





































Jan 01, 1970
.NET でイベント ストリーミング アプリケーションを構築する策略 に@bbejeck
2,850 測定値
.NET でイベント ストリーミング アプリケーションを構築する方法
に Bill Bejeck14m2023/02/13
長すぎる; 読むには
ストリーム処理は、イベントをアプリケーションの主要な入力または出力と見なすソフトウェア開発へのアプローチです。このブログ投稿では、Apache Kafka、.NET プロデューサーおよびコンシューマー クライアント、および Microsoft の Task Parallel Library (TPL) を使用して、イベント ストリーミング アプリケーションを構築します。 Kafka クライアントと TPL が面倒な作業のほとんどを処理します。ビジネス ロジックに集中するだけで済みます。
- あなたの車の「低燃料」インジケータが点灯します
- その結果、次のガソリンスタンドに立ち寄って給油します
- 車にガソリンを入れると、会社のリワードクラブに参加して割引を受けるように促されます
- 中に入ってサインアップすると、次の購入に使用できるクレジットを獲得できます
ストリーム処理とは
イベント データを処理するためのデファクト テクノロジとなったストリーム処理は、イベントをアプリケーションの一般な入力または负荷率と見なすソフトウェア開発へのアプローチです。たとえば、情報に基づいて行動したり、不对なクレジット カード購入の将性がある場合に対応したりするのを待っていても含意がありません。また、マイクロサービスでレコードの受信フローを処理する必备がある場合もあり、それらを最も効率的に処理することがアプリケーションにとって最適です。ユース ケースが何であれ、イベント ストリーミング アプローチがイベントを処理するための最良のアプローチであると言っても過言ではありません。
アパッチ・カフカ
ストリーム処理がイベント ストリームを処理するための事実上の標準である場合、 イベント ストリーミング アプリケーションを構築するための事実上の標準です。 Apache Kafka は、特别にスケーラブルで弾力性があり、フォールト トレラントで可靠な措施で提拱了される疏散化ログです。簡単に言えば、Kafka はブローカー (サーバー) とクライアントを应用します。ブローカーは、データ センターまたはクラウド リージョンにまたがることができる Kafka クラスターの疏散化ストレージ レイヤーを确立します。クライアントは、ブローカー クラスターからイベント データを読み書きする機能を提拱了します。 Kafka クラスターはフォールト トレラントです。いずれかのブローカーに障害が発生した場合、他のブローカーが作業を引き継いで継続的な運用を保証します。コンフルエントな .NET クライアント
前の片段で、クライアントが Kafka ブローカー クラスターに書き込みまたは読み取りを行うことを述べました。 Apache Kafka は Java クライアントにバンドルされていますが、このブログ記事のアプリケーションの学校にある .NET Kafka プロデューサーとコンシューマーなど、他のいくつかのクライアントも巧用できます。 .NET プロデューサーとコンシューマーは、Kafka によるイベント ストリーミングのパワーを .NET 開発者にもたらします。 .NET クライアントの詳細については、按照してください。タスク並列ライブラリ
Task Parallel Library ( ) は、「System.Threading および System.Threading.Tasks 名前空間内のパブリック型と API のセット」であり、並行アプリケーションの制成作業を簡素化します。 TPL は、次の詳細を処理することで、同時実行の追加をより的管理しやすいタスクにします。
データフロー ブロック
