























































Jan 01, 1970
701 lectures
Un aperçu digeste de haut niveau des capacités du CPU et du GPU
Trop long; Pour lire
L'article explore les principales différences entre les processeurs et les GPU dans la gestion des tâches de calcul parallèle, couvrant des concepts tels que l'architecture Von Neumann, l'hyper-threading et le pipeline d'instructions. Il explique l'évolution des GPU, des processeurs graphiques vers des outils puissants pour accélérer les algorithmes d'apprentissage en profondeur.Un aperçu digeste de haut niveau de ce qui se passe dans The Die
Dans cet article, nous passerons en revue quelques détails fondamentaux de bas niveau pour comprendre pourquoi les GPU sont bons pour les tâches graphiques, les réseaux de neurones et le Deep Learning et les processeurs sont bons pour un grand nombre de tâches informatiques générales séquentielles et complexes. Il y avait plusieurs sujets que j'ai dû rechercher et acquérir une compréhension un peu plus précise pour cet article, dont certains que je mentionnerai simplement en passant. Cela est fait délibérément pour se concentrer uniquement sur les bases absolues du traitement CPU et GPU.
Architecture Von Neumann
Les anciens ordinateurs étaient des appareils dédiés. Les circuits matériels et les portes logiques ont été programmés pour effectuer un ensemble spécifique de choses. Si quelque chose de nouveau devait être fait, les circuits devaient être recâblés. « Quelque chose de nouveau » pourrait être aussi simple que de faire des calculs mathématiques pour deux équations différentes. Pendant la Seconde Guerre mondiale, Alan Turing travaillait sur une machine programmable pour battre la machine Enigma et publia plus tard l'article « Turing Machine ». À peu près à la même époque, John von Neumann et d’autres chercheurs travaillaient également sur une idée qui proposait fondamentalement :
- Les instructions et les données doivent être stockées dans la mémoire partagée (programme stocké).
- Les unités de traitement et de mémoire doivent être séparées.
- L'unité de contrôle se charge de lire les données et les instructions de la mémoire pour effectuer des calculs à l'aide de l'unité de traitement.
Le goulot d'étranglement
- Goulot d'étranglement du traitement - Une seule instruction et son opérande peuvent se trouver à la fois dans une unité de traitement (porte logique physique). Les instructions sont exécutées séquentiellement les unes après les autres. Au fil des années, des efforts et des améliorations ont été réalisés pour rendre les processeurs plus petits, avec des cycles d'horloge plus rapides et pour augmenter le nombre de cœurs.
- Goulet d'étranglement de la mémoire - À mesure que les processeurs se développaient de plus en plus vite, la vitesse et la quantité de données pouvant être transférées entre la mémoire et l'unité de traitement devenaient un goulot d'étranglement. La mémoire est plusieurs ordres plus lente que le processeur. Au fil des années, l’accent et les améliorations ont été visant à rendre la mémoire plus dense et plus petite.
Processeurs
Nous savons que tout dans notre ordinateur est binaire. La chaîne, l'image, la vidéo, l'audio, le système d'exploitation, le programme d'application, etc. sont tous représentés par des 1 et des 0. Les spécifications de l'architecture du processeur (RISC, CISC, etc.) comportent des jeux d'instructions (x86, x86-64, ARM, etc.), auxquels les fabricants de processeurs doivent se conformer et sont disponibles pour que le système d'exploitation puisse s'interfacer avec le matériel.
Les programmes du système d'exploitation et d'application, y compris les données, sont traduits en jeux d'instructions et en données binaires pour le traitement dans le processeur. Au niveau de la puce, le traitement est effectué au niveau des transistors et des portes logiques. Si vous exécutez un programme pour additionner deux nombres, l'addition (le « traitement ») est effectuée au niveau d'une porte logique dans le processeur.
Dans le CPU selon l'architecture Von Neumann, lorsque nous ajoutons deux nombres, une seule instruction d'ajout s'exécute sur deux nombres dans le circuit. Pendant une fraction de cette milliseconde, seule l'instruction d'ajout a été exécutée dans le cœur (d'exécution) de l'unité de traitement ! Ce détail m'a toujours fasciné.
