





































Jan 01, 1970
Cómo construir una aplicación de transmisión de eventos en .NET por@bbejeck
2,850 lecturas
Cómo construir una aplicación de transmisión de eventos en .NET
por Bill Bejeck14m2023/02/13
Demasiado Largo; Para Leer
El procesamiento de flujo es un enfoque para el desarrollo de software que ve los eventos como la entrada o salida principal de una aplicación. En esta publicación de blog, crearemos una aplicación de transmisión de eventos utilizando Apache Kafka, los clientes productores y consumidores de .NET, y Task Parallel Library (TPL) de Microsoft. El cliente de Kafka y TPL se encargan de la mayor parte del trabajo pesado; solo necesita concentrarse en la lógica de su negocio.
- Se enciende el indicador de "bajo nivel de combustible" de su automóvil
- Como resultado, se detiene en la próxima estación de combustible para repostar
- Cuando echa gasolina al automóvil, se le solicita que se una al club de recompensas de la compañía para obtener un descuento.
- Entras, te registras y obtienes un crédito para tu próxima compra.
¿Qué es el procesamiento de flujo?
Al convertirse en la tecnología de facto para manejar datos de eventos, el procesamiento de flujo es un enfoque para el desarrollo de software que ve los eventos como la entrada o salida principal de una aplicación. Por ejemplo, no tiene sentido esperar para actuar sobre la información o responder a una posible compra fraudulenta con tarjeta de crédito. Otras veces, podría implicar el manejo de un flujo entrante de registros en un microservicio, y procesarlos de la manera más eficiente es lo mejor para su aplicación. Cualquiera que sea el caso de uso, es seguro decir que un enfoque de transmisión de eventos es el mejor enfoque para manejar eventos.
apache kafka
Si el procesamiento de transmisiones es el estándar de facto para manejar transmisiones de eventos, entonces es el estándar de facto para crear aplicaciones de transmisión de eventos. Apache Kafka es un registro distribuido proporcionado de manera altamente escalable, elástica, tolerante a fallas y segura. En pocas palabras, Kafka utiliza intermediarios (servidores) y clientes. Los intermediarios forman la capa de almacenamiento distribuido del clúster de Kafka, que puede abarcar centros de datos o regiones de la nube. Los clientes brindan la capacidad de leer y escribir datos de eventos desde un clúster de intermediarios. Los clústeres de Kafka son tolerantes a fallas: si algún agente falla, otros agentes se encargarán del trabajo para garantizar operaciones continuas.Clientes .NET confluentes
Mencioné en el párrafo anterior que los clientes escriben o leen desde un clúster de agentes de Kafka. Apache Kafka se empaqueta con clientes Java, pero hay varios otros clientes disponibles, a saber, el productor y consumidor de .NET Kafka, que es el núcleo de la aplicación en esta publicación de blog. El productor y el consumidor de .NET llevan el poder de la transmisión de eventos con Kafka al desarrollador de .NET. Para más información sobre los clientes .NET consultar la .Biblioteca paralela de tareas
Task Parallel Library ( ) es "un conjunto de tipos públicos y API en los espacios de nombres System.Threading y System.Threading.Tasks", lo que simplifica el trabajo de escribir aplicaciones simultáneas. El TPL hace que agregar concurrencia sea una tarea más manejable al manejar los siguientes detalles:
Bloques de flujo de datos
Antes de entrar en la aplicación que va a construir; deberíamos brindar información general sobre lo que constituye la biblioteca de flujo de datos TPL. El enfoque que se detalla aquí es más aplicable cuando tiene tareas intensivas de E/S y CPU que requieren un alto rendimiento. La biblioteca de flujo de datos TPL consta de bloques que pueden almacenar en búfer y procesar datos o registros entrantes, y los bloques se clasifican en una de tres categorías:
- Bloques de origen: actúan como una fuente de datos y otros bloques pueden leerlos.
