUs são construídas para computação de uso geral e possuem conjuntos de instruções complexos.
GPU
À medida que o poder da computação aumentava, também aumentava a demanda por processamento gráfico. Tarefas como renderização de UI e jogos exigem operações paralelas, gerando a necessidade de inúmeras ALUs e FPUs no nível do circuito. As CPUs, projetadas para tarefas sequenciais, não conseguiam lidar com essas cargas de trabalho paralelas de maneira eficaz. Assim, as GPUs foram desenvolvidas para atender à demanda de processamento paralelo em tarefas gráficas, abrindo posteriormente caminho para sua adoção na aceleração de algoritmos de aprendizagem profunda.
Eu recomendo:
- Assistindo a este que explica tarefas paralelas envolvidas na renderização de videogame.
- Lendo esta para entender as tarefas paralelas envolvidas em um transformador. Existem outras arquiteturas de aprendizagem profunda, como CNNs e RNNs também. Como os LLMs estão dominando o mundo, a compreensão de alto nível do paralelismo nas multiplicações de matrizes necessária para tarefas de transformadores estabeleceria um bom contexto para o restante desta postagem. (Mais tarde, pretendo entender completamente os transformadores e compartilhar uma visão geral de alto nível do que acontece nas camadas do transformador de um pequeno modelo GPT.)
Exemplos de especificações de CPU vs GPU
Núcleos, threads de hardware, velocidade de clock, largura de banda de memória e memória on-chip de CPUs e GPUs diferem significativamente. Exemplo:
- Intel Xeon 8280 :
- Base de 2700 MHz e 4000 MHz em Turbo
- 28 núcleos e 56 threads de hardware
- Threads gerais de pipeline: 896 - 56
- Cache L3: 38,5 MB (compartilhado por todos os núcleos) Cache L2: 28,0 MB (dividido entre os núcleos) Cache L1: 1,375 MB (dividido entre os núcleos)
- O tamanho do registro não está disponível publicamente
- Memória máxima: 1 TB DDR4, 2.933 MHz, 6 canais
- Largura de banda máxima de memória: 131 GB/s
- Desempenho máximo do FP64 = 4,0 GHz 2 unidades AVX-512 8 operações por unidade AVX-512 por ciclo de clock * 28 núcleos = ~2,8 TFLOPs [Derivado usando: Desempenho máximo do FP64 = (frequência turbo máxima) (número de unidades AVX-512) ( Operações por unidade AVX-512 por ciclo de clock) * (Número de núcleos)]
Este número é usado para comparação com a GPU, pois obter o desempenho máximo da computação de uso geral é muito subjetivo. Este número é um limite máximo teórico, o que significa que os circuitos FP64 estão sendo usados ao máximo.
- Nvidia A100 80GB SXM :
- Base de 1065 MHz e 1410 MHz em Turbo
- 108 SMs, 64 núcleos FP32 CUDA (também chamados de SPs) por SM, 4 núcleos Tensor FP64 por SM, 68 threads de hardware (64 + 4) por SM
- Geral por GPU: 6912 64 núcleos FP32 CUDA, 432 núcleos Tensor FP 64, 7344 (6912 + 432) threads de hardware
- Threads de pipeline por SM: 2048 - 68 = 1980 por SM
- Threads gerais de pipeline por GPU: (2.048 x 108) - (68 x 108) = 21.184 - 7.344 = 13.840
- Consulte:
- Cache L2: 40 MB (compartilhado entre todos os SMs) Cache L1: 20,3 MB no total (192 KB por SM)
- Tamanho do registro: 27,8 MB (256 KB por SM)
- Memória principal máxima da GPU: 80 GB HBM2e, 1512 MHz
- Largura de banda máxima da memória principal da GPU: 2,39 TB/s
- Desempenho máximo do FP64 = 19,5 TFLOPs [usando apenas todos os núcleos do Tensor FP64]. O valor mais baixo de 9,7 TFLOPs quando apenas FP64 em núcleos CUDA são usados. Este número é um limite máximo teórico, o que significa que os circuitos FP64 estão sendo usados ao máximo.
Núcleo em uma GPU moderna
As terminologias que vimos na CPU nem sempre são traduzidas diretamente nas GPUs. Aqui veremos os componentes e núcleo da GPU NVIDIA A100. Uma coisa que me surpreendeu enquanto pesquisava para este artigo foi que os fornecedores de CPU não publicam quantas ALUs, FPUs, etc., estão disponíveis nas unidades de execução de um núcleo. A NVIDIA é muito transparente quanto ao número de núcleos e a estrutura CUDA oferece total flexibilidade e acesso no nível do circuito.
