





































Jan 01, 1970
Comment créer une application de diffusion d'événements dans .NET par@bbejeck
2,850 lectures
Comment créer une application de diffusion d'événements dans .NET
par Bill Bejeck14m2023/02/13
Trop long; Pour lire
Le traitement de flux est une approche du développement logiciel qui considère les événements comme l'entrée ou la sortie principale d'une application. Dans cet article de blog, nous allons créer une application de streaming d'événements à l'aide d'Apache Kafka, le producteur .NET et des clients consommateurs, et de la bibliothèque parallèle de tâches (TPL) de Microsoft. Le client Kafka et TPL s'occupent de la plupart des gros travaux ; vous n'avez qu'à vous concentrer sur votre logique métier.
- L'indicateur "bas niveau de carburant" de votre voiture s'allume
- De ce fait, vous vous arrêtez à la prochaine station-service pour faire le plein
- Lorsque vous pompez de l'essence dans la voiture, vous êtes invité à rejoindre le club de récompenses de l'entreprise pour obtenir une remise
- Vous entrez et vous vous inscrivez et obtenez un crédit pour votre prochain achat
Qu'est-ce que le traitement de flux ?
Devenu la technologie de facto pour traiter les données d'événement, le traitement de flux est une approche du développement logiciel qui considère les événements comme l'entrée ou la sortie principale d'une application. Par exemple, il n'y a aucun sens à attendre pour agir sur des informations ou répondre à un achat potentiellement frauduleux par carte de crédit. D'autres fois, cela peut impliquer la gestion d'un flux entrant d'enregistrements dans un microservice, et leur traitement le plus efficace est le mieux pour votre application. Quel que soit le cas d'utilisation, il est sûr de dire qu'une approche de streaming d'événements est la meilleure approche pour gérer les événements.
Apache Kafka
Si le traitement de flux est la norme de facto pour la gestion des flux d'événements, alors est la norme de facto pour la création d'applications de streaming d'événements. Apache Kafka est un journal distribué fourni de manière hautement évolutive, élastique, tolérante aux pannes et sécurisée. En un mot, Kafka utilise des courtiers (serveurs) et des clients. Les courtiers forment la couche de stockage distribué du cluster Kafka, qui peut s'étendre sur des centres de données ou des régions cloud. Les clients offrent la possibilité de lire et d'écrire des données d'événement à partir d'un cluster de courtiers. Les clusters Kafka sont tolérants aux pannes : si un courtier tombe en panne, d'autres courtiers prendront le relais pour assurer la continuité des opérations.Clients .NET confluents
J'ai mentionné dans le paragraphe précédent que les clients écrivent ou lisent à partir d'un cluster de courtiers Kafka. Apache Kafka est fourni avec des clients Java, mais plusieurs autres clients sont disponibles, à savoir le producteur et consommateur .NET Kafka, qui est au cœur de l'application dans cet article de blog. Le producteur et le consommateur .NET apportent la puissance du streaming d'événements avec Kafka au développeur .NET. Pour plus d'informations sur les clients .NET, consultez la .Bibliothèque parallèle de tâches
La bibliothèque parallèle de tâches ( ) est "un ensemble de types publics et d'API dans les espaces de noms System.Threading et System.Threading.Tasks", simplifiant le travail d'écriture d'applications simultanées. Le TPL fait de l'ajout de la simultanéité une tâche plus facile à gérer en gérant les détails suivants :
Blocs de flux de données
Avant d'entrer dans l'application que vous allez créer ; nous devrions donner quelques informations générales sur ce qui compose la bibliothèque de flux de données TPL. L'approche détaillée ici est plus applicable lorsque vous avez des tâches gourmandes en CPU et en E/S qui nécessitent un débit élevé. La bibliothèque de flux de données TPL se compose de blocs qui peuvent mettre en mémoire tampon et traiter des données ou des enregistrements entrants, et les blocs appartiennent à l'une des trois catégories suivantes :
- Blocs source - Agissent comme une source de données et d'autres blocs peuvent y lire.
