










































Jan 01, 1970
Aprenda la agrupación en clústeres de K-Means mediante la cuantificación de imágenes en color en Python por@balapriya
16,579 lecturas
Aprenda la agrupación en clústeres de K-Means mediante la cuantificación de imágenes en color en Python
por Bala Priya C9m2022/02/15
Demasiado Largo; Para Leer
El aprendizaje no supervisado es una clase de aprendizaje automático que implica encontrar patrones en datos no etiquetados. Y el agrupamiento es un algoritmo de aprendizaje no supervisado que encuentra patrones en datos no etiquetados al agrupar o agrupar puntos de datos en función de alguna medida de similitud. La agrupación en clústeres de K-Means es un algoritmo de agrupación en clústeres simple y efectivo, y aprenderá sobre eso en este tutorial.Company Mentioned
El aprendizaje no supervisado es una clase de aprendizaje automático que implica encontrar patrones en datos no etiquetados. Y el agrupamiento es un algoritmo de aprendizaje no supervisado que encuentra patrones en datos no etiquetados al agrupar o agrupar puntos de datos en función de alguna medida de similitud.
La agrupación en clústeres de K-Means es un algoritmo de agrupación en clústeres simple y efectivo, y aprenderá sobre eso en este tutorial.
En los próximos minutos, repasaremos los pasos del agrupamiento de K-Means, formalizaremos el algoritmo y también codificaremos un proyecto divertido sobre imágenes de cuantización de color.
Tabla de contenido
- Aprendizaje supervisado vs no supervisado
- El algoritmo K-Means en lenguaje sencillo
- 5 pasos en el algoritmo de agrupamiento de K-Means
- ¿Cómo elegir K? El método del codo explicado
- Limitaciones de la agrupación en clústeres de K-Means
- Cómo cuantificar una imagen en color mediante el agrupamiento de K-Means
6.1 Explicación
6.2 Codificación en scikit-learn
Aprendizaje supervisado vs no supervisado
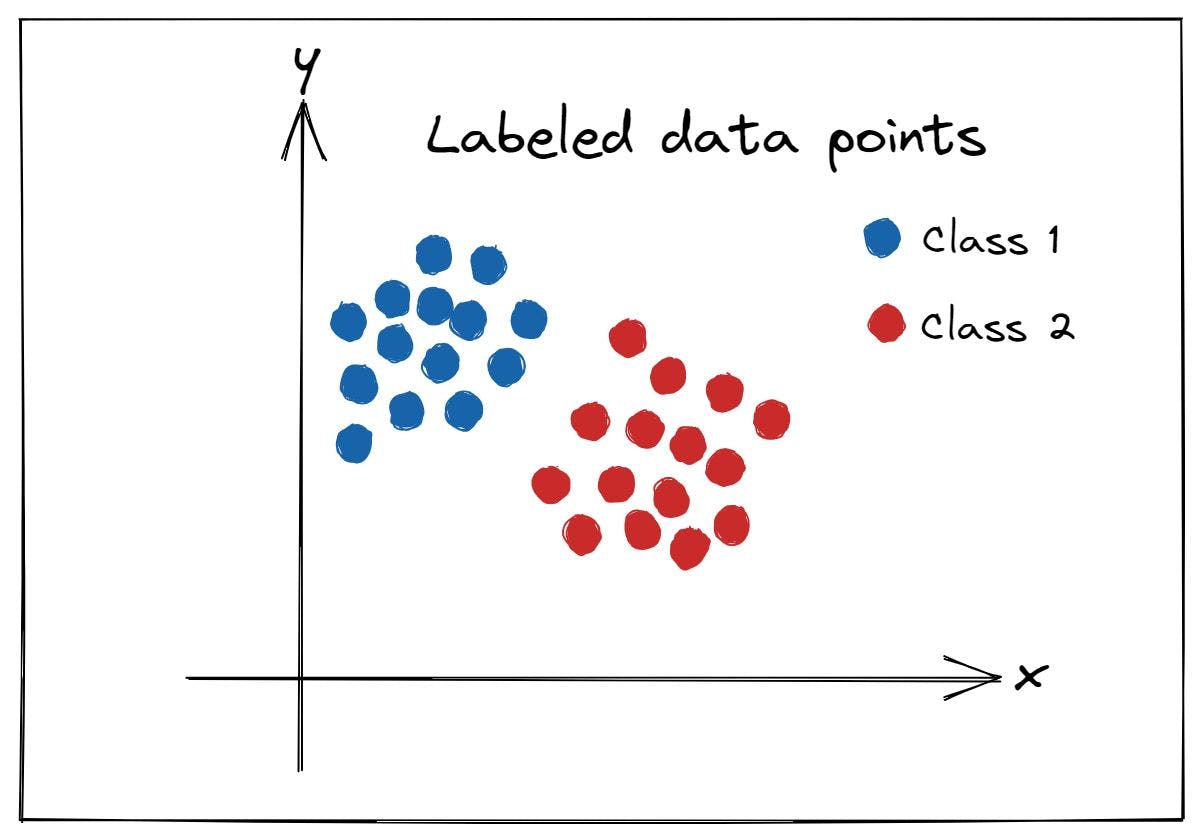
Si está familiarizado con el aprendizaje supervisado, sabe que recibe los puntos de datos y las etiquetas de clase correspondientes: datos etiquetados. Su tarea es crear un modelo que prediga la etiqueta de clase para un punto de prueba invisible.Fig 1: Conjunto de datos etiquetados para aprendizaje supervisado (Imagen del autor)
Sin embargo, en el aprendizaje no supervisado, no tiene estas etiquetas de clase cuando comienza. Todo lo que tiene es un conjunto de puntos de datos, como se muestra en la imagen a continuación.Fig. 2: Conjunto de datos sin etiquetar para el aprendizaje no supervisado (Imagen del autor)