- Bloques de destino: un receptor de datos o un sumidero, en el que otros bloques pueden escribir.
- Bloques propagadores: se comportan como un bloque de origen y de destino.
El BufferBlock (y las clases que lo amplían) es el único tipo de bloque en la biblioteca de flujo de datos que permite escribir y leer mensajes directamente; otros tipos esperan recibir mensajes o enviar mensajes a los bloques. Por esta razón, usamos un BufferBlock como delegado cuando creamos el bloque de origen e implementamos la interfaz ISourceBlock y el bloque receptor implementamos la interfaz ITargetBlock .
El otro tipo de bloque de flujo de datos que se usa en nuestra aplicación es un . Como la mayoría de los tipos de bloques en la biblioteca de flujo de datos, crea una instancia de TransformBlock al proporcionar un Func<TInput, TOutput> para actuar como un delegado que ejecuta el bloque de transformación para cada registro de entrada que recibe.
Cuando establece el paralelismo de un bloque en más de uno, el marco garantiza que mantendrá el orden original de los registros de entrada (tenga en cuenta que mantener el orden con paralelismo es configurable, siendo verdadero el valor predeterminado). Si el orden original de los datos es A, B, C, entonces el orden de salida será A, B, C. ¿Escéptico? Sé que lo estaba, así que lo probé y descubrí que funcionaba como se anunciaba. Hablaremos de esta prueba un poco más adelante en esta publicación. Tenga en cuenta que solo se debe aumentar el paralelismo con operaciones sin estado o con estado que sean asociativas y conmutativas , lo que significa que cambiar el orden o la agrupación de las operaciones no afectará el resultado.
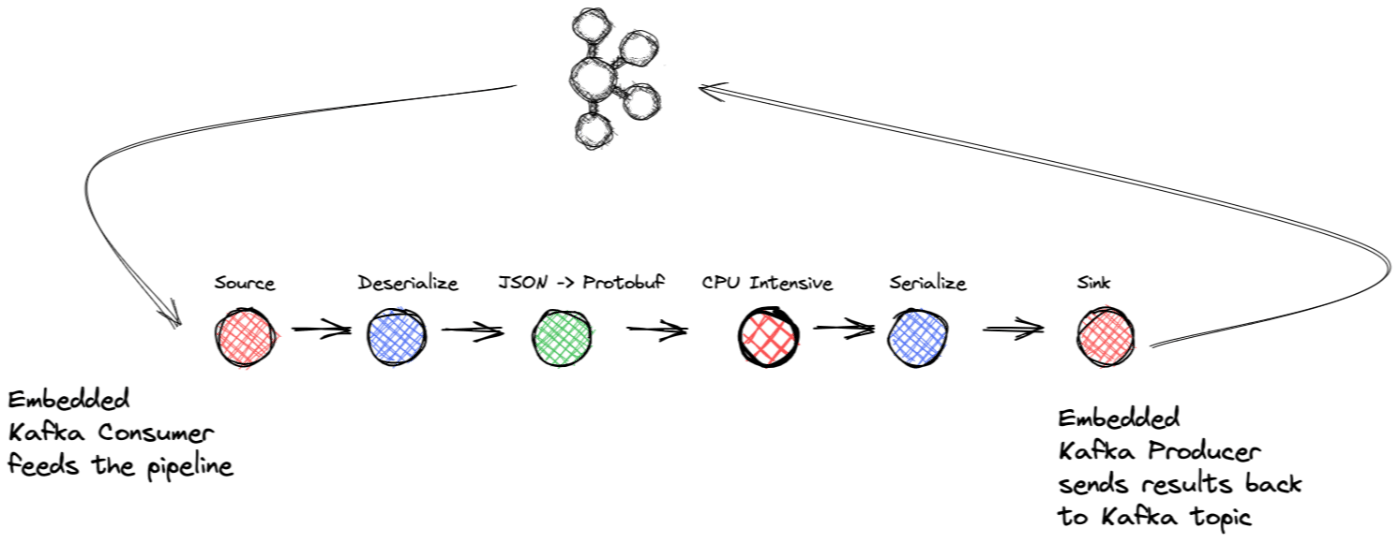
- Bloque fuente: Envolviendo un .NET KafkaConsumer y un delegado
BufferBlock - Bloque de transformación: deserialización
- Bloque de transformación: mapeo de datos JSON entrantes para comprar objetos
- Bloque de transformación: tarea de uso intensivo de CPU (simulado)
- Bloque de transformación: serialización
- Bloque de destino: empaquetar un delegado de .NET KafkaProducer y
BufferBlock
Una aplicación de transmisión de eventos
Este es nuestro escenario: tiene un tema de Kafka que recibe registros de compras de su tienda en línea y el formato de datos entrantes es JSON. Desea procesar estos eventos de compra aplicando inferencias de ML a los detalles de la compra. Además, le gustaría transformar los registros JSON al formato Protobuf, ya que este es el formato de datos de toda la empresa. Por supuesto, el rendimiento de la aplicación es esencial. Las operaciones de ML consumen mucha CPU, por lo que necesita una forma de maximizar el rendimiento de la aplicación, por lo que aprovechará la paralelización de esa parte de la aplicación.