No diagrama acima na GPU, podemos ver que não há cache L3, cache L2 menor, menor, mas muito mais unidade de controle e cache L1 e um grande número de unidades de processamento.
Aqui estão os componentes da GPU nos diagramas acima e seus equivalentes de CPU para nosso entendimento inicial. Não fiz programação CUDA, então compará-la com equivalentes de CPU ajuda no entendimento inicial. Os programadores CUDA entendem isso muito bem.
- Vários multiprocessadores de streaming <> CPU multi-core
- Multiprocessador de streaming (SM) <> Núcleo da CPU
- Processador de streaming (SP)/ CUDA Core <> ALU/FPU em unidades de execução de um CPU Core
- Tensor Core (capaz de realizar operações 4x4 FP64 em uma única instrução) <> Unidades de execução SIMD em um núcleo de CPU moderno (por exemplo: AVX-512)
- Thread de hardware (fazendo computação em CUDA ou Tensor Cores em um único ciclo de clock) <> Thread de hardware (fazendo computação em unidades de execução [ALUs, FPUs, etc.,] em um único ciclo de clock)
- Memória HBM / VRAM / DRAM / GPU <> RAM
- Memória/SRAM no chip (registros, cache L1, L2) <> Memória/SRAM no chip (registros, cache L1, L2, L3)
- Nota: Os registros em um SM são significativamente maiores que os registros em um núcleo. Devido ao grande número de threads. Lembre-se que no hyper-threading na CPU, vimos um aumento no número de registros, mas não nas unidades de computação. O mesmo princípio aqui.
Movendo dados e largura de banda de memória
Tarefas gráficas e de aprendizado profundo exigem execução do tipo SIM (D/T) [instrução única multidados/thread]. isto é, ler e trabalhar com grandes quantidades de dados para uma única instrução.
Discutimos o pipeline de instruções e o hyper-threading em CPU e GPUs também têm capacidade. A forma como é implementado e funciona é um pouco diferente, mas os princípios são os mesmos.
Ao contrário das CPUs, as GPUs (via CUDA) fornecem acesso direto aos Pipeline Threads (buscando dados da memória e utilizando a largura de banda da memória). Os agendadores de GPU funcionam primeiro tentando preencher as unidades de computação (incluindo cache L1 compartilhado e registros para armazenar operandos de computação) e, em seguida, "threads de pipeline" que buscam dados em registros e HBM. Novamente, quero enfatizar que os programadores de aplicativos de CPU não pensam sobre isso e as especificações sobre "threads de pipeline" e o número de unidades de computação por núcleo não são publicadas. A Nvidia não apenas os publica, mas também fornece controle completo aos programadores.
Entrarei em mais detalhes sobre isso em um post dedicado sobre o modelo de programação CUDA e "lote" na técnica de otimização de serviço de modelo, onde podemos ver como isso é benéfico.
O diagrama acima descreve a execução de threads de hardware no núcleo da CPU e GPU. Consulte a seção "acesso à memória" que discutimos anteriormente em Pipelining de CPU. Este diagrama mostra isso. O complexo gerenciamento de memória das CPUs torna esse tempo de espera pequeno o suficiente (alguns ciclos de clock) para buscar dados do cache L1 para os registradores. Quando os dados precisam ser buscados no L3 ou na memória principal, o outro thread para o qual os dados já estão registrados (vimos isso na seção de hyper-threading) obtém o controle das unidades de execução.
Nas GPUs, devido ao excesso de assinaturas (alto número de threads e registros de pipeline) e ao conjunto de instruções simples, uma grande quantidade de dados já está disponível em registros com execução pendente. Esses threads de pipeline aguardando execução tornam-se threads de hardware e executam a mesma frequência a cada ciclo de clock, pois os threads de pipeline em GPUs são leves.
Largura de banda, intensidade de computação e latência
O que está acima do objetivo?
- Utilize totalmente os recursos de hardware (unidades de computação) em cada ciclo de clock para obter o melhor da GPU.
- Para manter as unidades de computação ocupadas, precisamos alimentá-las com dados suficientes.
Esta é a principal razão pela qual a latência da multiplicação de matrizes menores é mais ou menos a mesma em CPU e GPU. .