Un algoritmo no supervisado a menudo encuentra algún patrón en los datos y, por lo tanto, descubre etiquetas. Eso es precisamente lo que hará nuestro algoritmo de agrupamiento. En cierto sentido, ejecuta un algoritmo de agrupación en clústeres en un conjunto de datos sin etiquetar y, en el proceso, descubre las etiquetas de clase.
En la siguiente sección, nos sumergiremos directamente en el funcionamiento del algoritmo de agrupación en clústeres de K-Means.El algoritmo K-Means en lenguaje sencillo
Explicaremos el algoritmo en un lenguaje sencillo y luego lo formularemos matemáticamente escribiendo un pseudocódigo. Antes de comenzar, revisemos el objetivo final de la agrupación en clústeres de K-Means. Cuando la agrupación esté completa:- cada punto de datos debe asignarse a un grupo, y
- cada punto de datos debe asignarse a uno y solo un grupo
Por ejemplo, digamos que tenemos 7 clústeres. Elegimos 7 puntos de datos al azar como centros de conglomerados y asignamos todos los puntos de datos restantes al conglomerado más cercano. Si un punto está más cerca del centro del conglomerado 3 que de los centros de todos los demás conglomerados, ese punto se asigna al conglomerado 3. Y esto se repite para todos los puntos del conjunto de datos.
En general, si hay K conglomerados, cada punto se asigna al conglomerado i si la distancia entre ese punto y el centro del conglomerado i es menor que la distancia entre ese punto y todos los demás centros del conglomerado.
Ahora, debe actualizar los centros de clúster . Para hacer esto, simplemente configure el centro del grupo para que sea igual al promedio de todos los puntos en ese grupo. Intuitivamente, está claro que los nuevos centros de conglomerados pueden no ser puntos en el conjunto de datos original, sino algunos puntos en el mismo espacio que el conjunto de datos original.
Repita el proceso de asignación de cada uno de los puntos restantes al centro del clúster más cercano. Luego, regrese al paso anterior y actualice todos los centros de conglomerados. Entonces, ¿cuándo detenemos este proceso? 🤔Se dice que el algoritmo de agrupamiento de K-Means converge cuando los centros de los agrupamientos no cambian significativamente y usted ha agrupado o agrupado con éxito su conjunto de datos original.