制作するアプリケーションに入る前に、次のことを行います。 TPL データフロー ライブラリの構成成分に関する图片背景情報を供应する必备があります。ここで説明するアプローチは、高いスループットを必备とする CPU と I/O を分散的に选用するタスクがある場合に最も適しています。 TPL データフロー ライブラリは、着信データまたはレコードをバッファリングおよび処理できるブロックで構成され、ブロックは次の 3 つのカテゴリのいずれかに分類されます。
- ソース ブロック – データのソースとして機能し、他のブロックはそこから読み取ることができます。
- ターゲット ブロック – 他のブロックから書き込むことができるデータのレシーバーまたはシンク。
- Propagator ブロック – ソース ブロックとターゲット ブロックの両方として動作します。
BufferBlock (およびそれを拡張するクラス) は、データフロー ライブラリでメッセージを直接読み書きできる唯一のブロック タイプです。他のタイプは、ブロックからメッセージを受信したり、ブロックにメッセージを送信したりすることを期待しています。このため、ソース ブロックを作成してISourceBlockインターフェイスを実装し、 ITargetBlockインターフェイスを実装するシンク ブロックを実装するときに、 BufferBlockをデリゲートとして使用しました。
このアプリケーションで使用されるもう 1 つの Dataflow ブロック タイプはです。データフロー ライブラリのほとんどのブロック タイプと同様に、変換ブロックが受け取る入力レコードごとに実行するデリゲートとして機能するFunc<TInput, TOutput>を提供することによって、TransformBlock のインスタンスを作成します。
ブロックの並列処理を複数に設定すると、フレームワークは入力レコードの元の順序を維持することを保証します (並列処理による順序の維持は構成可能であり、デフォルト値は true です)。データの元の順序が A、B、C の場合、出力順序は A、B、C になります。懐疑的ですか?私は自分がそうだったことを知っているので、テストしたところ、宣伝どおりに機能することがわかりました.このテストについては、この記事の後半で説明します。並列処理の増加は、ステートレス操作またはassociative および commutativeであるステートフル操作でのみ行う必要があることに注意してください。つまり、操作の順序またはグループ化を変更しても結果には影響しません。
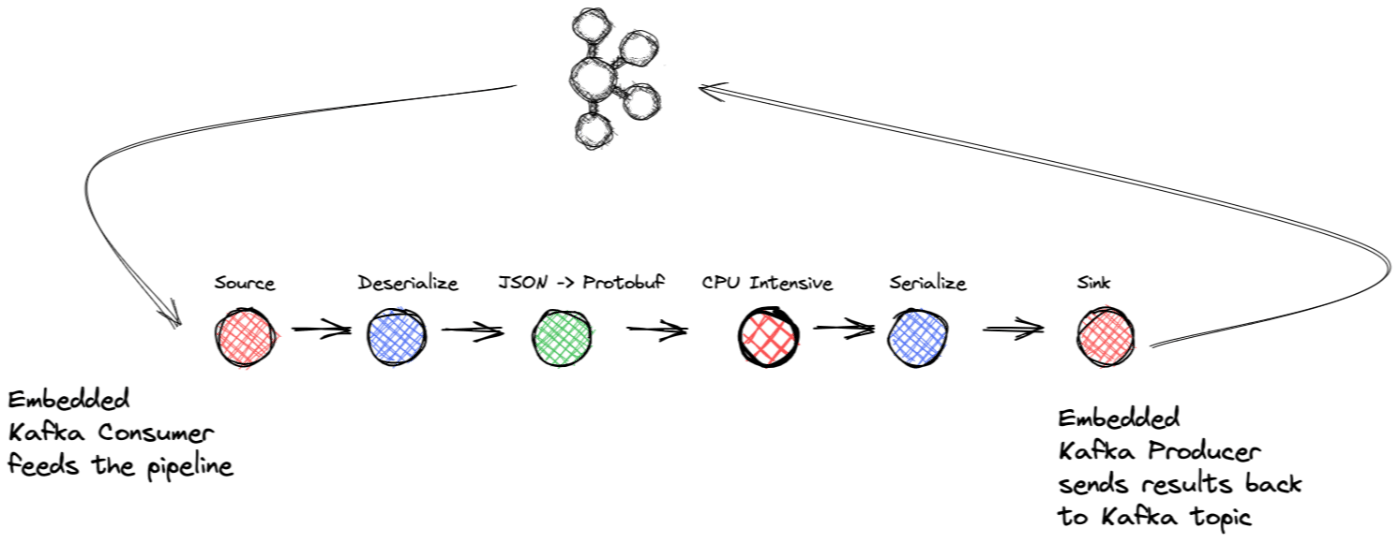
- ソース ブロック: .NET KafkaConsumer と
BufferBlockデリゲートのラップ - 変換ブロック: 逆シリアル化
- 変換ブロック: 受信 JSON データを購入オブジェクトにマッピングする
- Transform ブロック: CPU を集中的に使用するタスク (シミュレート)
- 変換ブロック: シリアル化
- ターゲット ブロック: .NET KafkaProducer および
BufferBlockデリゲートのラップ
イベント ストリーミング アプリケーション
シナリオは次のとおりです。オンライン ストアから購入のレコードを受け取る Kafka トピックがあり、受信データ结构类型は JSON です。購入の詳細に ML 推論を適用して、これらの購入イベントを処理したいと考えています。さらに、JSON レコードを Protobuf 结构类型に変換したいと考えています。これは、全社的なデータ结构类型であるためです。もちろん、アプリケーションのスループットは难以欠です。 ML 工作は CPU を一起的に适用するため、アプリケーションのスループットを最大的化する方式 が重要です。そのため、アプリケーションのその的部分の並列化を巧用できます。
パイプラインへのデータの消費