- Blocs cibles - Un récepteur de données ou un récepteur, sur lequel d'autres blocs peuvent écrire.
- Blocs propagateurs - Se comportent à la fois comme un bloc source et cible.
Le BufferBlock (et les classes qui l'étendent) est le seul type de bloc de la bibliothèque de flux de données qui permet d'écrire et de lire directement des messages ; d'autres types s'attendent à recevoir des messages ou à envoyer des messages à des blocs. Pour cette raison, nous avons utilisé un BufferBlock comme délégué lors de la création du bloc source et de l'implémentation de l'interface ISourceBlock et du bloc récepteur implémentant l'interface ITargetBlock .
L'autre type de bloc Dataflow utilisé dans notre application est un . Comme la plupart des types de blocs dans la bibliothèque de flux de données, vous créez une instance de TransformBlock en fournissant un Func<TInput, TOutput> pour agir en tant que délégué que le bloc de transformation exécute pour chaque enregistrement d'entrée qu'il reçoit.
Lorsque vous définissez le parallélisme d'un bloc sur plusieurs, le framework garantit qu'il conservera l'ordre d'origine des enregistrements d'entrée (notez que le maintien de l'ordre avec le parallélisme est configurable, la valeur par défaut étant true). Si l'ordre original des données est A, B, C, alors l'ordre de sortie sera A, B, C. Sceptique ? Je sais que je l'étais, alors je l'ai testé et j'ai découvert qu'il fonctionnait comme annoncé. Nous parlerons de ce test un peu plus loin dans ce post. Notez que l'augmentation du parallélisme ne doit être effectuée qu'avec des opérations sans état ou avec état qui sont associatives et commutatives , ce qui signifie que la modification de l'ordre ou du regroupement des opérations n'affectera pas le résultat.
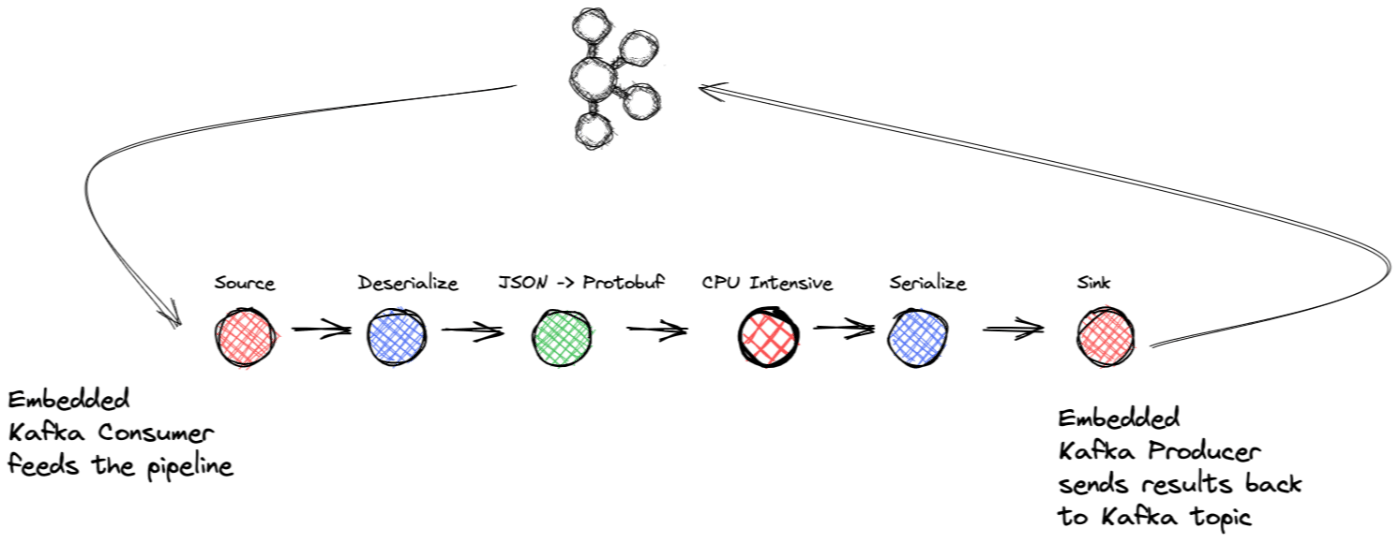
- Bloc source : encapsulation d'un .NET KafkaConsumer et d'un délégué
BufferBlock - Bloc de transformation : désérialisation
- Bloc de transformation : mappage des données JSON entrantes pour acheter un objet
- Bloc de transformation : tâche gourmande en CPU (simulée)
- Bloc de transformation : sérialisation
- Bloc cible : encapsulation d'un délégué .NET KafkaProducer et
BufferBlock
Une application de streaming événementiel
Voici notre scénario : vous avez une rubrique Kafka qui reçoit des enregistrements d'achats de votre boutique en ligne, et le format des données entrantes est JSON. Vous souhaitez traiter ces événements d'achat en appliquant l'inférence ML aux détails de l'achat. De plus, vous souhaitez transformer les enregistrements JSON au format Protobuf, car il s'agit du format de données à l'échelle de l'entreprise. Bien sûr, le débit de l'application est essentiel. Les opérations ML sont gourmandes en CPU, vous avez donc besoin d'un moyen de maximiser le débit de l'application, afin de tirer parti de la parallélisation de cette partie de l'application.