Ahora que ha obtenido una comprensión básica del funcionamiento de la agrupación en clústeres de K-medias, formalicemos el algoritmo en la siguiente sección.5 pasos en el algoritmo de agrupamiento de K-Means
Fig 3: Pasos en el agrupamiento de K-Means (Imagen del autor)
Analicemos los pasos en el pseudocódigo anterior y veamos cómo se relaciona con nuestra discusión en la sección anterior.Paso 1 : Para comenzar, fija la cantidad de clústeres
K , y este es el paso 1 en el pseudocódigo.Paso 2 : Y luego eliges
K puntos de datos al azar e inicialícelos para que sean los centroides o centros de conglomerados. Este es el paso 2, y elegimos llamarlo inicialización aleatoria.Paso 3 : este paso implica asignar todos los puntos de datos restantes a un grupo según el centro del grupo al que estén más cerca, y esta distancia suele ser la distancia euclidiana.
Si puede recordar algunas de sus matemáticas escolares, la distancia euclidiana entre dos puntos en un plano bidimensional se da de la siguiente manera:Fig 4: Distancia euclidiana entre puntos de datos (Imagen del autor)
Cuando sus puntos de datos están en un espacio multidimensional, digamos que tienen m características. Cada punto tendrá m coordenadas y se da la distancia euclidiana entre dos puntos x : (x1,x2,...,xm) e y : (y1,y2,y3,...,ym) en este espacio m-dimensional por la siguiente ecuación:
Ecuación creada usando
Paso 4 : El siguiente paso es actualizar el centro del grupo para que sea igual al promedio de todos los puntos en el grupo respectivo. Luego, regrese al paso anterior de asignar nuestros puntos al centro de clúster actualizado más cercano.
Paso 5 : Repetimos los pasos 3 y 4 hasta que nuestros centros de conglomerados no cambien, momento en el que se dice que el algoritmo de conglomerado ha convergido.
¿Se dio cuenta de que no hemos averiguado qué tan bien funciona el algoritmo de agrupamiento?
- No tenemos las etiquetas de verdad del terreno, por lo que nunca sabríamos si cada punto se ha asignado al grupo correcto.
- De hecho, fijamos el número de grupos en el primer paso. ¿Cómo sabemos si elegimos la K correcta?
- ¿Y cómo evaluamos la bondad del algoritmo de agrupamiento? ¿Es este el agrupamiento óptimo que podemos obtener en el conjunto de datos dado o podemos hacerlo mejor?
Bueno, todas estas preguntas serán respondidas en la siguiente sección. Esto se captura en la noción de Suma de cuadrados dentro del grupo (WSS) . No se deje intimidar por el término: repasaremos lo que significa y el método para encontrar la mejor K en la siguiente sección.
¿Cómo elegir K? El método del codo explicado
Los conglomerados que mejor se ajustan a los datos son aquellos que minimizan la suma de cuadrados dentro del conglomerado (WSS) , y viene dado por la siguiente ecuación:
Ecuación creada usando
Bueno, esto puede parecer complicado al principio, pero la idea subyacente es simple. Esto es lo que hacemos. Para cada punto en el conjunto de datos, calculamos su distancia al centro del grupo y la elevamos al cuadrado. Luego sumamos todas esas distancias al cuadrado de los puntos a sus respectivos centros de grupos, para todos los grupos K.En esencia, esta cantidad WSS se minimiza cuando todos los puntos se han asignado al clúster correcto .En la práctica, puede ejecutar el algoritmo K-means con diferentes inicializaciones aleatorias y elegir la agrupación que minimice WSS. WSS también proporciona una forma de elegir el valor óptimo de K. Grafique los valores de K contra los valores de WSS. Por lo general, observará que la curva se curva en un valor particular de K donde el valor de WSS es lo suficientemente pequeño, como se muestra a continuación. En la práctica, este K a menudo se elige para que sea el número de grupos (K se establecerá en 4 en la figura a continuación).
Fig 5: La curva del codo para elegir K
Limitaciones de la agrupación en clústeres de K-Means
Por otro lado, el agrupamiento de K-Means tiene las siguientes limitaciones:- El agrupamiento obtenido depende en gran medida de la inicialización aleatoria y puede que no siempre sea el óptimo global.