As tarefas precisam ser paralelas o suficiente, os dados precisam ser grandes o suficiente para saturar os FLOPs de computação e a largura de banda da memória. Se uma única tarefa não for grande o suficiente, várias dessas tarefas precisarão ser compactadas para saturar a memória e a computação para utilizar totalmente o hardware.
Intensidade de computação = FLOPs / largura de banda . ou seja, a proporção entre a quantidade de trabalho que pode ser realizada pelas unidades de computação por segundo e a quantidade de dados que pode ser fornecida pela memória por segundo.
No diagrama acima, vemos que a intensidade da computação aumenta à medida que avançamos para maior latência e menor largura de banda de memória. Queremos que esse número seja o menor possível para que a computação seja totalmente utilizada. Para isso, precisamos manter o máximo de dados em L1/Registradores para que a computação possa acontecer rapidamente. Se buscarmos dados únicos do HBM, haverá apenas algumas operações em que realizamos 100 operações em dados únicos para que valha a pena. Se não fizermos 100 operações, as unidades de computação ficarão ociosas. É aqui que entra em jogo o grande número de threads e registros nas GPUs. Manter o máximo de dados em L1/registros para manter a intensidade de computação baixa e manter os núcleos paralelos ocupados.
Há uma diferença na intensidade de computação de 4X entre os núcleos CUDA e Tensor porque os núcleos CUDA podem executar apenas um FP64 MMA 1x1, enquanto os núcleos Tensor podem executar instruções 4x4 FP64 MMA por ciclo de clock.
Principais conclusões
Alto número de unidades de computação (núcleos CUDA e Tensor), alto número de threads e registros (sobre assinatura), conjunto de instruções reduzido, sem cache L3, HBM (SRAM), padrão de acesso à memória simples e de alto rendimento (em comparação com CPUs - comutação de contexto , cache multicamadas, paginação de memória, TLB, etc.) são os princípios que tornam as GPUs muito melhores do que as CPUs na computação paralela (renderização gráfica, aprendizado profundo, etc.)
Além das GPUs
As GPUs foram criadas inicialmente para lidar com tarefas de processamento gráfico. Os pesquisadores de IA começaram a aproveitar o CUDA e seu acesso direto ao poderoso processamento paralelo por meio de núcleos CUDA. A GPU NVIDIA possui mecanismos de processamento de textura, Ray Tracing, Raster, Polymorph, etc. (digamos conjuntos de instruções específicas para gráficos). Com o aumento da adoção da IA, estão sendo adicionados núcleos Tensor que são bons no cálculo de matrizes 4x4 (instrução MMA), dedicados ao aprendizado profundo.
Desde 2017, a NVIDIA vem aumentando o número de núcleos Tensor em cada arquitetura. Mas essas GPUs também são boas em processamento gráfico. Embora o conjunto de instruções e a complexidade sejam muito menores nas GPUs, elas não são totalmente dedicadas ao aprendizado profundo (especialmente a Transformer Architecture).
, uma otimização da camada de software (simpatia mecânica para o padrão de acesso à memória da camada de atenção) para arquitetura de transformador fornece velocidade 2X nas tarefas.
Com nosso conhecimento aprofundado de CPU e GPU baseado em primeiros princípios, podemos entender a necessidade de aceleradores de transformador: um chip dedicado (circuito apenas para operações de transformador), com um número ainda maior de unidades de computação para paralelismo, conjunto de instruções reduzido, sem Caches L1/L2, DRAM (registros) massivos substituindo HBM, unidades de memória otimizadas para padrão de acesso à memória da arquitetura do transformador. Afinal, os LLMs são novos companheiros para os humanos (depois da web e dos dispositivos móveis) e precisam de chips dedicados para eficiência e desempenho.
Alguns aceleradores de IA:
Aceleradores de transformadores:
Aceleradores de transformador baseados em FPGA:
Referências:
- Como funcionam os gráficos de videogame? -
- CPU vs GPU vs TPU vs DPU vs QPU -
- Como funciona a computação GPU | GTC 2021 | Stephen Jones -
- Intensidade de computação -
- Como funciona a programação CUDA | GTC Outono 2022 | Stephen Jones -
- Por que usar GPU com redes neurais? -
- Hardware CUDA | Tom Nurkkala | Palestra na Taylor University -
L O A D I N G
. . . comments & more!
. . . comments & more!