Consumir datos en la canalización
Recorramos los puntos críticos de la aplicación de streaming, empezando por el bloque fuente. Mencioné antes la implementación de la interfaz ISourceBlock y, dado que BufferBlock también implementa ISourceBlock , la usaremos como delegado para satisfacer todos los métodos de la interfaz. Entonces, la implementación del bloque fuente envolverá un KafkaConsumer y el BufferBlock. Dentro de nuestro bloque fuente, tendremos un hilo separado cuya única responsabilidad es que el consumidor pase los registros que ha consumido al búfer. A partir de ahí, el búfer enviará los registros al siguiente bloque de la canalización.
Antes de reenviar el registro al búfer, el ConsumeRecord (devuelto por la llamada Consumer.consume ) se envuelve con una abstracción Record que, además de la clave y el valor, captura la partición original y el desplazamiento, que es fundamental para la aplicación, y Explicaré por qué en breve. También vale la pena señalar que toda la canalización funciona con la abstracción Record , por lo que cualquier transformación da como resultado un nuevo objeto Record que envuelve la clave, el valor y otros campos esenciales, como el desplazamiento original, que los conserva a lo largo de toda la canalización.
Bloques de procesamiento
La aplicación divide el procesamiento en varios bloques diferentes. Cada bloque se vincula con el siguiente paso en la cadena de procesamiento, por lo que el bloque de origen se vincula con el primer bloque, que maneja la deserialización. Si bien .NET KafkaConsumer puede manejar la deserialización de registros, hacemos que el consumidor pase la carga útil serializada y la deserialice en un bloque Transform. La deserialización puede hacer un uso intensivo de la CPU, por lo que poner esto en su bloque de procesamiento nos permite paralelizar la operación si es necesario.
Este bloque de procesamiento simulado es donde aprovechamos el poder del marco de bloques de Dataflow. Cuando crea una instancia de un bloque de Dataflow, proporciona una instancia Func delegada que se aplica a cada registro que encuentra y una instancia ExecutionDataflowBlockOptions . Mencioné la configuración de los bloques de Dataflow antes, pero los revisaremos rápidamente aquí nuevamente. ExecutionDataflowBlockOptions contiene dos propiedades esenciales: el tamaño máximo de búfer para ese bloque y el grado máximo de paralelización.
El bloque de procesamiento intensivo reenvía a un bloque de transformación de serialización que alimenta el bloque receptor, que luego envuelve un KafkaProducer de .NET y produce los resultados finales en un tema de Kafka. El bloque sumidero también usa un BufferBlock delegado y un subproceso separado para producir. El subproceso recupera el siguiente registro disponible del búfer. Luego llama al método KafkaProducer.Produce pasando un delegado Action que envuelve el DeliveryReport : el subproceso de E/S del productor ejecutará el delegado de Action una vez que se complete la solicitud de producción.