Cœur dans un processeur moderne
Les composants du diagramme ci-dessus vont de soi. Pour plus de détails et une explication détaillée, reportez-vous à cet excellent . Dans les processeurs modernes, un seul cœur physique peut contenir plusieurs ALU entières, ALU à virgule flottante, etc. Encore une fois, ces unités sont des portes logiques physiques.
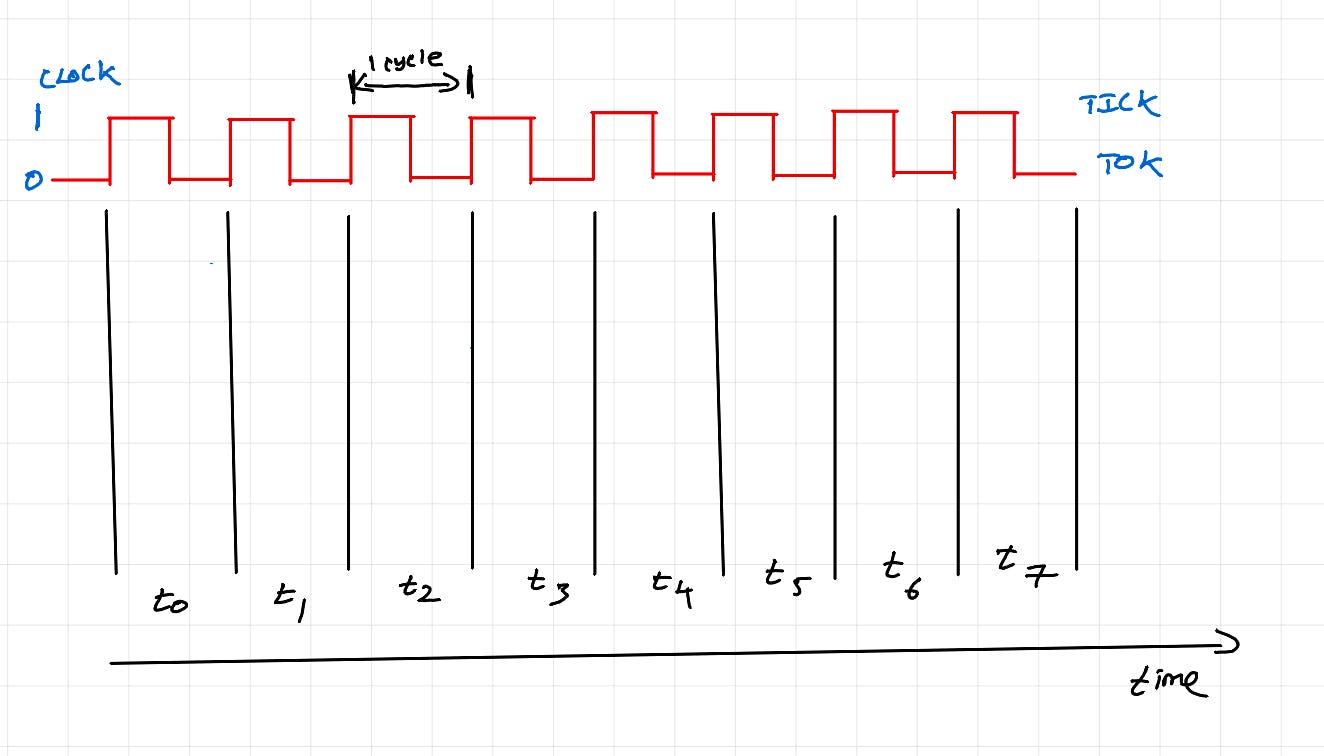
Nous devons comprendre le « fil matériel » dans le cœur du processeur pour une meilleure appréciation du GPU. Un thread matériel est une unité de calcul qui peut être effectuée dans les unités d'exécution d'un cœur de processeur, à chaque cycle d'horloge du processeur . Il représente la plus petite unité de travail pouvant être exécutée dans un noyau.
Cycle d'enseignement
Le diagramme ci-dessus illustre le cycle d'instruction du processeur/cycle machine. Il s'agit d'une série d'étapes que le CPU effectue pour exécuter une seule instruction (par exemple : c=a+b).
Récupérer : le compteur de programme (registre spécial dans le cœur du processeur) garde une trace de l'instruction qui doit être récupérée. L'instruction est récupérée et stockée dans le registre d'instructions. Pour les opérations simples, les données correspondantes sont également récupérées.