- La convergencia se ve afectada por una mala elección de inicialización.
- El algoritmo K-Means no es lo suficientemente robusto para acomodar valores atípicos en el conjunto de datos.
Cómo cuantificar una imagen en color mediante el agrupamiento de K-Means
En este punto, ha adquirido una comprensión de cómo funciona el agrupamiento, las limitaciones de K significa agrupamiento y cómo elegir el valor de K. Ahora, procedamos a hacer un proyecto divertido sobre la cuantificación de imágenes en color.Explicación de la cuantificación de color de imágenes
La cuantificación de color es una técnica popular de cuantificación de imágenes. Por lo general, una imagen contiene miles de colores únicos. Sin embargo, hay momentos en los que necesitará mostrar las imágenes en dispositivos que están limitados por la cantidad de colores que pueden mostrar, o cuando tendrá que comprimir una imagen para reducir su tamaño. Aquí es donde la cuantificación del color resulta útil.En una imagen en color, cada píxel es una tupla de valores de rojo, verde y azul (R,G,B) . Puede mezclar rojo, verde y azul en proporciones variables para obtener una amplia gama de colores.
Por lo tanto, una imagen que tiene W píxeles de ancho y H píxeles de alto y tiene los canales de color R, G y B se puede representar como se muestra en la siguiente imagen:Fig 6: Canales de color RGB de una imagen (Imagen del autor)
Ahora nos gustaría cuantificar la imagen de modo que contenga solo K colores. ¿Cómo lo hacemos usando el agrupamiento de K-means? Consideremos que los valores R, G, B son características en sí mismos si podemos cambiar la forma de la matriz de imágenes como se muestra a continuación; básicamente, estamos aplanando las matrices de color de modo que cada punto con sus valores RGB sea un punto de datos.Fig 7: Matriz de imágenes reformadas (Imagen del autor)
Ahora puede realizar el agrupamiento de K-medias. Como se discutió anteriormente, los centros de clúster que obtiene también son puntos en el mismo espacio, lo que significa que también serán tonos de color, con valores RGB válidos. Recuerde, en este ejercicio, cada punto de datos es un color. En el próximo paso, asignaremos todos los puntos (o colores) en el grupo para que sean del mismo color que el centro del grupo. De esta manera, ha reducido el espacio de color de la imagen a K colores; los K colores son los colores de los centros de los grupos. Avancemos y cuantifiquemos el color de una imagen escribiendo un código de Python. Interesante, ¿sí? ¡Comencemos a codificar de inmediato!Codificación K-Means Clustering Color Quantization en scikit-learn
Ahora repasemos los pasos del proceso de cuantificación de color K-Means.1️⃣ Importaciones necesarias
Comencemos importando las bibliotecas necesarias. import numpy as np import matplotlib.pyplot as plt import matplotlib.image as img2️⃣ Leer en la imagen como una matriz NumPy
Ahora leamos la imagen de entrada como una matriz de imágenes. Para ello, puede utilizar el
imread() método, como se muestra. Imagen utilizada en este tutorial: Foto de en 💡 Nota : asegúrese de agregar la imagen a su directorio de trabajo actual o al
files pestaña si está utilizando Google Colab. img_arr = img.imread( '/content/sample_image.jpg' ) print (img_arr.shape) # Output: (457, 640, 3)2.1 Mostrar la imagen
Para mostrar la imagen, puede utilizar el
imshow() método. plt.imshow(img_arr) A continuación, podemos iniciar el proceso de cuantificación del color.