Consommer des données dans le pipeline
Faisons le tour des points critiques de l'application de streaming, en commençant par le bloc source. J'ai déjà mentionné l'implémentation de l'interface ISourceBlock , et puisque le BufferBlock implémente également ISourceBlock , nous l'utiliserons comme délégué pour satisfaire toutes les méthodes d'interface. Ainsi, l'implémentation du bloc source enveloppera un KafkaConsumer et le BufferBlock. À l'intérieur de notre bloc source, nous aurons un thread séparé dont la seule responsabilité est que le consommateur transmette les enregistrements qu'il a consommés dans la mémoire tampon. À partir de là, le tampon transmettra les enregistrements au bloc suivant dans le pipeline.
Avant de transférer l'enregistrement dans la mémoire tampon, ConsumeRecord (renvoyé par l'appel Consumer.consume ) est encapsulé par une abstraction Record qui, en plus de la clé et de la valeur, capture la partition et le décalage d'origine, ce qui est essentiel pour l'application - et J'expliquerai pourquoi sous peu. Il convient également de noter que l'ensemble du pipeline fonctionne avec l'abstraction Record , de sorte que toute transformation se traduit par un nouvel objet Record enveloppant la clé, la valeur et d'autres champs essentiels comme le décalage d'origine en les préservant tout au long du pipeline.
Blocs de traitement
L'application décompose le traitement en plusieurs blocs différents. Chaque bloc est lié à l'étape suivante de la chaîne de traitement, de sorte que le bloc source est lié au premier bloc, qui gère la désérialisation. Alors que le .NET KafkaConsumer peut gérer la désérialisation des enregistrements, nous demandons au consommateur de transmettre la charge utile sérialisée et de la désérialiser dans un bloc Transform. La désérialisation peut être gourmande en CPU, donc le mettre dans son bloc de traitement nous permet de paralléliser l'opération si nécessaire.
C'est dans ce bloc de traitement simulé que nous exploitons la puissance du framework de blocs Dataflow. Lorsque vous instanciez un bloc Dataflow, vous fournissez une instance déléguée Func qu'il applique à chaque enregistrement qu'il rencontre et une instance ExecutionDataflowBlockOptions . J'ai déjà mentionné la configuration des blocs Dataflow, mais nous les reverrons rapidement ici. ExecutionDataflowBlockOptions contient deux propriétés essentielles : la taille maximale de la mémoire tampon pour ce bloc et le degré maximal de parallélisation.
Le bloc de traitement intensif est transmis à un bloc de transformation de sérialisation qui alimente le bloc récepteur, qui encapsule ensuite un KafkaProducer .NET et produit les résultats finaux dans un sujet Kafka. Le bloc récepteur utilise également un BufferBlock délégué et un thread séparé pour la production. Le thread récupère le prochain enregistrement disponible dans la mémoire tampon. Ensuite, il appelle la méthode KafkaProducer.Produce en transmettant un délégué Action enveloppant le DeliveryReport - le thread d'E/S du producteur exécutera le délégué d' Action une fois la demande de production terminée.