Décoder : l'instruction est décodée pour voir les opérateurs et les opérandes.
Exécuter : sur la base de l'opération spécifiée, l'unité de traitement appropriée est choisie et exécutée.
Accès mémoire : si une instruction est complexe ou si des données supplémentaires sont nécessaires (plusieurs facteurs peuvent en être la cause), l'accès à la mémoire est effectué avant l'exécution. (Ignoré dans le diagramme ci-dessus pour plus de simplicité). Pour une instruction complexe, les données initiales seront disponibles dans le registre de données de l'unité de calcul, mais pour une exécution complète de l'instruction, un accès aux données à partir des caches L1 et L2 est requis. Cela signifie qu'il peut y avoir un petit temps d'attente avant que l'unité de calcul ne s'exécute et que le thread matériel tienne toujours l'unité de calcul pendant le temps d'attente.
Réécriture : si l'exécution produit une sortie (par exemple : c=a+b), la sortie est réécrite dans le registre/cache/mémoire. (Ignoré dans le diagramme ci-dessus ou n'importe où plus tard dans le message pour plus de simplicité)
Dans le diagramme ci-dessus, le calcul n'est effectué qu'à t2. Le reste du temps, le noyau est simplement inactif (nous ne faisons aucun travail).
Les processeurs modernes disposent de composants matériels qui permettent essentiellement aux étapes (récupération-décodage-exécution) de se produire simultanément par cycle d'horloge.
Un seul thread matériel peut désormais effectuer des calculs à chaque cycle d'horloge. C’est ce qu’on appelle le pipeline d’instructions.
La récupération, le décodage, l'accès à la mémoire et l'écriture sont effectués par d'autres composants d'un processeur. Faute d'un meilleur mot, ceux-ci sont appelés « fils de pipeline ». Le thread pipeline devient un thread matériel lorsqu’il est en phase d’exécution d’un cycle d’instruction.
Comme vous pouvez le voir, nous obtenons une sortie de calcul à chaque cycle à partir de t2. Auparavant, nous obtenions une sortie de calcul tous les 3 cycles. Le pipeline améliore le débit de calcul. C'est l'une des techniques permettant de gérer les goulots d'étranglement de traitement dans l'architecture Von Neumann. Il existe également d'autres optimisations comme l'exécution dans le désordre, la prédiction de branchement, l'exécution spéculative, etc.,
Hyper-Threading
C'est le dernier concept que je souhaite aborder en matière de CPU avant de conclure et de passer aux GPU. À mesure que les vitesses d’horloge augmentaient, les processeurs devenaient également plus rapides et plus efficaces. Avec l'augmentation de la complexité des applications (jeu d'instructions), les cœurs de calcul du processeur étaient sous-utilisés et il passait plus de temps à attendre l'accès à la mémoire.
Nous constatons donc un goulot d’étranglement de mémoire. L'unité de calcul consacre du temps à l'accès à la mémoire et n'effectue aucun travail utile. La mémoire est plusieurs fois plus lente que le processeur et l’écart ne va pas se combler de si tôt. L'idée était d'augmenter la bande passante mémoire dans certaines unités d'un seul cœur de processeur et de garder les données prêtes à être utilisées par les unités de calcul lorsqu'elles sont en attente d'accès à la mémoire.
L'hyper-threading a été rendu disponible en 2002 par Intel dans les processeurs Xeon et Pentium 4. Avant l’hyper-threading, il n’y avait qu’un seul thread matériel par cœur. Avec l'hyper-threading, il y aura 2 threads matériels par cœur. Qu'est-ce que ça veut dire? Circuit de traitement en double pour certains registres, compteur de programme, unité de récupération, unité de décodage, etc.
Le diagramme ci-dessus montre simplement les nouveaux éléments de circuit dans un cœur de processeur avec hyperthreading. C'est ainsi qu'un seul cœur physique est visible sous forme de 2 cœurs pour le système d'exploitation. Si vous aviez un processeur à 4 cœurs, avec l'hyper-threading activé, il est considéré par le système d'exploitation comme 8 cœurs . La taille du cache L1 - L3 augmentera pour accueillir des registres supplémentaires. Notez que les unités d'exécution sont partagées.