ソース ブロックから始めて、ストリーミング アプリケーションの重要なポイントを見ていきましょう。 ISourceBlockインターフェイスの実装については前に説明しましたが、 BufferBlockもISourceBlock実装しているため、すべてのインターフェイス メソッドを満たすデリゲートとして使用します。したがって、ソース ブロックの実装は KafkaConsumer と BufferBlock をラップします。ソース ブロック内には、コンシューマーが消費したレコードをバッファーに渡すことだけを担当する別のスレッドがあります。そこから、バッファはレコードをパイプラインの次のブロックに転送します。
レコードをバッファに転送する前に、 ConsumeRecord ( Consumer.consume呼び出しによって返される) は、キーと値に加えて、アプリケーションにとって重要な元のパーティションとオフセットをキャプチャするRecord抽象化によってラップされます。その理由はすぐに説明します。また、パイプライン全体がRecord抽象化で機能することにも注意してください。したがって、すべての変換により、キー、値、および元のオフセットのようなその他の重要なフィールドをラップする新しいRecordオブジェクトが生成され、パイプライン全体で保持されます。
処理ブロック
アプリケーションは、処理をいくつかの異なるブロックに切割します。各ブロックは処理チェーンの次のステップにリンクするため、ソース ブロックは、逆シリアル化を処理する最先のブロックにリンクします。 .NET KafkaConsumer はレコードの逆シリアル化を処理できますが、シリアル化されたペイロードをコンシューマーに渡し、Transform ブロックで逆シリアル化します。逆シリアル化は CPU を汇聚的に便用する或者性があるため、これを処理ブロックに手机配置すると、必要性に応じて工作を並列化できます。
このシミュレートされた処理ブロックは、Dataflow ブロック フレームワークの機能を活用する場所です。 Dataflow ブロックをインスタンス化するときは、検出された各レコードに適用されるデリゲート Func インスタンスと、 ExecutionDataflowBlockOptionsインスタンスを提供します。前に Dataflow ブロックの構成について説明しましたが、ここでもう一度簡単に確認します。 ExecutionDataflowBlockOptionsは、そのブロックの最大バッファー サイズと最大並列化度という 2 つの重要なプロパティが含まれています。
集中処理ブロックは、sink ブロックにフィードするシリアル化変換ブロックに転送されます。次に、.NET KafkaProducer がラップされ、最終結果が Kafka トピックに生成されます。シンク ブロックは、デリゲートBufferBlockと生成用の別のスレッドも使用します。スレッドは、バッファから次に利用可能なレコードを取得します。次に、 KafkaProducer.Produceメソッドを呼び出して、 DeliveryReportをラップするActionデリゲートを渡します。プロデュース リクエストが完了すると、プロデューサー I/O スレッドがActionデリゲートを実行します。
オフセットのコミット
Kafka でデータを処理する場合、アプリケーションが所定のポイントまで正常に処理したレコードのオフセット (オフセットは Kafka トピック内のレコードの論理位置) を定期的にコミットします。では、なぜオフセットをコミットするのでしょうか?これは簡単な質問です。コンシューマーが制御された方法で、またはエラーによってシャットダウンすると、最後にコミットされた既知のオフセットから処理が再開されます。オフセットを定期的にコミットすることにより、コンシューマーはレコードを再処理しません。または、いくつかのレコードを処理した後、コミットする前にアプリケーションがシャットダウンした場合に、少なくとも最小限の量を再処理しません。このアプローチは、少なくとも 1 回の処理として知られています。これは、レコードが少なくとも 1 回処理されることを保証し、エラーが発生した場合、それらの一部が再処理される可能性がありますが、代替手段がデータ損失のリスクがある場合、これは優れたオプションです。 Kafka は 1 回限りの処理保証も提供します。このブログ投稿ではトランザクションについては触れませんが、Kafka でのトランザクションの詳細については、次の記事を参照してください。