Compensación de compensaciones
Al procesar datos con Kafka, periódicamente confirmará compensaciones (una compensación es la posición lógica de un registro en un tema de Kafka) de los registros que su aplicación ha procesado correctamente hasta un punto determinado. Entonces, ¿por qué uno comete las compensaciones? Esa es una pregunta fácil de responder: cuando su consumidor se apaga de manera controlada o por error, reanudará el procesamiento desde la última compensación comprometida conocida. Al comprometer periódicamente las compensaciones, su consumidor no volverá a procesar registros o al menos una cantidad mínima si su aplicación se cierra después de procesar algunos registros pero antes de comprometerse. Este enfoque se conoce como procesamiento al menos una vez, lo que garantiza que los registros se procesen al menos una vez y, en caso de errores, tal vez algunos de ellos se vuelvan a procesar, pero esa es una excelente opción cuando la alternativa es arriesgarse a perder datos. Kafka también proporciona garantías de procesamiento exactamente una vez y, aunque no entraremos en transacciones en esta publicación de blog, puede leer más sobre las transacciones en Kafka en
Con el enfoque de canalización, ¿cómo garantizamos el procesamiento al menos una vez? Aprovecharemos el método IConsumer.StoreOffset , que asigna un solo parámetro, un TopicPartitionOffset , y lo almacena (junto con otras compensaciones) para la siguiente confirmación. Tenga en cuenta que contrasta cómo funciona la confirmación automática con la API de Java.
Para cualquier error durante la etapa de producción, la aplicación registra el error y vuelve a colocar el registro en el BufferBlock anidado para que el productor vuelva a intentar enviar el registro al intermediario. Pero esta lógica de reintento se realiza a ciegas y, en la práctica, probablemente desee una solución más robusta.
Implicaciones de rendimiento
Ahora que hemos cubierto cómo funciona la aplicación, veamos los números de rendimiento. Todas las pruebas se ejecutaron localmente en una computadora portátil macOS Big Sur (11.6), por lo que su kilometraje puede variar en este escenario. La configuración de la prueba de rendimiento es sencilla:
- Produzca 1 millón de registros para un tema de Kafka en formato JSON. Este paso se realizó con anticipación y no se incluyó en las mediciones de prueba.
- Inicie la aplicación habilitada para Kafka Dataflow y configure la paralelización en todos los bloques en 1 (el valor predeterminado)
- La aplicación se ejecuta hasta que haya procesado con éxito 1 millón de registros, luego se apaga
- Registre el tiempo que tomó procesar todos los registros
| Número de registros | Factor de concurrencia | Tiempo (minutos) |
|---|---|---|
| 1M | 1 | 38 |
| 1M | 4 | 9 |
- Producir 1M de enteros (0-999,999) a un tema de Kafka
- Modificar la aplicación de referencia para trabajar con tipos enteros
- Ejecute la aplicación con un nivel de simultaneidad de uno para el bloque de proceso remoto simulado: produzca en un tema de Kafka
- Vuelva a ejecutar la aplicación con un nivel de concurrencia de cuatro y genere los números para otro tema de Kafka.
- Ejecute un programa para consumir los números enteros de ambos temas de resultados y guárdelos en una matriz en la memoria
- Compare ambas matrices y confirme que están en el mismo orden
Resumen
En esta publicación, presentamos cómo usar los clientes .NET Kafka y la biblioteca paralela de tareas para crear una aplicación de transmisión de eventos robusta y de alto rendimiento. Kafka proporciona transmisión de eventos de alto rendimiento, y la biblioteca paralela de tareas le brinda los componentes básicos para crear aplicaciones simultáneas con almacenamiento en búfer para manejar todos los detalles, lo que permite a los desarrolladores concentrarse en la lógica comercial. Si bien el escenario de la aplicación es un poco artificial, es de esperar que pueda ver la utilidad de combinar las dos tecnologías. Darle una oportunidad-
También publicado
L O A D I N G
. . . comments & more!
. . . comments & more!