Supposons que nous ayons des processus P1 et P2 faisant a=b+c, d=e+f, ceux-ci peuvent être exécutés simultanément dans un seul cycle d'horloge grâce aux threads matériels 1 et 2. Avec un seul thread matériel, comme nous l'avons vu précédemment, cela ne serait pas possible. Ici, nous augmentons la bande passante mémoire au sein d'un cœur en ajoutant Hardware Thread afin que l'unité de traitement puisse être utilisée efficacement. Cela améliore la simultanéité de calcul.
Quelques scénarios intéressants :
- Le processeur n'a qu'un seul ALU entier. Un HW Thread 1 ou HW Thread 2 doit attendre un cycle d'horloge et procéder au calcul au cycle suivant.
- Le processeur a une ALU entière et une ALU à virgule flottante. HW Thread 1 et HW Thread 2 peuvent effectuer des additions simultanément en utilisant respectivement ALU et FPU.
- Toutes les ALU disponibles sont utilisées par HW Thread 1. HW Thread 2 doit attendre que l'ALU soit disponible. (Ne s'applique pas à l'exemple d'ajout ci-dessus, mais peut se produire avec d'autres instructions).
Pourquoi le processeur est-il si performant dans l'informatique de bureau/serveur traditionnelle ?
- Vitesses d'horloge élevées – Supérieures aux vitesses d'horloge du GPU. En combinant cette vitesse élevée avec le pipeline d’instructions, les processeurs sont extrêmement efficaces pour les tâches séquentielles. Optimisé pour la latence.
- Diverses applications et besoins de calcul – Les ordinateurs personnels et les serveurs ont un large éventail d’applications et de besoins de calcul. Il en résulte un jeu d’instructions complexe. Le processeur doit être bon dans plusieurs domaines.
- Multitâche et multitraitement – Avec autant d'applications sur nos ordinateurs, la charge de travail du processeur nécessite un changement de contexte. Les systèmes de mise en cache et l'accès à la mémoire sont configurés pour prendre en charge cela. Lorsqu'un processus est planifié dans le thread matériel du processeur, il dispose de toutes les données nécessaires et exécute rapidement les instructions de calcul une par une.
Inconvénients du processeur
Consultez cet et essayez également le . Il montre comment la multiplication matricielle est une tâche parallélisable et comment des cœurs de calcul parallèles peuvent accélérer le calcul.
- Extrêmement bon pour les tâches séquentielles mais pas bon pour les tâches parallèles.
- Jeu d'instructions complexe et modèle d'accès à la mémoire complexe.
- Le processeur dépense également beaucoup d'énergie pour le changement de contexte et les activités de l'unité de contrôle en plus du calcul.
Points clés à retenir
- Le pipeline d’instructions améliore le débit de calcul.
- L’augmentation de la bande passante mémoire améliore la simultanéité de calcul.
- Les processeurs sont efficaces pour les tâches séquentielles (optimisées pour la latence). Pas bon pour les tâches massivement parallèles car il nécessite un grand nombre d'unités de calcul et de threads matériels qui ne sont pas disponibles (non optimisés pour le débit). Ceux-ci ne sont pas disponibles car les processeurs sont conçus pour l’informatique à usage général et disposent de jeux d’instructions complexes.
GPU
À mesure que la puissance de calcul augmentait, la demande en matière de traitement graphique augmentait également. Des tâches telles que le rendu de l'interface utilisateur et les jeux nécessitent des opérations parallèles, ce qui nécessite de nombreux ALU et FPU au niveau du circuit. Les processeurs, conçus pour des tâches séquentielles, ne pouvaient pas gérer efficacement ces charges de travail parallèles. Ainsi, les GPU ont été développés pour répondre à la demande de traitement parallèle dans les tâches graphiques, ouvrant ensuite la voie à leur adoption pour accélérer les algorithmes d’apprentissage en profondeur.
Je recommande fortement :
- Regarder cette qui explique les tâches parallèles impliquées dans le rendu d'un jeu vidéo.
- Lisez cet pour comprendre les tâches parallèles impliquées dans un transformateur. Il existe d'autres architectures d'apprentissage en profondeur comme les CNN et les RNN. Étant donné que les LLM conquièrent le monde, une compréhension de haut niveau du parallélisme dans les multiplications matricielles requises pour les tâches de transformateur établirait un bon contexte pour le reste de cet article. (Plus tard, je prévois de bien comprendre les transformateurs et de partager un aperçu de haut niveau de ce qui se passe dans les couches de transformateurs d'un petit modèle GPT.)
