








































visit
Learn K-Means Clustering by Quantizing Color Images in Python by@balapriya
16,579 reads
Learn K-Means Clustering by Quantizing Color Images in Python
by Bala Priya CFebruary 15th, 2022
Too Long; Didn't Read
Unsupervised learning is a class of machine learning that involves finding patterns in unlabeled data. And clustering is an unsupervised learning algorithm that finds patterns in unlabeled data by clustering or grouping together data points together based on some similarity measure. K-Means clustering is a simple and effective clustering algorithm, and you'll learn about that in this tutorial.Company Mentioned
Unsupervised learning is a class of machine learning that involves finding patterns in unlabeled data. And clustering is an unsupervised learning algorithm that finds patterns in unlabeled data by clustering or grouping data points together based on some similarity measure.
K-Means clustering is a simple and effective clustering algorithm, and you'll learn about that in this tutorial.
Over the next few minutes, we’ll go over the steps in K-Means clustering, formalize the algorithm, and also code a fun project on color quantizing images.
Table of Contents
- Supervised vs Unsupervised Learning
- The K-Means Algorithm in Plain English
- 5 Steps in the K-Means Clustering Algorithm
- How to Choose K? The Elbow Method Explained
- Limitations of K-Means Clustering
- How to Quantize a Color Image Using K-Means Clustering
6.1 Explanation
6.2 Coding in scikit-learn
Supervised vs Unsupervised Learning
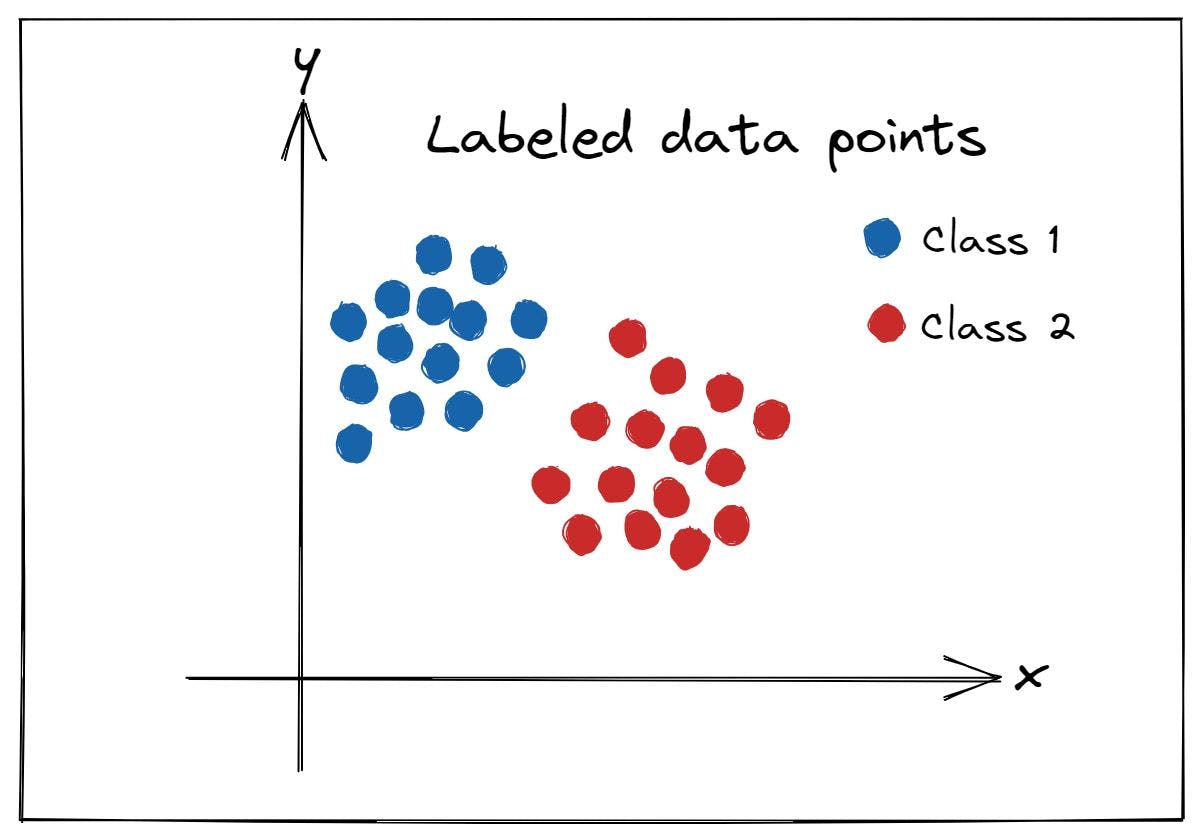
If you’re familiar with supervised learning, you know that you’re given the data points and the corresponding class labels—labeled data. Your task is to come up with a model that predicts the class label for an unseen test point.Fig 1: Labeled dataset for supervised learning (Image by the author)
However, in unsupervised learning, you don’t have these class labels when you start. All you have is a set of data points, as shown in the image below.Fig 2: Unlabeled dataset for unsupervised learning (Image by the author)
An unsupervised algorithm often finds some pattern in the data and thereby discovers labels. That’s precisely what our clustering algorithm will do. In some sense, you run a clustering algorithm on an unlabeled dataset, and in the process discover the class labels.