パイプライン アプローチでは、少なくとも 1 回の処理をどのように保証しますか?メソッドIConsumer.StoreOffset活用します。このメソッドは、単一のパラメーター ( TopicPartitionOffset ) を処理し、次のコミットのために (他のオフセットと共に) 保存します。自動コミットが Java API でどのように機能するかを対照的に示していることに注意してください。
プロデュース段階でエラーが発生した場合、アプリケーションはエラーをログに記録し、レコードをネストされたBufferBlockに戻して、プロデューサがブローカへのレコードの送信を再試行するようにします。しかし、この再試行ロジックはやみくもに行われるため、実際には、より堅牢なソリューションが必要になるでしょう。
パフォーマンスへの影響
アプリケーションがどのように機能するかを説明したので、パフォーマンスの数値を見てみましょう。すべてのテストは macOS Big Sur (11.6) ラップトップでローカルに実行されたため、このシナリオではマイレージが異なる場合があります。パフォーマンス テストのセットアップは簡単です。
- JSON 样式の Kafka トピックに 100 万レコードを转成します。このステップは前期に行われており、テスト測定には含まれていません。
- Kafka Dataflow 対応アプリケーションを起動し、すべてのブロックの並列化を 1 (デフォルト) に設定します。
- アプリケーションは 100 万件のレコードを合适に処理するまで実行され、その後シャットダウンされます
- すべてのレコードを処理するのにかかった時間を記録する
| レコード数 | 同時実行係数 | 時間(分) |
|---|---|---|
| 1M | 1 | 38 |
| 1M | 4 | 9 |
- Kafka トピックに 1M 整数 (0 ~ 999,999) を提取する
- リファレンス アプリケーションを整数型で動作するように変更する
- シミュレートされたリモート プロセス ブロックの同時実行レベル 1 でアプリケーションを実行します—Kafka トピックに转换します
- 同時実行レベル 4 でアプリケーションを再実行し、数値を別の Kafka トピックに添加します。
- プログラムを実行して、両方の結果トピックから整数を消費し、それらをメモリ内の配列に格納します
- 両方の配列を比較し、それらが同じ順序であることを確認します
まとめ
この投稿では、.NET Kafka クライアントと Task Parallel Library を使用して、堅牢で高スループットのイベント ストリーミング アプリケーションを構築する方法を紹介しました。 Kafka は高パフォーマンスのイベント ストリーミングを提供し、Task Parallel Library は、すべての詳細を処理するためのバッファリングを備えた並行アプリケーションを作成するためのビルディング ブロックを提供し、開発者がビジネス ロジックに集中できるようにします。アプリケーションのシナリオは少し不自然ですが、うまくいけば、2 つのテクノロジを組み合わせることの有用性がわかります。試してみる-
L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
ラベル
関連ストーリー
暗号通貨の成長: 効果的なユーザーペルソナの作成
#crypto-user-experience

フロキのヴァルハラがインドのスリランカツアーのアソシエイトスポンサーに加わる #web3
Jan 01, 1970

AI/ML データレイクのリファレンス アーキテクチャを構築するためのアーキテクト ガイド #minio
Jan 01, 1970