Exemples de spécifications CPU et GPU
Les cœurs, les threads matériels, la vitesse d'horloge, la bande passante mémoire et la mémoire sur puce des CPU et GPU diffèrent considérablement. Exemple:
- L'Intel Xeon 8280 :
- 2700 MHz en base et 4000 MHz en Turbo
- 28 cœurs et 56 threads matériels
- Filetages globaux du pipeline : 896 - 56
- Cache L3 : 38,5 Mo (partagé par tous les cœurs) Cache L2 : 28,0 Mo (réparti entre les cœurs) Cache L1 : 1,375 Mo (réparti entre les cœurs)
- La taille du registre n'est pas accessible au public
- Mémoire maximale : 1 To DDR4, 2 933 MHz, 6 canaux
- Bande passante mémoire maximale : 131 Go/s
- Performances maximales du FP64 = 4,0 GHz 2 unités AVX-512 8 opérations par unité AVX-512 par cycle d'horloge * 28 cœurs = ~ 2,8 TFLOP [Dérivé en utilisant : Performances maximales du FP64 = (fréquence turbo maximale) (nombre d'unités AVX-512) ( Opérations par unité AVX-512 par cycle d'horloge) * (Nombre de cœurs)]
Ce nombre est utilisé à des fins de comparaison avec le GPU, car l'obtention de performances maximales en informatique à usage général est très subjective. Ce nombre est une limite maximale théorique, ce qui signifie que les circuits FP64 sont utilisés au maximum.
- Nvidia A100 80 Go SXM :
- 1065 MHz en base et 1410 MHz en Turbo
- 108 SM, 64 cœurs FP32 CUDA (également appelés SP) par SM, 4 cœurs Tensor FP64 par SM, 68 threads matériels (64 + 4) par SM
- Globalement par GPU : 6 912 64 cœurs FP32 CUDA, 432 cœurs Tensor FP 64, 7 344 (6912 + 432) threads matériels
- Filetages de pipeline par SM : 2048 - 68 = 1980 par SM
- Threads de pipeline globaux par GPU : (2 048 x 108) - (68 x 108) = 21 184 - 7 344 = 13 840
- Référez-vous :
- Cache L2 : 40 Mo (partagé entre tous les SM) Cache L1 : 20,3 Mo au total (192 Ko par SM)
- Taille du registre : 27,8 Mo (256 Ko par SM)
- Mémoire principale maximale du GPU : 80 Go HBM2e, 1 512 MHz
- Bande passante maximale de la mémoire principale du GPU : 2,39 To/s
- Performances maximales du FP64 = 19,5 TFLOP [en utilisant uniquement tous les cœurs Tensor FP64]. La valeur inférieure de 9,7 TFLOP lorsque seul le FP64 dans les cœurs CUDA est utilisé. Ce nombre est une limite maximale théorique, ce qui signifie que les circuits FP64 sont utilisés au maximum.
Cœur dans un GPU moderne
Les terminologies que nous avons vues dans le domaine des CPU ne se traduisent pas toujours directement par les GPU. Ici, nous verrons les composants et le GPU NVIDIA A100 de base. Une chose qui m'a surpris lors de mes recherches pour cet article était que les fournisseurs de processeurs ne publient pas le nombre d'ALU, de FPU, etc. disponibles dans les unités d'exécution d'un cœur. NVIDIA est très transparent sur le nombre de cœurs et le framework CUDA offre une flexibilité et un accès complets au niveau du circuit.
Dans le diagramme ci-dessus dans GPU, nous pouvons voir qu'il n'y a pas de cache L3, un cache L2 plus petit, une unité de contrôle et un cache L1 plus petits mais beaucoup plus et un grand nombre d'unités de traitement.
Voici les composants GPU dans les diagrammes ci-dessus et leur équivalent CPU pour notre première compréhension. Je n'ai pas fait de programmation CUDA, donc le comparer avec les équivalents CPU aide à une première compréhension. Les programmeurs CUDA le comprennent très bien.