3️⃣ Proceso de cuantificación de color
3.1 Cambiar la forma de la matriz de imágenes
Recuerde que la imagen original tiene tres canales de color: R, G y B, cada uno con W píxeles de ancho y H píxeles de alto.Ahora remodelaremos cada uno de los canales de color en una sola matriz larga de longitud
W*H . (h,w,c) = img_arr.shape img2D = img_arr.reshape(h*w,c) print (img2D) print (img2D.shape) # Output
[[ 90 134 169 ] [ 90 134 169 ] [ 91 135 170 ] ... [ 22 21 16 ] [ 5 4 0 ] [ 4 3 0 ]] ( 292480 , 3 )4️⃣ Aplicar agrupamiento de K-Means
Importar el
KMeans clase de sklearn's cluster módulo.Instanciar un objeto de la
KMeans clase, especificando n_clusters = 7 . Esto significa que en la imagen cuantizada, solo tendremos 7 colores distintos.Para ver las etiquetas de los grupos, llame al
fit_predict() en el objeto K-Means con la imagen ( img2D ) como argumento. from sklearn.cluster import KMeans kmeans_model = KMeans(n_clusters= 7 ) # we shall retain only 7 colors
cluster_labels = kmeans_model.fit_predict(img2D)4.1 Ver las etiquetas del clúster
Ahora, veamos las etiquetas de los clústeres. print (cluster_labels) # Sample Output
[ 4 4 4 ... 0 0 0 ]4.2 Ver la distribución de etiquetas
Para comprender la distribución de las etiquetas, puede utilizar un
Counter objeto, como se muestra a continuación: from collections import Counter labels_count = Counter(cluster_labels) print (labels_count) # Sample output
Counter({ 0 : 104575 , 6 : 49581 , 4 : 36725 , 5 : 34004 , 2 : 26165 , 3 : 23453 , 1 : 17977 })4.3 Ver los centros de conglomerados
print (kmeans_model.cluster_centers_) # Output
[[ 16.33839194 14.55113194 5.10185087 ] [ 218.18966094 213.72629935 201.77520633 ] [ 103.89269832 85.21711201 65.79896613 ] [ 197.64774759 130.96223282 92.92893639 ] [ 110.49899467 154.81760135 182.03880013 ] [ 158.7716262 182.74213392 192.84830022 ] [ 49.82493331 43.39654239 24.07867873 ]]5️⃣ Convertir centros de clúster a valores RGB
Los centros de conglomerados así obtenidos también podrían ser números de coma flotante. Así que vamos a convertirlos a números enteros para que sean valores RGB válidos. rgb_cols = kmeans_model.cluster_centers_. round ( 0 ).astype( int ) print (rgb_cols) # Output
[[ 16 15 5 ] [ 218 214 202 ] [ 104 85 66 ] [ 198 131 93 ] [ 110 155 182 ] [ 159 183 193 ] [ 50 43 24 ]]6️⃣ Asigne todos los puntos del clúster al centro del clúster
En este paso, mapeamos todos los puntos en un grupo particular a los respectivos centros de grupo.
De esta forma, todos los colores de la imagen ahora se asignan a uno de los 7 colores correspondientes a los centros del grupo.
img_quant = np.reshape(rgb_cols[cluster_labels],(h,w,c))7️⃣ Mostrar la imagen cuantizada en color
¡Y es hora de ver la imagen cuantizada en color! plt.imshow(img_quant) fig, ax = plt.subplots( 1 , 2 , figsize=( 16 , 12 )) ax[ 0 ].imshow(img_arr) ax[ 0 ].set_title( 'Original Image' ) ax[ 1 ].imshow(img_quant) ax[ 1 ].set_title( 'Color Quantized Image' ) ¡Felicidades! Su proyecto ya está listo, en solo 7 pasos. Asegúrese de jugar con las imágenes y ver cómo se cuantifican.
Concluyendo la cuantización de color de K-Means
¡Gracias por llegar tan lejos! Espero que disfrutes este tutorial. Nos vemos en el próximo tutorial. Hasta entonces, ¡feliz codificación!📌Otras historias que te gustarían
Aquí hay algunos otros tutoriales que puede disfrutar:▶️ Funciones hash criptográficas en Blockchain [con código Bash y Python]
▶️ Tutorial avanzado de modelado de temas: cómo usar SVD y NMF en Python
▶️ Matriz de confusión en el aprendizaje automático: todo lo que necesita saber
▶️ 9 mejores cursos de ingeniería de datos que debe tomar en 2022
▶️ Matriz de término de documento en NLP: recuento y puntajes TF-IDF explicados
L O A D I N G
. . . comments & more!
. . . comments & more!