In the next section, we’ll dive straight into the workings of the K-Means Clustering algorithm.The K-Means Algorithm in Plain English
We’ll explain the algorithm in plain language, and then formulate it mathematically by writing a pseudocode. Before we start, let’s review the end goal of K-Means clustering. When the clustering is complete:- every data point should be assigned to a cluster, and
- every data point should be assigned to one and only one cluster
For example, let’s say we have 7 clusters. We pick 7 data points at random as cluster centers—and assign all the remaining data points to the nearest cluster. If a point is closer to the center of cluster 3 than to the centers of all other clusters, then that point is assigned to cluster 3. And this is repeated for all points in the dataset.
In general, if there are K clusters, each point is assigned to the cluster i if the distance between that point and the cluster center of cluster i is less than the distance between that point and all other cluster centers.
Now, you have to update the cluster centers. To do this, just set the cluster center to be equal to the average of all the points in that cluster. Intuitively, it’s clear that the new cluster centers may not be points in the original dataset, but some points in the same space as the original dataset.
Repeat the process of assigning each of the remaining points to the nearest cluster center. Then, go back to the previous step and update all the cluster centers.So when do we stop this process? 🤔The K-Means clustering algorithm is said to converge when the cluster centers don’t change significantly—and you’ve successfully clustered or grouped your original dataset.
Now that you've gained a basic understanding of the workings of K-means clustering, let’s formalize the algorithm in the next section.5 Steps in the K-Means Clustering Algorithm
Fig 3: Steps in K-Means Clustering (Image by the author)
Let’s parse the steps in the above pseudocode, and see how it ties in with our discussion in the previous section.Step 1: To begin, you fix the number of clusters
KStep 2: And then you pick
KStep 3: This step involves assigning all the remaining data points to a cluster depending on which cluster center they are the closest to, and this distance is often the Euclidean distance.
If you can recall some of your school math, the Euclidean distance between two points in a two-dimensional plane is given as follows:Fig 4: Euclidean distance between data points (Image by the author)
When your data points are in a multidimensional space, say they have m features. Each point will have m coordinates and the Euclidean distance between two points x: (x1,x2,...,xm) and y: (y1,y2,y3,...,ym) in this m-dimensional space is given by the following equation:
Equation created using
Step 4: The next step is to update the cluster center to be equal to the average of all the points in the respective cluster. Then, go back to the previous step of assigning our points to the nearest updated cluster center.
Step 5: We repeat steps 3 and 4 until our cluster centers don't change—at which point the clustering algorithm is said to have converged.
Did you notice that we haven't quite figured out how good the clustering algorithm performs?
- We don't have the ground truth labels so we’d never know if each point has been assigned to the correct cluster.
- For that matter, we fixed the number of clusters in the very first step. How do we know if we picked the right K?
- And how do we evaluate the goodness of the clustering algorithm? Is this the optimal clustering we can get on the given dataset or can we do better?
Well, all of these questions shall be answered in the next section. This is captured in the notion of Within-Cluster Sum of Squares (WSS). Don’t be intimidated by the term—we’ll go over what it means, and the method to find the best K in the next section.
How to Choose K? The Elbow Method Explained
The best-fit clusters to the data are those that minimize the Within-Cluster Sum of Squares (WSS), and is given by the following equation:
Equation created using
Well, this may seem complicated at first—but the underlying idea is simple.Here’s what we do. For each point in the dataset, we calculate its distance to the cluster center and square it. We then sum up all such squared distances of the points to their respective cluster centers, for all the K clusters.In essence, this quantity WSS is minimized when all the points have been assigned to the correct cluster.
Fig 5: The elbow curve for choosing K
Limitations of K-Means Clustering
On the flip side, K-Means clustering has the following limitations:- The clustering obtained depends heavily on the random initialization and it may not always be the global optimum.
- Convergence is affected by poor choice of initialization.
- The K-Means algorithm is not robust enough to accommodate outliers in the dataset.
How to Quantize a Color Image Using K-Means Clustering
At this point you've gained an understanding of how clustering works, the limitations of K means clustering, and how to choose the value of K. Now, let's proceed to do a fun project on quantizing color images.Explanation of Color Quantization of Images
Color quantization is a popular image quantization technique. Typically, an image contains thousands of unique colors in it. However, there are times when you’ll need to display the images on devices that are limited by the number of colors they can display, or when you’ll have to compress an image to reduce its size. Here’s where color quantization comes in handy.In a color image, every pixel is a tuple of red, green, and blue values (R,G,B). You can mix red, green, and blue in varying proportions to get a whole range of colors.