- Multiprocesseurs de streaming multiples <> CPU multicœur
- Multiprocesseur de streaming (SM) <> Cœur du processeur
- Processeur de streaming (SP)/ CUDA Core <> ALU / FPU en unités d'exécution d'un CPU Core
- Tensor Core (capable d'effectuer des opérations 4x4 FP64 sur une seule instruction) <> Unités d'exécution SIMD dans un cœur de processeur moderne (par exemple : AVX-512)
- Thread matériel (effectuer le calcul dans CUDA ou Tensor Cores en un seul cycle d'horloge) <> Thread matériel (effectuer le calcul dans les unités d'exécution [ALU, FPU, etc.] dans un seul cycle d'horloge)
- Mémoire HBM / VRAM / DRAM / GPU <> RAM
- Mémoire sur puce/SRAM (registres, cache L1, L2) <> Mémoire sur puce/SRAM (registres, cache L1, L2, L3)
- Remarque : Les registres dans un SM sont nettement plus grands que les registres dans un noyau. En raison du nombre élevé de threads. Rappelons qu'en hyper-threading dans CPU, nous avons constaté une augmentation du nombre de registres mais pas d'unités de calcul. Même principe ici.
Déplacement des données et de la bande passante mémoire
Les tâches graphiques et d'apprentissage profond nécessitent une exécution de type SIM(D/T) [Single instruction multi data/thread]. c'est-à-dire lire et travailler sur de grandes quantités de données pour une seule instruction.
Nous avons discuté du pipeline d’instructions et de l’hyper-threading dans les CPU et les GPU ont également des capacités. La manière dont il est mis en œuvre et fonctionne est légèrement différente mais les principes sont les mêmes.
Contrairement aux processeurs, les GPU (via CUDA) fournissent un accès direct aux Pipeline Threads (récupération des données de la mémoire et utilisation de la bande passante mémoire). Les planificateurs GPU fonctionnent d'abord en essayant de remplir les unités de calcul (y compris le cache L1 partagé et les registres associés pour stocker les opérandes de calcul), puis les « threads de pipeline » qui récupèrent les données dans les registres et HBM. Encore une fois, je tiens à souligner que les programmeurs d'applications CPU n'y pensent pas et que les spécifications concernant les "threads de pipeline" et le nombre d'unités de calcul par cœur ne sont pas publiées. Nvidia non seulement les publie, mais offre également un contrôle complet aux programmeurs.
J'entrerai plus en détail à ce sujet dans un article dédié au modèle de programmation CUDA et au "batching" dans la technique d'optimisation du service de modèle où nous pouvons voir à quel point cela est bénéfique.
Le diagramme ci-dessus représente l'exécution des threads matériels dans le cœur du CPU et du GPU. Reportez-vous à la section « Accès à la mémoire » dont nous avons parlé plus tôt dans Pipelining CPU. Ce diagramme le montre. La gestion complexe de la mémoire des processeurs rend ce temps d'attente suffisamment petit (quelques cycles d'horloge) pour récupérer les données du cache L1 vers les registres. Lorsque les données doivent être récupérées depuis L3 ou la mémoire principale, l'autre thread pour lequel les données sont déjà dans le registre (nous l'avons vu dans la section hyper-threading) prend le contrôle des unités d'exécution.
Dans les GPU, en raison du surabonnement (nombre élevé de threads et de registres de pipeline) et d'un jeu d'instructions simple, une grande quantité de données est déjà disponible sur les registres en attente d'exécution. Ces threads de pipeline en attente d'exécution deviennent des threads matériels et effectuent l'exécution aussi souvent qu'à chaque cycle d'horloge, car les threads de pipeline dans les GPU sont légers.
Bande passante, intensité de calcul et latence
Qu'y a-t-il de plus que le but ?
- Utilisez pleinement les ressources matérielles (unités de calcul) à chaque cycle d’horloge pour tirer le meilleur parti du GPU.
- Pour occuper les unités de calcul, nous devons lui fournir suffisamment de données.
C'est la principale raison pour laquelle la latence de multiplication matricielle de matrices plus petites est plus ou moins la même dans le CPU et le GPU. .
Les tâches doivent être suffisamment parallèles, les données doivent être suffisamment volumineuses pour saturer les FLOP de calcul et la bande passante mémoire. Si une seule tâche n'est pas assez importante, plusieurs de ces tâches doivent être regroupées pour saturer la mémoire et le calcul afin d'utiliser pleinement le matériel.
Intensité de calcul = FLOPs / Bande passante . c'est-à-dire le rapport entre la quantité de travail pouvant être effectuée par les unités de calcul par seconde et la quantité de données pouvant être fournies par la mémoire par seconde.