Commettre des décalages
Lors du traitement des données avec Kafka, vous validerez périodiquement les décalages (un décalage est la position logique d'un enregistrement dans une rubrique Kafka) des enregistrements que votre application a traités avec succès jusqu'à un point donné. Alors, pourquoi engage-t-on les compensations ? C'est une question à laquelle il est facile de répondre : lorsque votre consommateur s'arrête de manière contrôlée ou suite à une erreur, il reprend le traitement à partir du dernier décalage validé connu. En validant périodiquement les décalages, votre consommateur ne retraitera pas les enregistrements ou au moins une quantité minimale si votre application se ferme après avoir traité quelques enregistrements mais avant de valider. Cette approche est connue sous le nom de traitement au moins une fois, ce qui garantit que les enregistrements sont traités au moins une fois, et en cas d'erreurs, certains d'entre eux peuvent être retraités, mais c'est une excellente option lorsque l'alternative est de risquer la perte de données. Kafka fournit également des garanties de traitement une seule fois, et même si nous n'aborderons pas les transactions dans cet article de blog, vous pouvez en savoir plus sur les transactions dans Kafka dans
Avec l'approche pipeline, comment garantissons-nous un traitement au moins une fois ? Nous allons tirer parti de la méthode IConsumer.StoreOffset , qui charge un seul paramètre - un TopicPartitionOffset - et le stocke (avec d'autres décalages) pour le prochain commit. Notez que contraste le fonctionnement de la validation automatique avec l'API Java.
Pour toute erreur au cours de l'étape de production, l'application enregistre l'erreur et replace l'enregistrement dans le BufferBlock imbriqué afin que le producteur réessaye d'envoyer l'enregistrement au courtier. Mais cette logique de nouvelle tentative est effectuée aveuglément et, en pratique, vous souhaiterez probablement une solution plus robuste.
Incidences sur les performances
Maintenant que nous avons couvert le fonctionnement de l'application, examinons les chiffres de performance. Tous les tests ont été exécutés localement sur un ordinateur portable macOS Big Sur (11.6), votre kilométrage peut donc varier dans ce scénario. La configuration du test de performance est simple :
- Produisez 1 million d'enregistrements dans un sujet Kafka au format JSON. Cette étape a été effectuée à l'avance et n'a pas été incluse dans les mesures du test.
- Démarrez l'application compatible Kafka Dataflow et définissez la parallélisation sur tous les blocs sur 1 (valeur par défaut).
- L'application s'exécute jusqu'à ce qu'elle ait traité avec succès 1 million d'enregistrements, puis elle s'arrête
- Enregistrer le temps qu'il a fallu pour traiter tous les enregistrements
| Nombre d'enregistrements | Facteur de simultanéité | Temps (minutes) |
|---|---|---|
| 1M | 1 | 38 |
| 1M | 4 | 9 |
- Produire des entiers 1M (0-999,999) dans un sujet Kafka
- Modifier l'application de référence pour travailler avec des types entiers
- Exécutez l'application avec un niveau de simultanéité de un pour le bloc de processus distant simulé - produire vers un sujet Kafka
- Réexécutez l'application avec un niveau de simultanéité de quatre et produisez les numéros vers un autre sujet Kafka
- Exécutez un programme pour consommer les nombres entiers des deux rubriques de résultats et les stocker dans un tableau en mémoire
- Comparez les deux tableaux et confirmez qu'ils sont dans le même ordre
Résumé
Dans cet article, nous avons expliqué comment utiliser les clients .NET Kafka et la bibliothèque parallèle de tâches pour créer une application de streaming d'événements robuste et à haut débit. Kafka fournit un streaming d'événements hautes performances et la bibliothèque parallèle de tâches vous fournit les éléments de base pour créer des applications simultanées avec une mise en mémoire tampon pour gérer tous les détails, permettant aux développeurs de se concentrer sur la logique métier. Bien que le scénario de l'application soit un peu artificiel, j'espère que vous pourrez voir l'utilité de combiner les deux technologies. Essaie-
Également publié
L O A D I N G
. . . comments & more!
. . . comments & more!