Therefore, an image that is W pixels wide and H pixels high and has the R,G, and B color channels can be represented as shown in the image below:Fig 6: RGB Color Channels of an Image (Image by the author)
Now we’d like to quantize the image such that it contains only K colors. How do we do it using K-means clustering? Let's consider the R,G,B values to be features in themselves if we can reshape the image array as shown below—we are essentially flattening out the color arrays such that each point with its RGB values is a data point.Fig 7: Reshaped image array (Image by the author)
Now you can perform K-means clustering. As discussed above, the cluster centers that you get are also points in the same space—which means they will also be color shades—with valid RGB values. Remember, in this exercise, each data point is a color.In the next step, we’ll assign all points (or colors) in the cluster to be of the same color as the cluster center. This way, you’ve reduced the color space of the image to K colors—the K colors being the colors of the cluster centers. Let’s go ahead and color quantize an image by writing some Python code.Interesting, yes? Let’s start coding right away!Coding K-Means Clustering Color Quantization in scikit-learn
Let's now go over the steps in the K-Means color quantization process.1️⃣ Necessary imports
Let's start by importing the necessary libraries.import numpy as np
import matplotlib.pyplot as plt
import matplotlib.image as img2️⃣ Read in the image as a NumPy array
Now let's read in the input image as an image array. To do this, you can use the
imread()💡 Note: Be sure to add the image to your current working directory, or to the
filesimg_arr = img.imread('/content/sample_image.jpg')
print(img_arr.shape)
# Output: (457, 640, 3)2.1 Display the image
To display the image, you may use the
imshow()plt.imshow(img_arr) Next, we can start the color quantization process.
3️⃣ Color Quantization process
3.1 Reshape image array
Recall that the original image has three color channels: R, G, and B—each W pixels wide, and H pixels high.Now we'll reshape each of the color channels into a single long array of length
W*H(h,w,c) = img_arr.shape
img2D = img_arr.reshape(h*w,c)
print(img2D)
print(img2D.shape)# Output
[[ 90 134 169]
[ 90 134 169]
[ 91 135 170]
...
[ 22 21 16]
[ 5 4 0]
[ 4 3 0]]
(292480, 3)4️⃣ Apply K-Means Clustering
Import the
KMeansclusterInstantiate an object of the
KMeansn_clusters = 7To view the cluster labels, call the
fit_predict()img2Dfrom sklearn.cluster import KMeans
kmeans_model = KMeans(n_clusters=7) # we shall retain only 7 colors
cluster_labels = kmeans_model.fit_predict(img2D)4.1 View the cluster labels
Now, let's view the cluster labels.print(cluster_labels)
# Sample Output
[4 4 4 ... 0 0 0]4.2 View the label distribution
To understand the distribution of labels, you can use a
Counterfrom collections import Counter
labels_count = Counter(cluster_labels)
print(labels_count)
# Sample output
Counter({0: 104575, 6: 49581, 4: 36725, 5: 34004, 2: 26165, 3: 23453, 1: 17977})4.3 View the cluster centers
print(kmeans_model.cluster_centers_)
# Output
[[ 16.33839194 14.55113194 5.10185087]
[218.18966094 213.72629935 201.77520633]
[103.89269832 85.21711201 65.79896613]
[197.64774759 130.96223282 92.92893639]
[110.49899467 154.81760135 182.03880013]
[158.7716262 182.74213392 192.84830022]
[ 49.82493331 43.39654239 24.07867873]]5️⃣ Convert cluster centers to RGB values
The cluster centers thus obtained could as well be floating point numbers. So let's convert them to integers so that they are valid RGB values.rgb_cols = kmeans_model.cluster_centers_.round(0).astype(int)
print(rgb_cols)
# Output
[[ 16 15 5]
[218 214 202]
[104 85 66]
[198 131 93]
[110 155 182]
[159 183 193]
[ 50 43 24]]6️⃣ Assign all cluster points to the cluster center
In this step, we map all points in a particular cluster to the respective cluster centers.
This way all colors in the image are now mapped to one of the 7 colors corresponding to the cluster centers
img_quant = np.reshape(rgb_cols[cluster_labels],(h,w,c))7️⃣ Display the color quantized image
And it's time to view the color quantized image!plt.imshow(img_quant)fig, ax = plt.subplots(1,2, figsize=(16,12))
ax[0].imshow(img_arr)
ax[0].set_title('Original Image')
ax[1].imshow(img_quant)
ax[1].set_title('Color Quantized Image')Congratulations! Your project is now ready—in just 7 steps. Be sure to play around with the images, and see how they're quantized.
Wrapping Up K-Means Color Quantization
Thanks for making it this far! I hope you enjoyed this tutorial. See you all in the next tutorial. Until then, happy coding!L O A D I N G
. . . comments & more!
. . . comments & more!
About Author
TOPICS
RELATED STORIES




10 Movie Tie-In Games That Were Actually Good #gaming
Nov 23, 2022