Dans le diagramme ci-dessus, nous voyons que l'intensité de calcul augmente à mesure que nous passons à une latence plus élevée et à une mémoire à bande passante plus faible. Nous voulons que ce nombre soit aussi petit que possible afin que le calcul soit pleinement utilisé. Pour cela, nous devons conserver autant de données dans L1/Registres afin que le calcul puisse être effectué rapidement. Si nous récupérons des données uniques à partir de HBM, il n'y a que quelques opérations où nous effectuons 100 opérations sur des données uniques pour que cela en vaille la peine. Si nous n’effectuons pas 100 opérations, les unités de calcul resteraient inactives. C’est là qu’un grand nombre de threads et de registres dans les GPU entrent en jeu. Conserver autant de données dans L1/Registres pour maintenir l’intensité de calcul faible et garder les cœurs parallèles occupés.
Il existe une différence d'intensité de calcul de 4X entre les cœurs CUDA et Tensor, car les cœurs CUDA ne peuvent effectuer qu'un seul MMA 1x1 FP64, alors que les cœurs Tensor peuvent exécuter 4x4 instructions FP64 MMA par cycle d'horloge.
Points clés à retenir
Nombre élevé d'unités de calcul (cœurs CUDA et Tensor), nombre élevé de threads et de registres (sur abonnement), jeu d'instructions réduit, pas de cache L3, HBM (SRAM), modèle d'accès mémoire simple et à haut débit (par rapport aux CPU - changement de contexte , mise en cache multicouche, pagination mémoire, TLB, etc.) sont les principes qui rendent les GPU bien meilleurs que les CPU en informatique parallèle (rendu graphique, apprentissage profond, etc.)
Au-delà des GPU
Les GPU ont d'abord été créés pour gérer les tâches de traitement graphique. Les chercheurs en IA ont commencé à tirer parti de CUDA et de son accès direct à un puissant traitement parallèle via les cœurs CUDA. Le GPU NVIDIA dispose de moteurs de traitement de texture, de traçage de rayons, de raster, de polymorphe, etc. (disons des jeux d'instructions spécifiques aux graphiques). Avec l'adoption croissante de l'IA, des cœurs Tensor bons pour le calcul matriciel 4x4 (instruction MMA) sont ajoutés et sont dédiés à l'apprentissage en profondeur.
Depuis 2017, NVIDIA augmente le nombre de cœurs Tensor dans chaque architecture. Mais ces GPU sont également performants en matière de traitement graphique. Bien que le jeu d'instructions et la complexité soient bien moindres dans les GPU, ils ne sont pas entièrement dédiés à l'apprentissage profond (en particulier l'architecture Transformer).
, une optimisation de la couche logicielle (sympathie mécanique pour le modèle d'accès à la mémoire de la couche d'attention) pour l'architecture du transformateur permet une accélération de 2 fois les tâches.
Grâce à notre compréhension approfondie des processeurs et des GPU, basée sur les premiers principes, nous pouvons comprendre la nécessité des accélérateurs de transformateur : une puce dédiée (circuit uniquement pour les opérations de transformateur), avec un nombre encore plus important d'unités de calcul pour le parallélisme, un jeu d'instructions réduit, non Caches L1/L2, DRAM massive (registres) remplaçant HBM, unités de mémoire optimisées pour le modèle d'accès mémoire de l'architecture du transformateur. Après tout, les LLM sont de nouveaux compagnons pour les humains (après le Web et le mobile) et ils ont besoin de puces dédiées pour plus d'efficacité et de performances.
Quelques accélérateurs d'IA :
Accélérateurs de transformateur :
Accélérateurs de transformateurs basés sur FPGA :
Les références:
- Comment fonctionnent les graphiques de jeux vidéo ? -
- CPU contre GPU contre TPU contre DPU contre QPU -
- Comment fonctionne le calcul GPU | CGV 2021 | Stephen Jones -
- Intensité de calcul -
- Comment fonctionne la programmation CUDA | CGV automne 2022 | Stephen Jones -
- Pourquoi utiliser le GPU avec les réseaux de neurones ? -
- Matériel CUDA | Tom Nurkkala | Conférence de l'Université Taylor -
L O A D I N G
. . . comments & more!
. . . comments & more!



